4. 共通設定
4.1. AIRead ControlPanelで設定
以下のプログラムを起動することで、AIRead ControlPanel(以下ControlPanel)にて共通設定ファイルを編集することができます。
<AIReadインストールフォルダ>/ControlPanel/AIReadControlPanel.exe
共通設定ファイル名は以下の通りです。
Standard (座標指定) :AIRead_setting.ini
Enterprise(キーワード指定 / キーワード指定(手書き文字あり)):AIRead_setting_kw.ini
(キーワード指定(表検出付き)):AIRead_setting_whole.ini
共通設定ファイルには“項目名=値”の書式で定義されます。
共通設定ファイルはUTF-8で保存する必要があります。
4.1.1. 基本設定
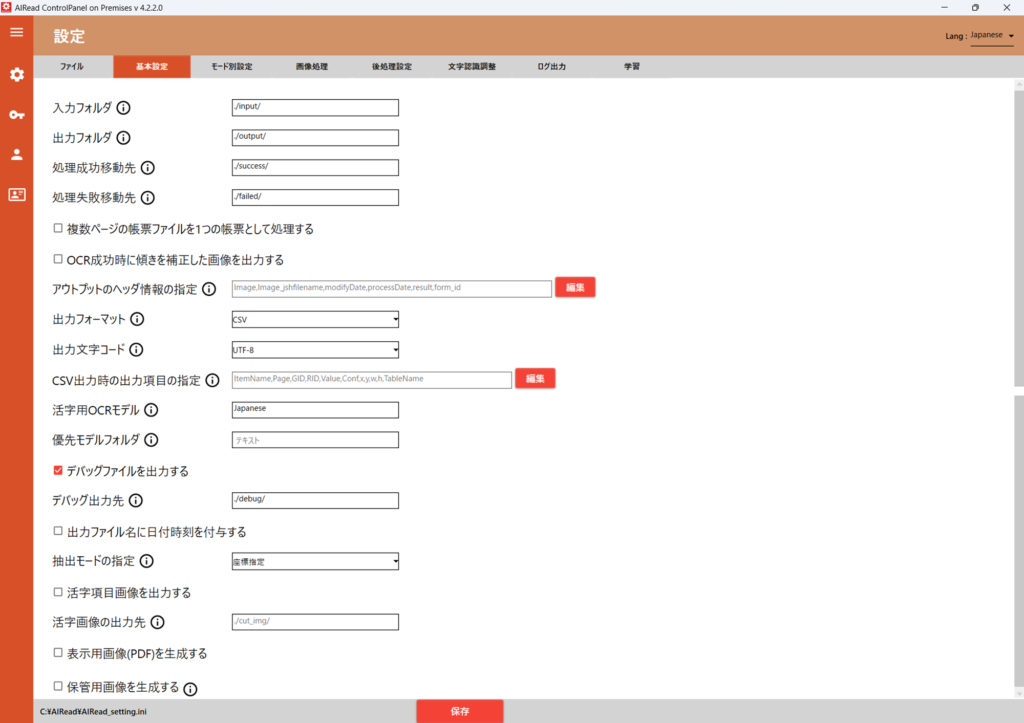
ファイルの入出力や抽出モードに関わる設定を行います。
| No. | 内容 | 項目名 | 書式 | 説明 |
|---|---|---|---|---|
| 1 | 入力フォルダ | INPUT | 文字列 | 画像を取り込むフォルダパス |
| 2 | 出力フォルダ | OUTPUT | 文字列 | OCR結果を出力するフォルダパス |
| 3 | 処理成功移動先 | MOVE_SUCCESS_DIR | 文字列 | OCR処理に成功した画像を格納するフォルダパス |
| 4 | 処理失敗移動先 | MOVE_FAILED_DIR | 文字列 | OCR処理に失敗した画像を格納するフォルダパス |
| 5 | 複数ページの帳票ファイルを1つの帳票として処理する | FILE_IDENFICATION_TYPE | 0, 1 | 帳票を識別する単位 ・チェックなし(0):ページ単位で帳票を識別して処理する ・チェックあり(1):1ページ目で帳票を識別し、1ファイルすべてのページを1つの帳票として処理する CORRECT_MOVED_FILE がtrueかつ、MOVED_FILE_FORMAT の出力形式がJPEGのとき、複数のJPEGを出力する |
| 6 | OCR成功時に傾きを補正した画像を出力する | CORRECT_MOVED_FILE | true, false | チェック(true)の時、OCR成功時に成功フォルダ(MOVE_SUCCESS_DIR)に移動する画像を天地・傾き補正後画像にする (位置合わせ補正は行われない) |
| 7 | 補正した画像の形式 | MOVED_FILE_FORMAT | PDF, JPEG | CORRECT_MOVED_FILE が true の時に出力する画像のフォーマットを指定する (デフォルト JPEG) <以下はEnterpriseのみ> 「複数ページの帳票ファイルを1つの帳票として処理する」を指定している場合は常にPDF出力となる |
| 8 | アウトプットヘッダ情報の指定 | HEADER_ITEM | 文字列 | アウトプットファイルへ出力するヘッダ情報の項目とその順番を指定可能 ※各項目の説明は6.1 共通を参照 |
| 9 | 出力フォーマット | OUTPUT_FORMAT | CSV XML CSV4DB XMLWAGBY SIMPLE_CSV SIMPLE_SEPARATE_CSV SIMPLE_TXT SIMPLE_SEPARATE_TXT | OCR読取結果の出力形式を選択する <Standard/Enterprise共通> ・CSV ・XML <Standardのみ> ・CSV4DB(DB連携のしやすいCSVフォーマット) ・XMLWAGBY(Wagbyフォーマット) <Standard全文OCRのみ> ・SIMPLE_CSV (画像の見た目に近い出力) ・SIMPLE_SEPARATE_CSV (画像の見た目に近い出力、表ごとに1つのCSVを出力) ・SIMPLE_TXT (SIMPLE_CSVのタブ区切りになったもの) ・SIMPLE_SEPARATE_TXT (SIMPLE_SEPARATE_CSVのタブ区切りになったもの) ※SIMPLE_CSV(TXT)・SIMPLE_SEPARATE_CSV(TXT)については4.4.4 表検出付全文OCRを参照 |
| 10 | 出力文字コード | OUTPUT_ENCODING | UTF-8 Shift_JIS EUC-JP UTF-8with BOM | 出力ファイルの文字コードを選択する (出力フォーマットがCSV、CSV4DBの場合) |
| 11 | CSV出力時の出力項目の指定 | CSV_COLUMN_ITEM | 文字列 | CSVへ出力する項目とその順番を指定可能。 ※各出力項目の説明は6.2 CSVを参照 |
| 12 | 活字用OCRモデル | OCR_LANG | 文字列 | 活字OCRエンジンで利用するモデル名 OCRモデルフォルダに存在するファイルの拡張子".traineddata"を除外したファイル名を指定する 例)Japanese.traineddata → Japanese |
| 13 | 優先モデルフォルダ | PRIORITY_MODEL_PATH | 文字列 | 優先モデルフォルダとして指定するフォルダパス ※モデルは下記のフォルダ構成で配置すること※ [優先モデルフォルダ]\tessdata\[任意のモデル] 指定したフォルダ内のモデルを優先して使用し、指定されたモデルが存在しない場合、共通のモデルフォルダから使用する 個別設定と組み合わせることで、帳票ごとに優先モデルと共通モデルの使い分けができる |
| 14 | デバッグファイルを出力する | IS_DEBUG | true, false | チェック(true)の時、DEBUG_PATHで設定されたフォルダへデバッグ情報を出力する |
