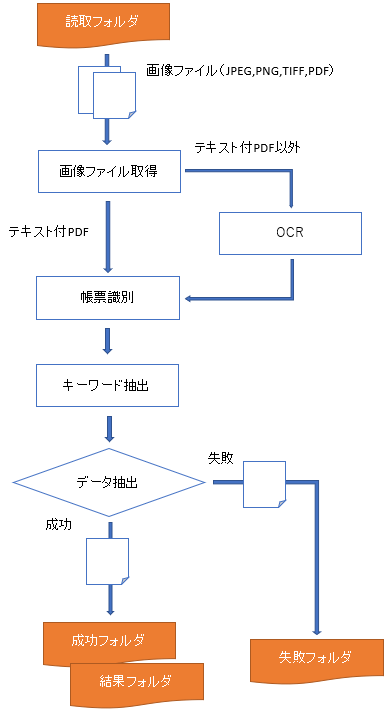
3. 共通設定 3.1. AIRead ControlPanelで設定 以下のプログラムを起動することで、AIRead ControlPanel(以下ControlPanel)にて共通設定ファイルを編集することができます。
<AIReadインストールフォルダ>/ControlPanel/AIReadControlPanel.exe
共通設定ファイル名は以下の通りです。
共通設定ファイルには“項目名=値”の書式で定義されます。
共通設定ファイルはUTF-8で保存する必要があります。
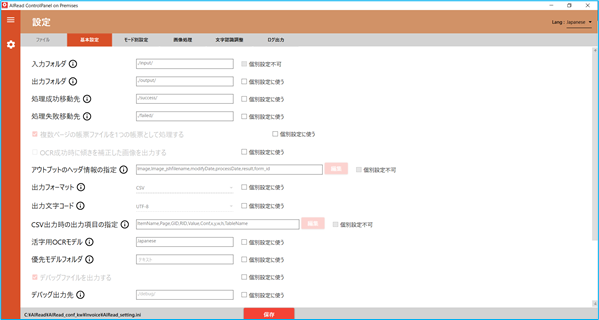
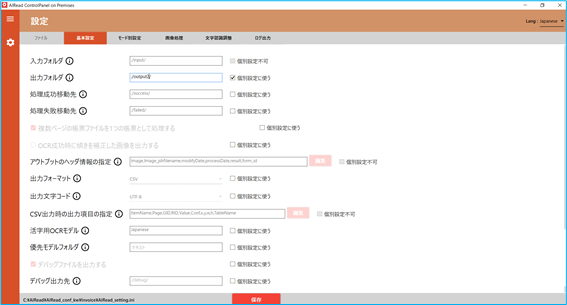
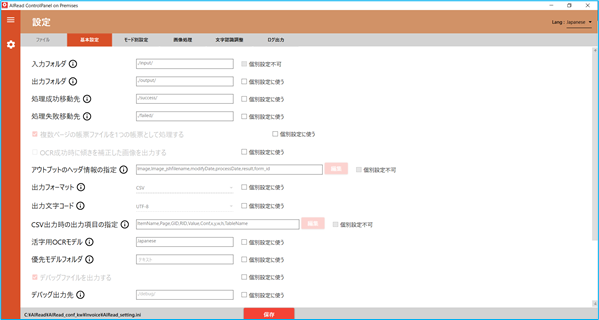
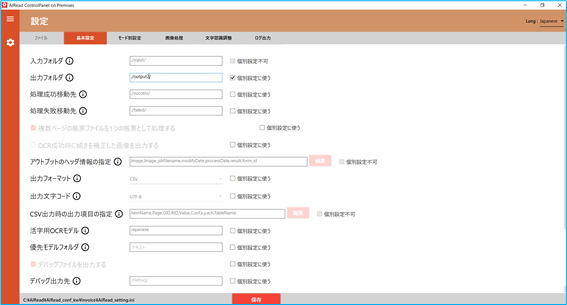
3.1.1. 基本設定
ファイルの入出力や抽出モードに関わる設定を行います。
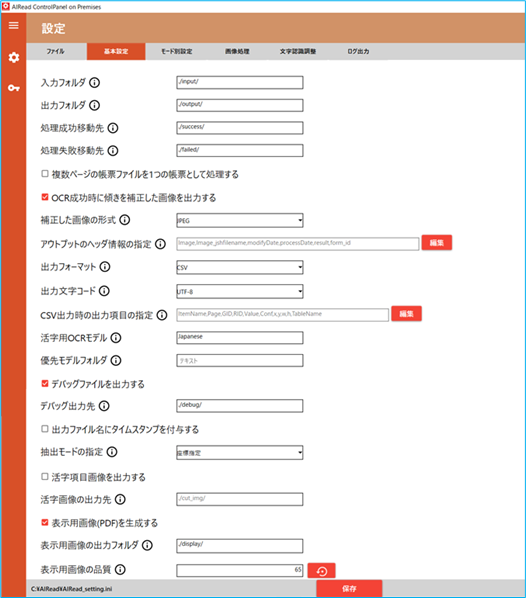
No. 内容 項目名 書式 説明 1 入力フォルダ INPUT 文字列 画像を取り込むフォルダパス 2 出力フォルダ OUTPUT 文字列 OCR結果を出力するフォルダパス 3 処理成功移動先 MOVE_SUCCESS_DIR 文字列 OCR処理に成功した画像を格納するフォルダパス 4 処理失敗移動先 MOVE_FAILED_DIR 文字列 OCR処理に失敗した画像を格納するフォルダパス 5 複数ページの帳票ファイルを1つの帳票として処理する FILE_IDENFICATION_TYPE 0, 1 帳票を識別する単位 6 OCR成功時に傾きを補正した画像を出力する CORRECT_MOVED_FILE true, false チェック(true)の時、OCR成功時に成功フォルダ(MOVE_SUCCESS_DIR)に移動する画像を天地・傾き補正後画像にする 7 補正した画像の形式 MOVED_FILE_FORMAT PDF, JPEG CORRECT_MOVED_FILE が true の時に出力する画像のフォーマットを指定する<以下はEnterpriseのみ> 8 アウトプットヘッダ情報の指定 HEADER_ITEM 文字列 アウトプットファイルへ出力するヘッダ情報の項目とその順番を指定可能5.1 共通 を参照 9 出力フォーマット OUTPUT_FORMAT CSV OCR読取結果の出力形式を選択する<Standard/Enterprise共通> <Standardのみ> <Standard全文OCRのみ> 3.4.4 表検出付全文OCR を参照 10 出力文字コード OUTPUT_ENCODING UTF-8 出力ファイルの文字コードを選択する 11 CSV出力時の出力項目の指定 CSV_COLUMN_ITEM 文字列 CSVへ出力する項目とその順番を指定可能。 ※各出力項目の説明は5.2 CSV を参照 12 活字用OCRモデル OCR_LANG 文字列 活字OCRエンジンで利用するモデル名 13 優先モデルフォルダ PRIORITY_MODEL_PATH 文字列 優先モデルフォルダとして指定するフォルダパスtessdata \[任意のモデル] 14 デバッグファイルを出力する IS_DEBUG true, false チェック(true)の時、DEBUG_PATHで設定されたフォルダへデバッグ情報を出力する 15 デバッグ出力先 DEBUG_PATH 文字列 デバッグファイルを出力するフォルダパス 16 出力ファイル名にタイムスタンプを付与する MOVED_FILE_NAME 0,1 チェック(1)の時、抽出処理完了後の出力ファイル名にタイムスタンプを付与する 17 抽出モードの設定 COMPONENT_LEVEL MANUAL 抽出モードを選択する3.4.4 表検出付全文OCR を参照 18 活字項目画像を出力する CREATE_PR_COMP_IMAGE true, false チェック(true)の時、活字として読み取った範囲の切取画像を出力する 19 活字画像の出力先 PR_CUT_IMAGE_DIR 文字列 活字項目画像を出力するフォルダパス 20 表示用画像(PDF)を生成する CREATE_DISPLAY_IMAGE true, false チェック(true)の時、データサイズを減らしたPDFを生成する 21 表示用画像の出力フォルダ DISPLAY_IMAGE_DIR 文字列 生成した表示用PDFを出力するフォルダパス 22 表示用画像の品質 DISPLAY_IMAGE_QUALITY 1~100 生成する表示用PDFの品質を指定する
3.1.2. モード別設定
モード別(座標指定、キーワード指定)のパラメータを設定します。
3.1.2.1. 座標指定モード
<Standardのみ>
No. 内容 項目名 書式 説明 1 フォーマットフォルダ PROFILE_CONFIG_DIR 文字列 <Standardのみ> 2 手書き用OCRモデル HAND_WRITE_OCR_LANG 文字列 指定された手書きモデルが存在しないときに使用するモデル名 3 改善した手書きの文字切り取りロジックを使用する USE_SEGMENT_MODEL true, false チェック(true)の時、従来よりも認識精度の高い1文字検知を使ったOCR処理を行う 4 OCR結果にスペースを含める EXPORT_SPACE true, false チェック(true)の時、OCR結果にスペースを含める 5 手書き画像の出力先 HW_CUT_IMAGE_DIR 文字列 手書き項目/文字画像を出力するフォルダパス 6 手書き項目画像を出力する CREATE_HW_COMP_IMAGE true, false チェック(true)の時、手書きで座標指定した範囲の切取画像を出力する 7 手書き文字画像を出力する CREATE_HW_CHAR_IMAGE true, false チェック(true)の時、手書きで座標指定した範囲内の文字単位の切取画像を出力する 