| 15 | デバッグ出力先 | DEBUG_PATH | 文字列 | デバッグファイルを出力するフォルダパス |
| 16 | 出力ファイル名に日付時刻を付与する | MOVED_FILE_NAME | 0,1 | チェック(1)の時、抽出処理完了後の出力ファイル名に日付時刻を付与する |
| 17 | 抽出モードの設定 | COMPONENT_LEVEL | MANUAL ITEM CELL HW_ITEM | 抽出モードを選択する ・MANUAL : 座標指定 ・ITEM : キーワード指定 ・CELL : キーワード指定(表検出付き) ・HW_ITEM: キーワード指定(手書き文字あり) ※全文OCR時はキーワード指定・キーワード指定(表検出付き)を選択 ※キーワード指定(表検出付き)の詳細については4.4.4 表検出付全文OCRを参照 ※キーワード指定(手書き文字あり)を指定する場合は、all_model が必須 オンプレミスインストールマニュアルを参照 |
| 18 | セル内の改行に付与する文字 | LINE_SEPARATER | SPACE LF NONE | <キーワード指定(表検出付き)のみ> 認識されたセル中の文字列が改行されていた場合、行間に付与する文字を指定する 改行コードを指定した場合、LF(\n)が付与される |
| 19 | 活字項目画像を出力する | CREATE_PR_COMP_IMAGE | true, false | チェック(true)の時、活字として読み取った範囲の切取画像を出力する (デフォルト false) |
| 20 | 活字画像の出力先 | PR_CUT_IMAGE_DIR | 文字列 | 活字項目画像を出力するフォルダパス |
| 21 | 表示用画像(PDF)を生成する | CREATE_DISPLAY_IMAGE | true, false | チェック(true)の時、データサイズを減らしたPDFを生成する 天地補正・傾き補正後(位置合わせ無し)の画像がPDFに埋め込まれる 入力ファイルが複数ページの場合、FILE_IDENFICATION_TYPEに関係なく複数ページのPDFを生成する |
| 22 | 表示用画像の出力フォルダ | DISPLAY_IMAGE_DIR | 文字列 | 生成した表示用PDFを出力するフォルダパス (デフォルト:指定なし、表示用画像(PDF)を生成する が有効のとき指定必須) |
| 23 | 表示用画像の品質 | DISPLAY_IMAGE_QUALITY | 1~100 | 生成する表示用PDFの品質を指定する 指定した値が低いほど画像品質は下がるが、データサイズも小さくなる (デフォルト 65) |
| 24 | 保管用画像を生成する | CREATE_PRESERVATION_IMAGE | true, false | チェック(true)の時、電子帳票保存法向けに保管用の画像を生成する |
| 25 | 保管用画像出力フォルダ | PRESERVATION_IMAGE_DIR | 文字列 | 生成した電子帳票保存法向けの保管用画像を出力するフォルダパス (デフォルト:指定なし、保管用画像を生成する が有効のとき指定必須) 「<」「>」「*」「?」「"」「|」「半角スペース」は使用不可 使用されていた場合は、自動的に除去される 任意の文字列以外に以下のタグも使用可能 <date>:システム日付(年月日の数字8桁 yyyymmdd) <time>:システム時間(時間秒ミリ秒の数字11桁 hhmmssfffff) <year>:システム日付(西暦の数字4桁 yyyy) <month>:システム日付(月の数字2桁 mm) <day>:システム日付(日付の数字2桁 dd) |
| 26 | 保管用画像のファイル名 | PRESERVATION_IMAGE_NAME | 文字列 | 生成される電子帳票保存法向けの保管用画像のファイル名を指定する 「<」「>」「¥」「/」「:」「*」「?」「"」「|」「半角スペース」は使用不可 任意の文字列以外に以下のタグも使用可能 <date>:システム日付(年月日の数字8桁 yyyymmdd) <time>:システム時間(時間秒ミリ秒の数字11桁 hhmmssfffff) <year>:システム日付(西暦の数字4桁 yyyy) <month>:システム日付(月の数字2桁 mm) <day>:システム日付(日付の数字2桁 dd) <inputfile>:読み取った対象のファイルから拡張子を除いた文字列 <item:項目名>:読み取りを行った際に、使用された帳票定義で指定されている項目名 (例えば、帳票定義で company_name と定義し、OCRにより実際の帳票から「アライズイノベーション株式会社」という文字列が取得されたとする。 この場合、保管用画像のファイル名の <item:company_name> の部分が「アライズイノベーション株式会社」に置換される) |
4.1.2. モード別設定
モード別(座標指定、キーワード指定)のパラメータを設定します。
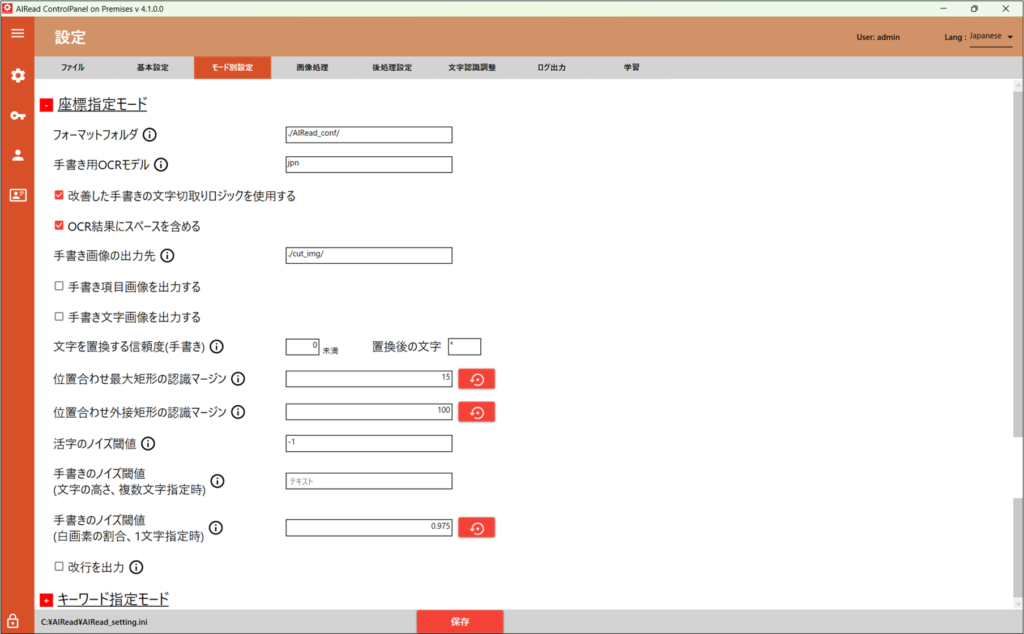
4.1.2.1. 座標指定モード
<Standardのみ>
座標指定OCRを実行時の設定はこちらで行います。
| No. | 内容 | 項目名 | 書式 | 説明 |
|---|---|---|---|---|
| 1 | フォーマットフォルダ | PROFILE_CONFIG_DIR | 文字列 | <Standardのみ> フォーマット定義フォルダのパス |
| 2 | 手書き用OCRモデル | HAND_WRITE_OCR_LANG | 文字列 | 指定された手書きモデルが存在しないときに使用するモデル名 "OCR_MODEL_PATH/tessdata/"以下に存在するフォルダ名 例)jpn |
| 3 | 改善した手書きの文字切り取りロジックを使用する | USE_SEGMENT_MODEL | true, false | フリーピッチで複数行の手書き文字を読み取る場合はチェック(true)する ※処理時間がチェックをしない場合と比べて1.5~2.5倍ほど増加する |
| 4 | OCR結果にスペースを含める | EXPORT_SPACE | true, false | チェック(true)の時、OCR結果にスペースを含める (活字読み取り時のみ) |
| 5 | 手書き画像の出力先 | HW_CUT_IMAGE_DIR | 文字列 | 手書き項目/文字画像を出力するフォルダパス |
| 6 | 手書き項目画像を出力する | CREATE_HW_COMP_IMAGE | true, false | チェック(true)の時、手書きで座標指定した範囲の切取画像を出力する |
| 7 | 手書き文字画像を出力する | CREATE_HW_CHAR_IMAGE | true, false | チェック(true)の時、手書きで座標指定した範囲内の文字単位の切取画像を出力する |
| 8 | 文字を置換する信頼度(手書き) | HW_REPLACE_THRESH | 0~100 | 手書きの項目が指定された閾値未満の信頼度の時、任意の文字に変換する |
| 9 | 置換後の文字 | HW_REPLACE_CHAR | 文字列 | No. 8(HW_REPLACE_THRESH)で変換する文字(1文字) |
| 10 | 位置合わせ最大矩形の認識マージン | FORMAT_MARGIN | 0以上 | 位置合わせ時に大きな矩形を認識しない画像端(上下左右)からの範囲を指定する 単位はピクセル (デフォルト 15) |
| 11 | 位置合わせ外接矩形の認識マージン | FIX_TEXT_HEIGHT | 0以上 | 位置合わせ時に外接矩形を認識しない画像端(上下左右)からの範囲を指定する 単位はピクセル (デフォルト 100) |
| 12 | 活字のノイズ閾値 | PRINT_NOISE_FILTERS | -1~100 | 活字の認識で、項目中の最大文字高さに対して指定された閾値以下の文字をノイズとして除去する 例) 30 を指定 → 読み取り範囲内の最大文字に対し30%以下の高さの文字をノイズとみなして除去する (デフォルト -1:本機能は動作しない) ※小さい文字や記号がノイズとして削除される可能性有り |
| 13 | 手書きノイズの閾値 (文字の高さ、複数文字指定時) | HW_NOISE_FILTERS | 文字列 | 手書き文字の認識で指定したモデルについて、項目中の最大文字高さに対して任意の割合以下の文字をノイズとして除去する 手書き文字の文字数を「複数」で設定した項目を対象とする [モデル名]:[閾値(%)]の形式で記載する カンマ区切りで複数指定可能 例) number:25,money:30 → 数値モデルは25%、通貨モデルは30%の高さの文字をノイズとみなして除去する ※小さい文字や記号がノイズとして削除される可能性があります |
| 14 | 手書きノイズの閾値 (白画素の割合、1文字指定時) | HW_WHITE_THRESHOLD | 0~1.0 | 手書き項目に1文字指定をしているとき、 その項目画像を読取対象外(ノイズ)と判断する白ピクセルの割合と判断する閾値を指定する 例) 0.99 を指定 → 手書き項目が1文字指定のとき、項目内の白ピクセルの割合が99%以上であれば、項目内の記載をノイズと判断して除去する (デフォルト 0.975) |
| 15 | 改行を出力する | RECOGNIZE_NEWLINE | true, false | チェック(true)の時、読み取り項目内の改行を認識して\nとして出力する |
4.1.2.2. キーワード指定モード
<Enterpriseのみ>
キーワード指定実行時の設定はこちらで行います。
<Standard/Enterprise共通>
全文OCRを実行時の一部の設定もこちらで行います。
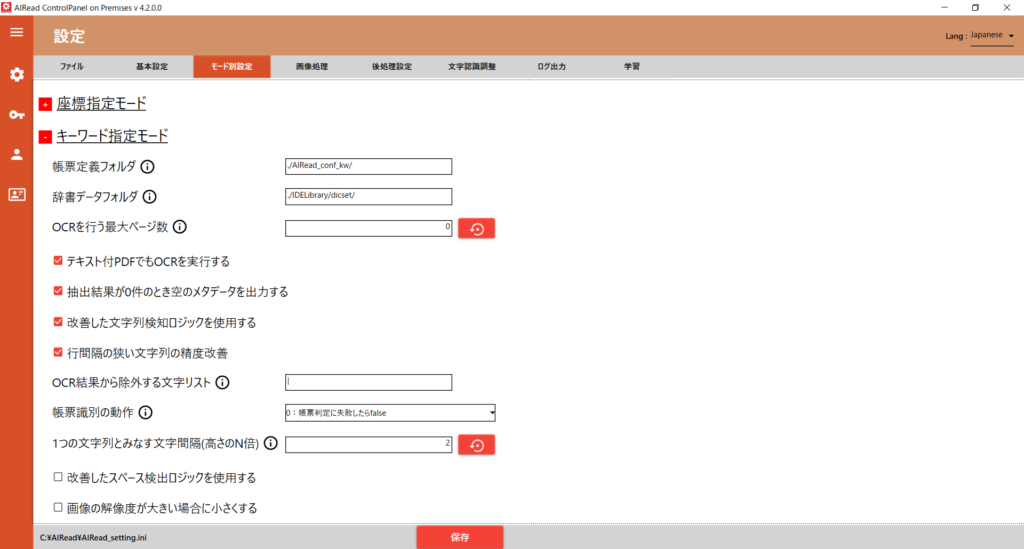
| No. | 内容 | 項目名 | 書式 | 説明 |
|---|---|---|---|---|
| 1 | 帳票定義フォルダ | PROFILE_KWCONFIG_DIR | 文字列 | 帳票定義フォルダのファイルパス |
| 2 | 辞書データフォルダ | IDE_DIR | 文字列 | IDELibraryフォルダのパス “?”区切りで文書種別を指定可能 ※「帳票識別(DEFAULT_PROFILE_MODE)」が 1 or 2 の場合に有効 例) ./IDELibrary/dicset/?Invoice |
| 3 | OCRを行う最大ページ数 | PROC_MAX_PAGE | 0以上の整数 | OCRを実行する最大ページ枚数 例) MAX_PAGE=1 → 2ページ目以降は無視する 0の場合は全ページが対象 |
| 4 | テキスト付きPDFでもOCRを実行する | OCR_PDF_WITH_TEXT | true, false | チェックあり(true):テキスト付きPDFの場合でもOCRを実行する チェックなし(false):PDFのテキスト情報を使用して抽出する |
| 5 | テキスト付PDFの文字高さ情報にフォント高さを使用する | USE_PDF_TEXT_FONT_HEIGHT | true, false | チェックあり(true):セル内にあるテキスト情報が複数ある場合、結合して出力されるよう補正する チェックなし(false):従来のテキスト分割で出力する |
| 6 | 抽出結果が0件のとき空のメタデータを出力する | LAYOUT_TYPE | 0, 1 | 0:空のメタデータは出力しない 1:空のメタデータを出力する ※明細は空の場合出力しない |