8 文字を置換する信頼度(手書き) HW_REPLACE_THRESH 0~100 手書きの項目が指定された閾値未満の信頼度の時、任意の文字に変換する 9 置換後の文字 HW_REPLACE_CHAR 文字列 No. 8(HW_REPLACE_THRESH)で変換する文字(1文字) 10 位置合わせ矩形の認識マージン FORMAT_MARGIN 0以上 位置合わせ時に大きな矩形を認識しない画像端(上下左右)からの範囲を指定する 11 活字のノイズ閾値 PRINT_NOISE_FILTERS -1~100 活字の認識で、項目中の最大文字高さに対して指定された閾値以下の文字をノイズとして除去する 12 手書きノイズの閾値 (文字の高さ、複数文字指定時) HW_NOISE_FILTERS 文字列 手書き文字の認識で指定したモデルについて、項目中の最大文字高さに対して任意の割合以下の文字をノイズとして除去する 13 手書きノイズの閾値 (白画素の割合、1文字指定時) HW_WHITE_THRESHOLD 0~1.0 手書き項目に1文字指定をしているとき、 その項目画像を読取対象外(ノイズ)と判断する白ピクセルの割合と判断する閾値を指定する
3.1.2.2. キーワード指定モード
<Enterpriseのみ>
<Standard/Enterprise共通>
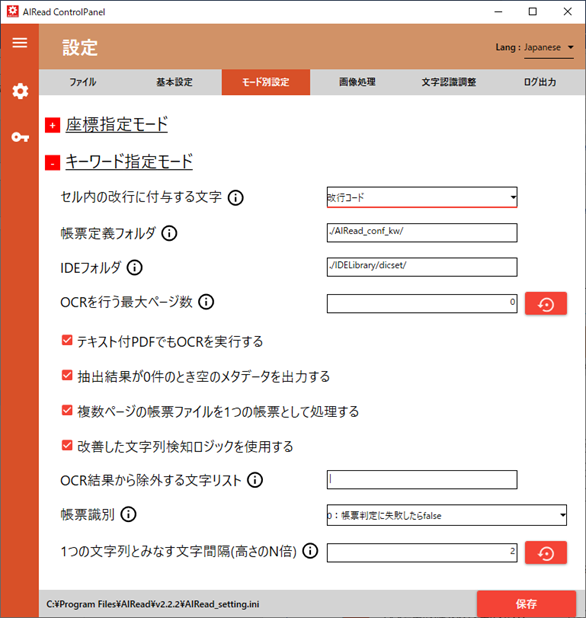
No. 内容 項目名 書式 説明 1 セル内の改行に付与する文字 LINE_SEPARATER SPACE <抽出モードの設定=キーワード指定(表検出付き)のみ指定> 2 帳票定義フォルダ PROFILE_KWCONFIG_DIR 文字列 <Enterpriseのみ> 3 IDEフォルダ IDE_DIR 文字列 <Enterpriseのみ> 4 OCRを行う最大ページ数 PROC_MAX_PAGE 0以上の整数 <Enterpriseのみ> 5 テキスト付きPDFでもOCRを実行する OCR_PDF_WITH_TEXT true, false <Enterpriseのみ> 6 抽出結果が0件のとき空のメタデータを出力する LAYOUT_TYPE 0, 1 <Enterpriseのみ> 7 改善した文字列検知ロジックを使用する USE_DL_STRING_DETECTION true, false チェック(true)の時、従来のOCRよりも文字列検知の改善した処理を行う 8 OCR結果から除外する文字リスト BLACK_LIST_EXT 文字列 <Enterpriseのみ> 9 帳票識別 DEFAULT_PROFILE_MODE 0~2 <Enterpriseのみ> 10 1つの文字列とみなす文字間隔 LINKED_ITEM_THRESHOLD 数値 <Enterpriseのみ>
3.1.3. 画像処理
文字認識の前に実施する画像処理関連の設定を変更します。