| 7 | 改善した文字列検知ロジックを使用する | USE_DL_STRING_DETECTION | true, false | <キーワード指定、キーワード指定(表検出付き)のみ指定> チェック(true)の時、従来のOCRよりも文字列検知の改善した処理を行う ※メモリの使用量が約500MB程度増加し、処理時間がA4画像1枚当たり5秒/枚ほど増加する ※文字列検知の処理が従来のものと変更となるため、読み取り結果に影響する可能性有り |
| 8 | 行間隔が狭い文字列の精度改善 | STRING_DETECTION_SPLIT_LARGE_RECTANGLE | true, false | チェックあり(true):行間隔の狭い文字列に対して、改善した文字検知を行う チェックなし(false):従来の文字検知のまま処理を行う |
| 9 | OCR結果から除外する文字リスト | BLACK_LIST_EXT | 文字列 | 抽出処理時にキーワードおよび抽出する値から除外する文字を指定する |
| 10 | 帳票識別の動作 | DEFAULT_PROFILE_MODE | 0~2 | 帳票識別の動作を指定する 0:帳票識別に失敗したらfalse 1:帳票識別に失敗したら、指定した文書種別定義で抽出 2:指定した文書種別定義で抽出(帳票識別なし) 例) IDE_DIRへ”?”区切りで記載する 例)IDE_DIR=./dicset/?invoice |
| 11 | 文字種別 | 指定したい文字種別定義名 | 文字列 | 帳票種別の動作が、1もしくは2のときのみ設定可能 指定したい文字種別定義を指定する |
| 12 | 1つの文字列とみなす文字間隔(高さのN倍) | LINKED_ITEM_THRESHOLD | 数値 | 1つの文字列とみなす文字の間隔を設定 値は文字の大きさ(高さ)に対する倍率 |
| 13 | 改善したスペース検出ロジックを使用する | SPACE_MODE | 0,1 | 0:スペース検知の改善した検出を行う 1:従来のスペース認識機能を使用する |
| 14 | 画像の解像度が大きい場合に小さくする | REDUCE_IMAGE_BEFORE_OCR | true, false | チェックあり(true):画像の解像度が大きいとき(長辺が5000ピクセル以上)解像度を小さくしてからOCRを行う チェックなし(false):解像度を変えずそのままOCRを行う |
4.1.3. 画像処理
文字認識の前に実施する画像処理関連の設定を変更します。

| No. | 内容 | 項目名 | 書式 | 説明 |
|---|---|---|---|---|
| 1 | 傾き補正を行う | IS_SLOPE_CORRECTION | true, false | チェック(true)の時、文字認識前に傾き補正を行う(35度まで) |
| 2 | 回転補正を行う | AUTO_ROTATION | true, false | チェック(true)の時、文字認識前に90/180/270度の画像回転補正を行う |
| 3 | 直線除去を行う最短の長さ | LINE_REMOVAL_THRESHOLD | 0以上の整数 | 直線とみなす長さのしきい値(ピクセル) 0の場合、文字の大きさから自動で設定する |
| 4 | 直線除去時の文字高さに対する倍率 | LINE_REMOVAL_MULTIPLE_BY_TEXT_HEGHT | 0.1以上の数値 | 指定した値×文字高さの平均(ピクセル)が直線除去の対象となる 直線除去を行う最短の長さ の値が0の場合にのみ動作する |
| 5 | 点線除去を行う最短の長さ | HOUGH_THRESHOLD | 0以上の整数 | 点線とみなす長さのしきい値(ピクセル) |
| 6 | 点線の間隔(横) | ERODE_W | 0以上の整数 | 横の点線として検知する点の間隔の値(ピクセル) 点と点の間隔が広い場合は大きい値を設定する (デフォルト 12) |
| 7 | 点線の間隔(縦) | ERODE_H | 0以上の整数 | 縦の点線として検知する点の間隔の値(ピクセル) 点と点の間隔が広い場合は大きい値を設定する (デフォルト 7) |
| 8 | 罫線除去で欠けてしまった文字の復元処理を行う | RESTORE_TEXT | true, false | チェック(true)の時、罫線除去時に欠けてしまう罫線と隣接した文字を復元する ※必ず復元できるわけではない ※副作用として文字にノイズがつく場合がある |
| 9 | 二値化の閾値 | THRESH_VALUE | 0~255 | 文字認識前の画像の二値化(白黒化)のしきい値 0の場合、画像全体のヒストグラムから自動で設定する 詳細は4.4.1. 二値化の閾値を参照 |
| 10 | 直線除去時の二値化の閾値 | BINTHRESH_ON_LINE_REMOVAL | 0~255 | 直線除去時の二値化パラメータのしきい値 0の場合、画像全体のヒストグラムから自動で設定する |
| 11 | 短い罫線(横)除去の閾値 | SHORT_LINE_THRESH_H | -1以上 | 長い罫線に接している短い罫線(横)を検知・除去する閾値 罫線の長さ(ピクセル)を指定する -1 : 除去を行わない 0 : 除去を行わない(-1と同じ) 1以上 : この値を直線検知の閾値とする |
| 12 | 短い罫線(縦)除去の閾値 | SHORT_LINE_THRESH_V | -1以上 | 長い罫線に接している短い罫線(縦)を検知・除去する閾値 罫線の長さ(ピクセル)を指定する -1 : 除去を行わない 0 : 除去を行わない(-1と同じ) 1以上 : この値を直線検知の閾値とする |
| 13 | 短い点線も除去する | USE_SHORT_DOTLINE_REMOVAL | true, false | チェック(true)の時、短い罫線除去時に点線も除去対象とする ※処理時間がA4画像1枚当たり2秒ほど増加する ※文字が除去される副作用が発生する可能性がある |
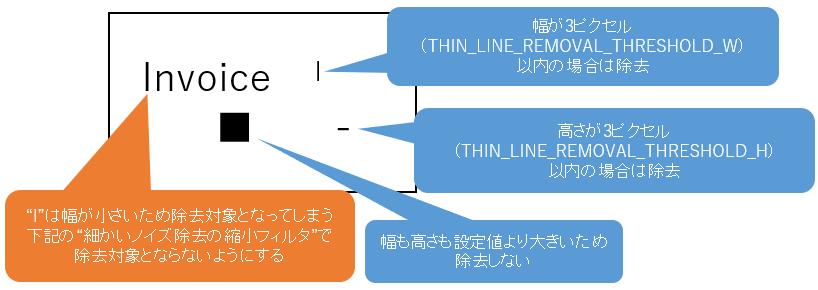
| 14 | 細かいノイズ除去の閾値(幅) | THIN_LINE_REMOVAL_THRESHOLD_W | 0以上 | 指定した幅(ピクセル)より細かいノイズを除去する 値が大きいほど大きなサイズのノイズを除去する (デフォルト 0、推奨値 3) 詳細は4.4.2. 細かいノイズ除去を参照 |
| 15 | 細かいノイズ除去の閾値(高さ) | THIN_LINE_REMOVAL_THRESHOLD_H | 0以上 | 指定した高さ(ピクセル)より細かいノイズを除去する 値が大きいほど大きなサイズのノイズを除去する (デフォルト 0、推奨値 3) 詳細は4.4.2. 細かいノイズ除去を参照 |
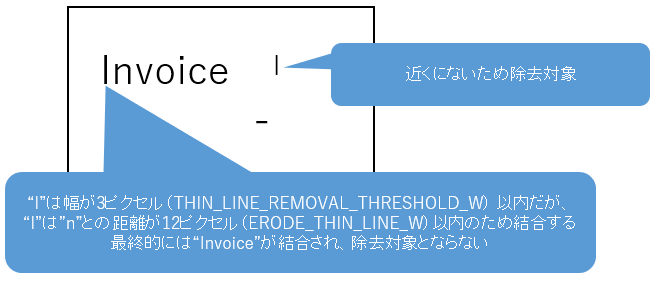
| 16 | 細かいノイズ除去の縮小フィルタ(幅) | ERODE_THIN_LINE_W | 1以上 | 細かいノイズ除去の収縮処理のフィルターサイズ(幅) 値が大きいとより独立したノイズのみ除去する (デフォルト 12) 詳細は4.4.2. 細かいノイズ除去を参照 |
| 17 | 細かいノイズ除去の縮小フィルタ(高さ) | ERODE_THIN_LINE_H | 1以上 | 細かいノイズ除去の収縮処理のフィルターサイズ(高さ) 値が大きいとより独立したノイズのみ除去する (デフォルト 7) 詳細は4.4.2. 細かいノイズ除去を参照 |
| 18 | TIFFを300DPIに変換してからOCRを実行する | CONV_TIFF_DPI | true, false | チェック(true)の時、TIFFを300DPIに変換してからOCRを実行する TIFFで縦横のDPIが異なる場合に指定する |
| 19 | 抽出する色 | EXTRACTION_COLORS | 文字列 | 抽出する色を指定する(指定した色以外を除去する) 複数色を指定する場合はカンマ区切りで記載する 例) EXTRACTION_COLORS=K,R 指定可能な色 ・K(黒) ・R(赤) ・Y(黄) ・G(緑) ・C(シアン) ・B(青) ・P(紫) 個別で指定する場合は、直接数値を指定 詳細は4.4.5. 色の抽出・除去を参照 |
| 20 | 除去する色 | REMOVAL_COLORS | 文字列 | 除去する色を指定する 指定方法は色抽出(EXTRACTION_COLORS)と同様 抽出する色と両方指定した場合は抽出を優先する 詳細は4.4.5. 色の抽出・除去を参照 |
| 21 | 色抽出・除去を罫線除去の前に行う | FILTER_COLOR_BEFORE_LINEREMOVAL | true, false | チェック(true)の時、罫線除去の前に色抽出・除去を行う |
| 22 | 罫線を延長する長さ | LINE_EXTENSION_LEN | 0以上 | 検知した罫線を延長する 単位はピクセル (デフォルト 0) |
| 23 | 矩形の丸い角を除去する閾値 | ROUNDED_CORNER_THRESHOLD | 0~100 | 半径が指定した値未満の丸い角を除去する 単位はピクセル 0の場合は除去されない (デフォルト 0) 詳細は4.4.3. 丸い角の除去を参照 |
| 24 | 丸い角の除去範囲を拡張する長さ | ROUNDED_CORNER_PADDING | 0~100 | 丸い角を除去する際に、指定した値分の除去範囲を拡大する 単位はピクセル (デフォルト 10) 詳細は4.4.3. 丸い角の除去を参照 |
| 25 | ドットの除去(背景・点線)を行う | REMOVE_DOT | true, false | チェック(true)の時、ドットの除去(背景、点線)を行う (デフォルト false) |
| 26 | 除去したいドットの幅 | DOTLINE_SIZE_W | 0以上の整数 | 削除したい背景や点線のドットのサイズの幅をピクセルで指定する (デフォルト 3) |
| 27 | 除去したいドットの高さ | DOTLINE_SIZE_H | 0以上の整数 | 削除したい背景や点線のドットのサイズの高さをピクセルで指定する (デフォルト 3) |
| 28 | 罫線/点線削除の前にドットを削除 | REMOVE_DOT_BEFORE_LINE | true/false | チェック(true)の時、罫線/点線削除の前にドットを削除する (デフォルト true) |
| 29 | 小さい矩形を削除 | REMOVE_SMALL_RECTANGLES | true, false | チェック(true)の時、小さい矩形の除去を行う |
| 30 | 除去する矩形の最小面積 | REMOVE_RECTANGLE_MIN_AREA_ THRESHOLD | 0以上の整数 | 「小さい矩形を削除除去する」がチェック(true)の時に除去する矩形の最小面積を指定する |
| 31 | 除去する矩形の最大面積 | REMOVE_RECTANGLE_MAX_AREA_ THRESHOLD | 0以上の整数 | 「小さい矩形を削除除去する」がチェック(true)の時に除去する矩形の最大面積を指定する |
| 32 | 斜め線を除去 | REMOVE_DIAGONAL_LINES | true, false | チェック(true)の時、矩形内の斜めの線を除去する |

33~37のパラメータは普段は折り畳まれておりますが、全て表示を押下することで表示されるようになります。
※パラメータ増加に伴い、使用頻度の低いパラメータがデフォルトで非表示になっています。

| No. | 内容 | 項目名 | 書式 | 説明 |