No. 内容 項目名 書式 説明 1 ノイズ除去を行う DE_NOISE true, false ノイズ除去処理の有無 2 傾き補正を行う IS_SLOPE_CORRECTION true, false チェック(true)の時、文字認識前に傾き補正を行う(35度まで) 3 回転補正を行う AUTO_ROTATION true, false チェック(true)の時、文字認識前に90/180/270度の画像回転補正を行う 4 罫線除去を無効化する SKIP_LINE_REMOVE true, false チェック(true)の時、文字認識前の罫線除去を無効化する(罫線除去は行わない) 5 直線除去を行う最短の長さ LINE_REMOVAL_THRESHOLD 0以上の整数 直線とみなす長さのしきい値(ピクセル) 6 点線除去を行う最短の長さ HOUGH_THRESHOLD 0以上の整数 点線とみなす長さのしきい値(ピクセル) 7 罫線除去で欠けてしまった文字の復元処理を行う RESTORE_TEXT true, false チェック(true)の時、罫線除去時に欠けてしまう罫線と隣接した文字を復元する 8 二値化の閾値 THRESH_VALUE 0~255 文字認識前の画像の二値化(白黒化)のしきい値3.4.1. 二値化の閾値 を参照 9 直線除去時の二値化の閾値 BINTHRESH_ON_LINE_REMOVAL 0~255 直線除去時の二値化パラメータのしきい値 10 白黒反転処理を実施する黒の比率 BLACK_WHITE_THRESHOLD 0~100 二値化後に白黒を反転するしきい値(%) 11 シャープ補正値 SHARPEN_VALUE 0以上の少数 OCR実行前に画像をシャープ化する 12 短い罫線(横)除去の閾値 SHORT_LINE_THRESH_H -1以上 長い罫線に接している短い罫線(横)を検知・除去する閾値 13 短い罫線(縦)除去の閾値 SHORT_LINE_THRESH_V -1以上 長い罫線に接している短い罫線(縦)を検知・除去する閾値 14 短い点線も除去する USE_SHORT_DOTLINE_REMOVAL true, false チェック(true)の時、短い罫線除去時に点線も除去対象とする 15 細かいノイズ除去の閾値(幅) THIN_LINE_REMOVAL_THRESHOLD_W 0以上 指定した幅(ピクセル)より細かいノイズを除去する3.4.2. 細かいノイズ除去 を参照 16 細かいノイズ除去の閾値(高さ) THIN_LINE_REMOVAL_THRESHOLD_H 0以上 指定した高さ(ピクセル)より細かいノイズを除去する3.4.2. 細かいノイズ除去 を参照 17 細かいノイズ除去の縮小フィルタ(幅) ERODE_THIN_LINE_W 1以上 細かいノイズ除去の収縮処理のフィルターサイズ(幅)3.4.2. 細かいノイズ除去 を参照 18 細かいノイズ除去の縮小フィルタ(高さ) ERODE_THIN_LINE_H 1以上 細かいノイズ除去の収縮処理のフィルターサイズ(高さ)3.4.2. 