|---|---|---|---|---|
| 33 | ノイズ除去を行う | DE_NOISE | true, false | ノイズ除去処理の有無 チェック(true)の時、文字認識前にノイズ除去を行う |
| 34 | 罫線除去を無効化する | SKIP_LINE_REMOVE | true, false | チェック(true)の時、文字認識前の罫線除去を無効化する(罫線除去は行わない) |
| 35 | 白黒反転処理を実施する黒の比率 | BLACK_WHITE_THRESHOLD | 0~100 | 二値化後に白黒を反転するしきい値(%) 設定した%より黒の割合が多い場合に白黒を反転する |
| 36 | シャープ補正値 | SHARPEN_VALUE | 0以上の少数 | OCR実行前に画像をシャープ化する 画像がぼやけている場合などに利用すると効果的 0の場合は処理しない |
| 37 | ドット背景除去を行う(旧) | REMOVE_DOTTED_BACKGROUND | true, false | チェック(true)の時、ドット背景除去を行う ※下位互換パラメータ |
4.1.4. 後処理設定
読み取り完了後に行う処理全般を設定します。
作成された個別読取結果変換リストと読み取り項目との紐づけは、RuleEditor/FormEditor から行います。
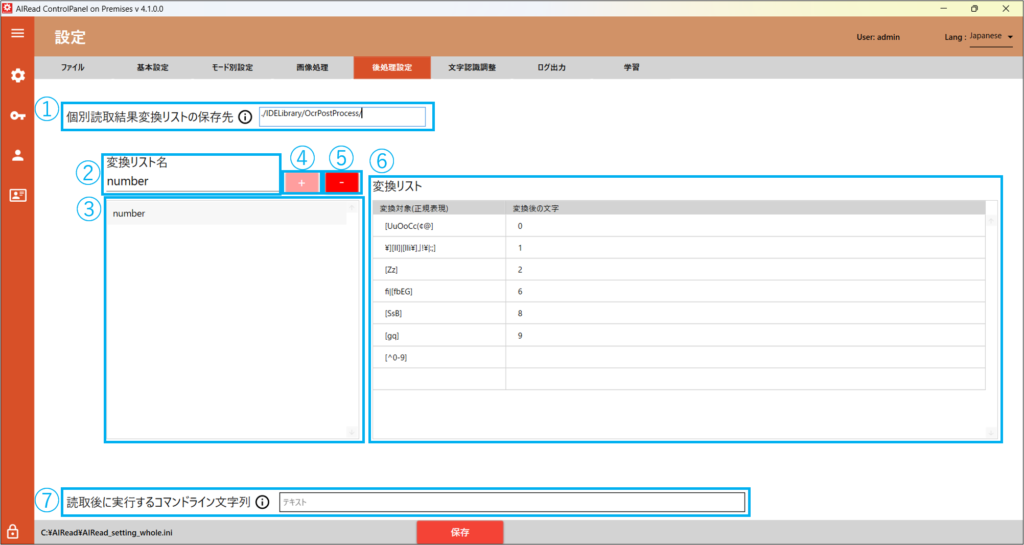
| No. | 項目名 | 説明 |
| 1 | 個別読取結果変換リストの保存先 | 個別読取結果変換設定ファイルの保存先を指定する デフォルトは、<AIREAD_HOME>\IDELibrary\OcrPostProcess |
| 2 | 変換リスト名 | 選択中の個別読取結果変換設定ファイルが表示される 個別読取結果変換設定ファイルを追加する場合は、変換リスト名に入力した名前で追加される |
| 3 | 変換リスト名一覧 | 作成済みの個別読取結果変換設定ファイルの一覧が表示される |
| 4 | 変換設定追加ボタン | 変換リストに入力した名称で個別読取結果変換設定ファイルを追加する 選択中の設定ファイル保存先に、同一の設定名の個別読取結果変換設定ファイルが存在する場合は追加不可 |
| 5 | 変換設定削除ボタン | 選択中の個別読取結果変換設定ファイルを削除する |
| 6 | 変換リスト | 選択中の後個別読取結果変換設定ファイルの設定情報を表示する |
| 7 | 読取後に実行するコマンドライン文字列 | 帳票の読み取り後に実行するコマンドライン文字列を設定する |
4.1.4.1. 変換リストの設定
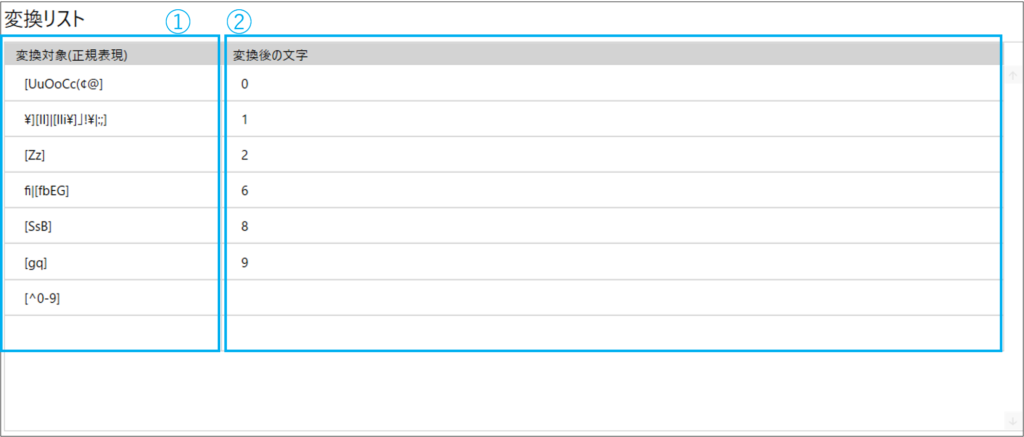
| No. | 項目名 | 説明 |
| 1 | 変換対象(正規表現) | 変換対象の文字を指定する 変換対象の文字は正規表現で記載する |
| 2 | 変換後の文字 | 変換対象の文字から変換する文字を指定する 変換後の文字は単語でも指定可能 |
4.1.4.2. 読取後に実行するコマンドライン文字列の設定
AIReadで帳票読み取りを行った後に、呼び出したいコマンドライン文字列を設定します。
| 例) 保管用画像を任意のフォルダへコピーするコマンド copy /y "%AIREAD_PRESERVATION_FILE%" "任意のフォルダパス" |
コマンドラインでは、AIRead独自の変数を使用することができます。
使用可能な変数と値については、下記を参照ください。
| No. | 環境変数名 | 内容 | 呼び出されるパスの例 |
|---|---|---|---|
| 1 | AIREAD_ORIG_INPUT_FILE | オリジナルの読取対象ファイルまでのフルパス | C:\AIRead\debug\original\sample.pdf |
| 2 | AIREAD_PRESERVATION_FILE | 保存用画像のファイルまでのフルパス ※基本設定タブで「保管用画像を生成する」が有効となっていることが前提 無効になっている場合は空文字列("")が設定される | C:\AIRead\preseve\20230320123456_アライズイノベーション_物品仕入れ_sample.pdf |
4.1.5. 文字認識調整
文字認識に関する設定を変更します。
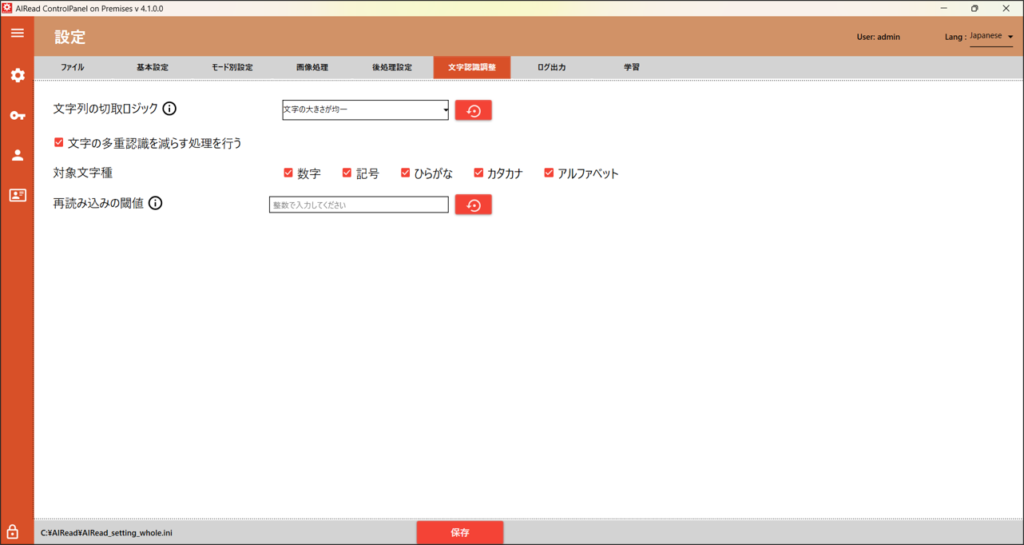
| No. | 内容 | 項目名 | 書式 | 説明 |
|---|---|---|---|---|
| 1 | 文字列の切取ロジック | PAGE_SEG_MODE | 4, 6 | OCRエンジンの活字文字検知/分割アルゴリズムを指定する ・4 : 1行内の文字サイズが可変とみなして文字を検知 ・6 : 1行内の文字サイズが固定とみなして文字を検知 |
| 2 | 文字の多重認識を減らす処理を行う | use_dup_char_reducer | true, false | 複数の同じ文字が連続で出力されてしまうとき、本設定を有効にすることで回避できる(活字のみ) ※文字間が近い場合、複数文字を1文字として出力してしまう副作用が起きる可能性がある ・チェックする(true) : 機能を有効にする ・チェックしない(false) : 機能を無効にする |
| 3 | 対象文字種 | reduce_target | 0~4 | 「文字の多重認識を減らす処理を行う(use_dup_char_reducer)」の対象となる文字種を指定する ・0 : 数字 ・1 : 記号 ・2 : ひらがな ・3 : カタカナ ・4 : アルファベット カンマ区切りで複数指定可能 |
| 4 | 再読み込みの閾値 | RESCAN_THRESHOLD | 0~100 | 指定した値よりもコンポーネントのConf値が閾値より低い場合に読み直す(活字のみ) ※コンポーネント内の文字のConf値の平均値 |