細かいノイズ除去 を参照 19 TIFFを300DPIに変換してからOCRを実行する CONV_TIFF_DPI true, false チェック(true)の時、TIFFを300DPIに変換してからOCRを実行する 20 抽出する色 EXTRACTION_COLORS 文字列 抽出する色を指定する(指定した色以外を除去する)3.4.5. 色の抽出・除去 を参照 21 除去する色 REMOVAL_COLORS 文字列 除去する色を指定する抽出する色と両方指定した場合は抽出を優先する 3.4.5. 色の抽出・除去 を参照 22 色抽出・除去を罫線除去の前に行う FILTER_COLOR_BEFORE_LINEREMOVAL true, false チェック(true)の時、罫線除去の前に色抽出・除去を行う 23 罫線を延長する長さ LINE_EXTENSION_LEN 0以上 検知した罫線を延長する 24 矩形の丸い角を除去する閾値 ROUNDED_CORNER_THRESHOLD 0~100 半径が指定した値未満の丸い角を除去する3.4.3. 丸い角の除去 を参照 25 丸い角の除去範囲を拡張する長さ ROUNDED_CORNER_PADDING 0~100 丸い角を除去する際に、指定した値分の除去範囲を拡大する3.4.3. 丸い角の除去 を参照
3.1.4. 文字認識調整
文字認識に関する設定を変更します。
No. 内容 項目名 書式 説明 1 文字列の切取ロジック PAGE_SEG_MODE 4, 6 OCRエンジンの活字文字検知/分割アルゴリズムを指定する 2 大きい文字の認識補正処理を行う USE_LARGE_TEXT_DETECTION true, false <Enterpriseのみ> 3 文字の多重認識を減らす処理を行う use_dup_char_reducer true, false 複数の同じ文字が連続で出力されてしまうとき、本設定を有効にすることで回避できる(活字のみ) 4 対象文字種 reduce_target 0~4 「文字の多重認識を減らす処理を行う(use_dup_char_reducer)」の対象となる文字種を指定する 5 再読み込みの閾値 RESCAN_THRESHOLD 0~100 指定した値よりもコンポーネントのConf値が閾値より低い場合に読み直す(活字のみ)
3.1.5. ログ出力
ログ出力に関する設定を変更します。
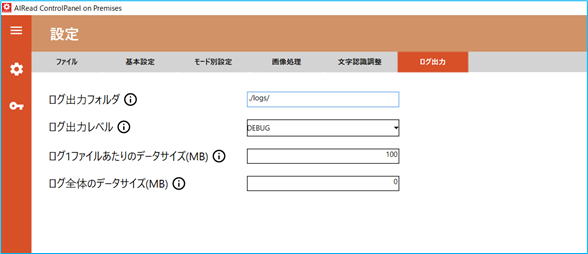
No. 内容 項目名 書式 説明 1 ログ出力フォルダ LOGS_PATH 文字列 実行ログを出力するフォルダパス 2 ログ出力レベル LOGS_LEVEL 0~3 実行ログのレベル 3 ログ1ファイルあたりのデータサイズ LOG_ROTATION_SIZE 0~100 ログファイル1つの最大サイズ(MB) 4 ログ全体のデータサイズ LOG_MAX_SIZE 0以上の整数 ログファイルを保存する最大容量(MB)
3.1.6. ファイル
共通設定ファイルファイルの新規作成、保存の操作ができます。