4.1.6. ログ出力
ログ出力に関する設定を変更します。
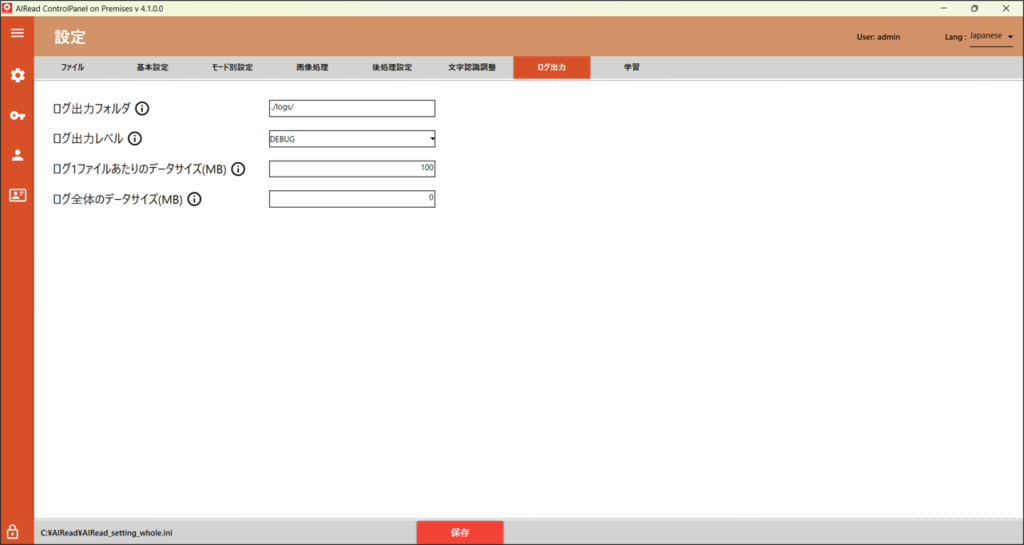
| No. | 内容 | 項目名 | 書式 | 説明 |
|---|---|---|---|---|
| 1 | ログ出力フォルダ | LOGS_PATH | 文字列 | 実行ログを出力するフォルダパス |
| 2 | ログ出力レベル | LOGS_LEVEL | 0~3 | 指定したレベルで以下の内容を出力する ・0 : DEBUG, INFO, WARNING, ERROR ・1 : INFO, WARNING, ERROR ・2 : WARNING, ERROR ・3 : ERROR |
| 3 | ログ1ファイルあたりの データサイズ | LOG_ROTATION_SIZE | 0~100 | ログ1ファイルあたりの最大サイズ(MB) 0 の場合、プロセス単位でログを出力する |
| 4 | ログ全体のデータサイズ | LOG_MAX_SIZE | 0以上の整数 | ログファイルを保存する最大容量(MB) 0 の場合、制限なし(削除しない) ※LOG_ROTATION_SIZEより大きい値を設定すること |
4.1.7.学習
教師データを作成するための設定を行います。
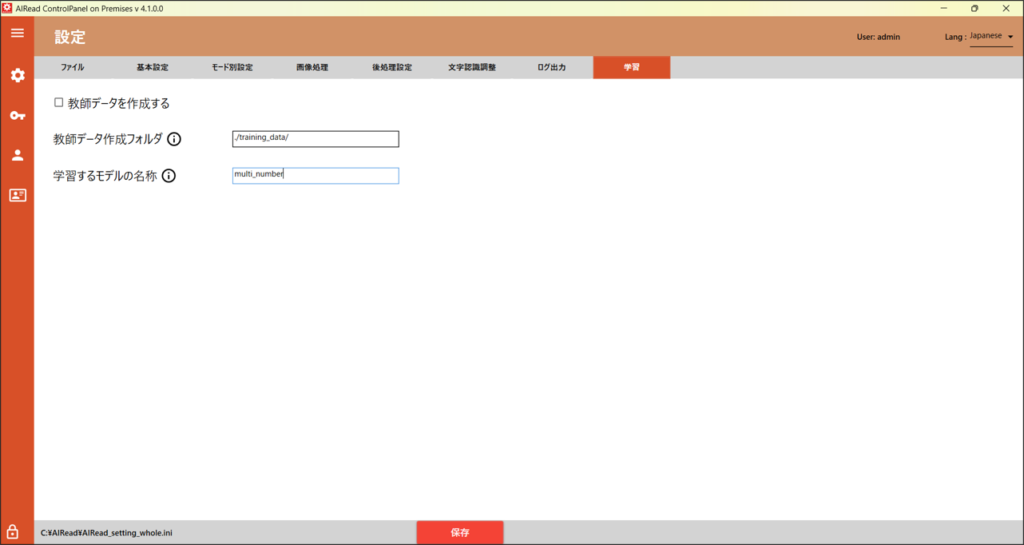
| No. | 内容 | 項目名 | 書式 | 説明 |
| 1 | 教師データを作成する | LEARNING_MODE | 1, 0 | 学習のための教師データを作成する ・チェックする(1) : 機能を有効にする ・チェックしない(0) : 機能を無効にする |
| 2 | 教師データ作成フォルダ | AUTO_LEARNING_DIR | 文字列 | 教師データを作成するフォルダ を指定する |
| 3 | 学習するモデルの名称 | AUTO_LEARNING_MODEL | 文字列 | 学習するモデル名を指定する 学習可能モデル(multi_number、multi_numeric、multi_katakana)が指定可能 |
4.1.8. ファイル
共通設定ファイルファイルの新規作成、保存の操作ができます。
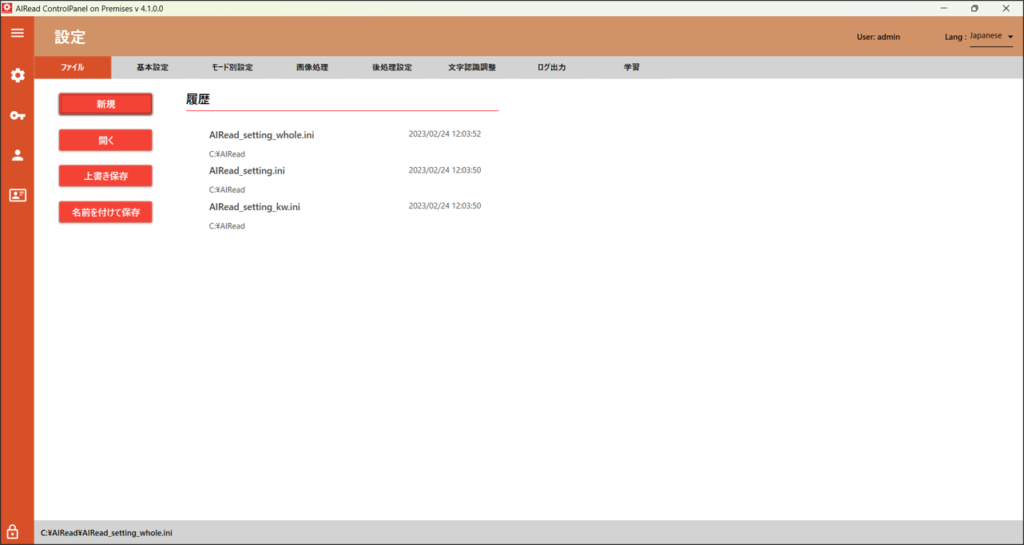
| No. | 項目名 | 説明 |
| 1 | 新規 | 新規で共通設定ファイルを作成する |
| 2 | 開く | 共通設定ファイルを指定して開く |
| 3 | 上書き保存 | 編集中の設定を上書き保存する |
| 4 | 名前を付けて保存 | 編集中の設定を別ファイルとして保存する |
| 5 | 履歴 | 過去に保存した共通設定ファイルの履歴を表示する 選択することで対象ファイルを編集できる |
4.2. 共通設定ファイルでのみ指定できる項目
| No. | 項目名 | 書式 | 説明 |
| 1 | AUTO_CROPS | true, false | trueの場合、周囲の余白を削除する |
| 2 | OCR_MODEL_PATH | 文字列 | OCRエンジンで利用するモデルのフォルダパス(tessdataが存在するフォルダ) |
| 3 | OCR_MODE | 1 | OCRエンジンのOCRアルゴリズムを指定する |
4.3. 項目/文字切り取り画像の出力
手書き項目画像を出力する機能が有効(CREATE_HW_COMP_IMAGE=true)、もしくは手書き文字画像を出力する機能が有効(CREATE_HW_CHAR_IMAGE=true)の際は、手書き画像の出力先(HW_CUT_IMAGE_DIR)の指定されたディレクトリにそれぞれの手書き画像を出力します。
?指定した出力先(HW_CUT_IMAGE_DIR)
├ ─ ─ ?char(手書きのみ)
│ ├ ? FileA.jpg_0_0.jpg
│ ├ ? FileA.jpg_0_1.jpg
│ ├ ? FileA.jpg_0_2.jpg
│ ├ ⁝
│ └ ? FileA.jpg_3_7.jpg
│
└ ─ ─ ?component(活字・手書き)
├ ? FileA.jpg_0.jpg
├ ? FileA.jpg_1.jpg
├ ? FileA.jpg_2.jpg
└ ? FileA.jpg_3.jpg
項目(component)画像の数字は、同一入力ファイル中の連番です。
文字(char)画像の数字は、ファイル名で紐づく、項目画像ごとの連番です。
4.4. ユースケース
4.4.1. 二値化の閾値
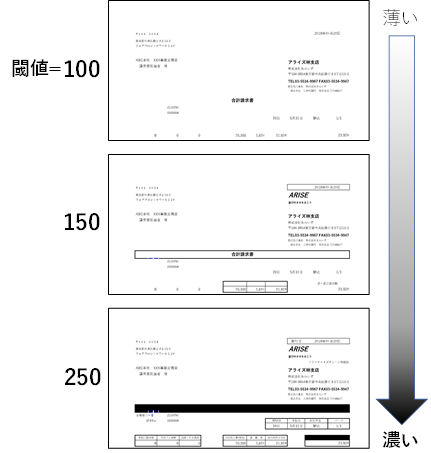
OCRは画像を白と黒だけに変換(二値化)した状態で行います。各ピクセルの明るさ(黒0~255白)に対して、黒と白の境界とする値が二値化の閾値です。閾値は0~255を設定します。
二値化の閾値が低いと元の画像で濃い色のみが二値化で黒くなり、高いと薄い色でも黒くなります。
また、閾値を0とした場合は画像全体の明るさを基に自動で閾値を判定します。それによって目的の文字が消えてしまうなどあった場合は閾値を直接調整してください。
二値化の閾値の設定によって、下記画像のように変化します。

4.4.2. 細かいノイズ除去
細かいノイズ除去の閾値では、除去対象とするノイズの幅・高さを指定します。
どちらかのパラメータの対象となる場合は除去対象となります。
| ControlPanel項目名 | 共通設定ファイル項目名 | 推奨値 |
|---|---|---|
| 細かいノイズ除去の閾値(幅) | THIN_LINE_REMOVAL_THRESHOLD_W | 3 |
| 細かいノイズ除去の閾値(高さ) | THIN_LINE_REMOVAL_THRESHOLD_H | 3 |
細かいノイズ除去の縮小フィルタは、近隣の文字・ノイズを結合して除去対象となるのを防ぎます。
結合する文字・ノイズ間の距離(ピクセル)を指定します。
| ControlPanel項目名 | 共通設定ファイル項目名 | 推奨値 |
|---|---|---|
| 細かいノイズ除去の縮小フィルタ(幅) | ERODE_THIN_LINE_W | 12 |
| 細かいノイズ除去の縮小フィルタ(高さ) | ERODE_THIN_LINE_H | 7 |
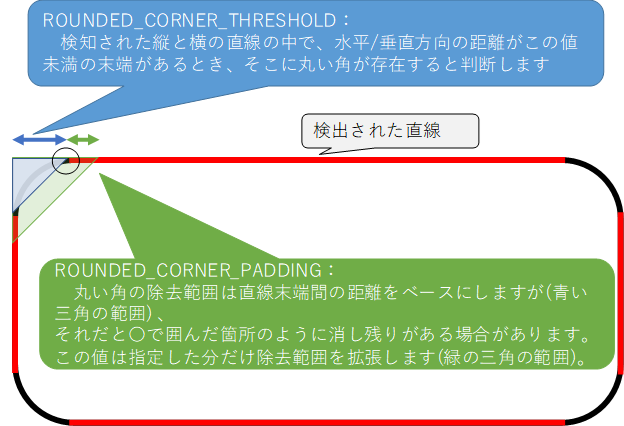
4.4.3. 丸い角の除去
帳票によっては丸い角の矩形が存在し、直線除去では角が残ってしまい誤読の原因となる場合があります。
そういった場合に、下記のパラメータを設定することで丸い角の除去を行います。
| ControlPanel項目名 | 共通設定ファイル項目名 | 推奨値 |
|---|---|---|
| 矩形の丸い角を除去する | ROUNDED_CORNER_THRESHOLD | 30 |
| 丸い角の除去範囲を拡張する長さ | ROUNDED_CORNER_PADDING | 10 |
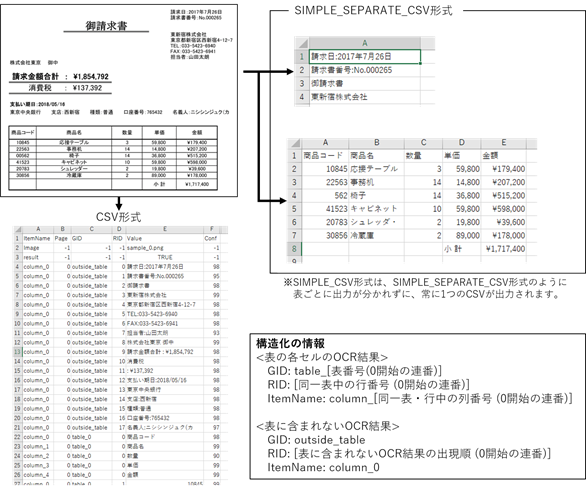
4.4.4. 表検出付全文OCR
コントロールパネルの抽出モードの設定で「キーワード指定(表検出付)」を指定した状態で全文OCRを実行すると、認識した罫線を基に表を検出し、表の各セルに対してOCRを行います。
この際、表の各セルのOCR結果は表の行・列の形に再現可能な情報が付与され構造化されます。ETL等で後続処理に表の情報を渡したい場合などにご利用ください。
なお、構造化情報の利用に応じて出力形式を選択可能です。
・付与された構造化情報含め出力したい場合: CSV形式
・構造化した表の形で出力したい場合: SIMPLE_CSV / SIMPLE_SEPARATE_CSV形式
※v2.3.1からタブ区切りのSIMPLE_TXT / SIMPLE_SEPARATE_TXT形式も追加されました
※表が段組みになっている場合には正しく構造化されません。
行と列が揃っている表にのみ有効です。
4.4.5. 色の抽出・除去
帳票上の印影や背景の色がOCRに影響し、正しく読み取りを行えない場合があります。
OCRを行う前に、必要な文字の色のみ抽出、もしくは余計な色の除去を行って調整します。
色の指定はHSV色空間で範囲指定します。
4.4.5.1. HSV色空間について
| 要素 | 指定範囲 | 説明 | |
|---|---|---|---|
| H | 色相 | 0~179 | 具体的な色を定義する要素 色が環状で表現するため、0°と179°で同じ色となる |
| S | 彩度 | 0~255 | 色相で定義された色の鮮やかさ・濃さを表す要素 彩度が255で最も鮮やかとなり、減少に合わせて色が薄くなり、0で灰色になる |
| V | 明度 | 0~255 | 色相で定義された色の明るさ・暗さを表す要素 明度が255で最も明るく(白)、明度の減少に合わせて暗くなり、0で黒になる |
4.4.5.2. 色の指定方法(GUI)
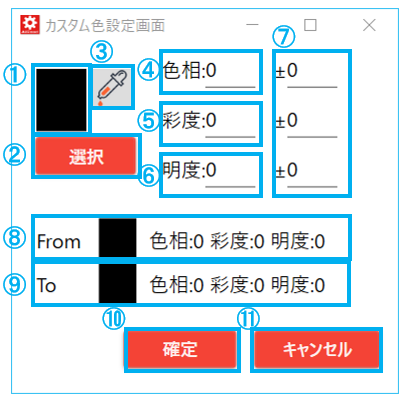
| No. | 項目名 | 説明 |
| 1 | 指定した色 | カラーパレット、もしくはスポイトで対象とした色が表示される |
| 2 | 色の選択ボタン | カラーパレットを開き、対象とする色を指定する |
| 3 | スポイトボタン | スポイト画面を開き、クリックした場所の色を抽出して対象とする |
| 4 | 色相 | 対象とした色の色相の表示、または色相を直接入力する |
| 5 | 彩度 | 対象とした色の彩度の表示、または彩度を直接入力する |
| 6 | 明度 | 対象とした色の明度の表示、または明度を直接入力する |
| 7 | ±(指定幅) | 対象とした色の色相、彩度、明度に対して、指定した数値分の幅を上下に持たせる 指定された数値分の幅は、from-to の範囲となる |
| 8 | 色の対象範囲(from) | 対象とした色から±で指定した数値分をマイナスして表示する |
| 9 | 色の対象範囲(to) | 対象とした色から±で指定した数値分をプラスして表示する |
| 10 | 確定ボタン | 指定した色の範囲をAIRead ContorlPanel に反映させる |
| 11 | キャンセルボタン | 編集内容を反映させずに、AIRead ContorlPanel へ戻る |
例)赤い色の範囲を指定する場合(GUI)

対象の色の値に対して幅を持たせることで、近い色も対象とすることができます。
4.4.5.3. 色の指定方法(テキスト)
テキストで設定を行う場合、対象としたい色の色相、彩度、明度の順で”:”(コロン)で区切り、色の指定を行います。
色相が0°、彩度、明度が200を指定する際は、下記の指定となります。
| 0 : 200 : 200 - 0 : 200 : 200 |
色相に前後の幅を持たせ、さらに明るい色も対象としたい場合は、下記のような指定を行います。
| -15 : 200 : 200 - 15 : 200 : 255 |
| 色相(-15 - 15) | 明度(200 - 255) |
| 0から±15の値 | 明度200より明るい色を取得するため、55プラスした値 |
※彩度を変更しない場合は、同じ値とします。
例)赤い色の範囲を指定する場合(テキスト)
純粋な赤色は、下記のように表現できます。
純粋な赤色の表現
| 0 : 255 : 255 |
実際は印刷等の条件により赤色の色合いは異なるため、範囲に幅を持たせることで色を対象とすることが可能です。
例)赤色を含むピンクからオレンジ色の範囲
| -10:180:250-10:220:255 |
※色相 -10 は 170 と同義