No. 項目名 説明 1 新規 新規で共通設定ファイルを作成する 2 開く 共通設定ファイルを指定して開く 3 上書き保存 編集中の設定を上書き保存する 4 名前を付けて保存 編集中の設定を別ファイルとして保存する 5 履歴 過去に保存した共通設定ファイルの履歴を表示する
3.2. 共通設定ファイルでのみ指定できる項目 No. 項目名 書式 説明 1 AUTO_CROPS true, false trueの場合、周囲の余白を削除する 2 OCR_MODEL_PATH 文字列 OCRエンジンで利用するモデルのフォルダパス(tessdataが存在するフォルダ) 3 OCR_MODE 1 OCRエンジンのOCRアルゴリズムを指定する 4 CTPN_PATH 文字列 大きな文字を検知する機能で利用するモジュールとモデルのフォルダパス(TextSpottingフォルダ)
3.3. 項目/文字切り取り画像の出力 手書き項目画像を出力する機能が有効(CREATE_HW_COMP_IMAGE=true)、もしくは手書き文字画像を出力する機能が有効(CREATE_HW_CHAR_IMAGE=true)の際は、手書き画像の出力先(HW_CUT_IMAGE_DIR)の指定されたディレクトリにそれぞれの手書き画像を出力します。
?指定した出力先(HW_CUT_IMAGE_DIR)
項目(component)画像の数字は、同一入力ファイル中の連番です。
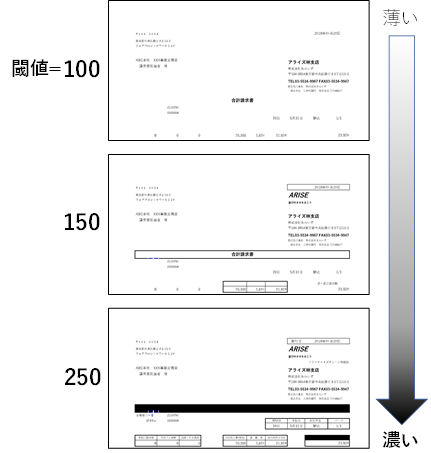
3.4. ユースケース 3.4.1. 二値化の閾値
OCRは画像を白と黒だけに変換(二値化)した状態で行います。各ピクセルの明るさ(黒0~255白)に対して、黒と白の境界とする値が二値化の閾値です。閾値は0~255を設定します。
二値化の閾値の設定によって、下記画像のように変化します。
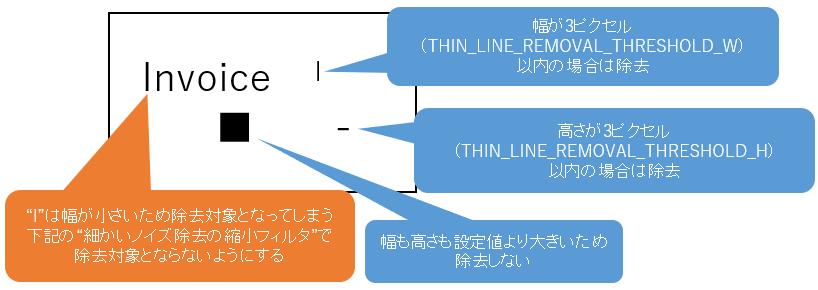
3.4.2. 細かいノイズ除去
細かいノイズ除去の閾値では、除去対象とするノイズの幅・高さを指定します。
ControlPanel項目名 共通設定ファイル項目名 推奨値 細かいノイズ除去の閾値(幅) THIN_LINE_REMOVAL_THRESHOLD_W 3 細かいノイズ除去の閾値(高さ) THIN_LINE_REMOVAL_THRESHOLD_H 3
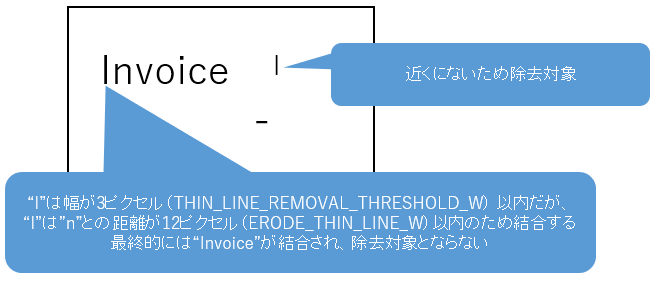
細かいノイズ除去の縮小フィルタは、近隣の文字・ノイズを結合して除去対象となるのを防ぎます。
ControlPanel項目名 共通設定ファイル項目名 推奨値 細かいノイズ除去の縮小フィルタ(幅) ERODE_THIN_LINE_W 12 細かいノイズ除去の縮小フィルタ(高さ) ERODE_THIN_LINE_H 7
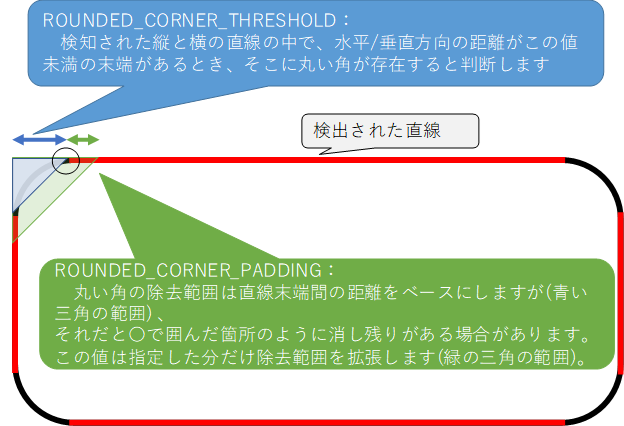
3.4.3. 丸い角の除去
帳票によっては丸い角の矩形が存在し、直線除去では角が残ってしまい誤読の原因となる場合があります。
ControlPanel項目名 共通設定ファイル項目名 推奨値 矩形の丸い角を除去する ROUNDED_CORNER_THRESHOLD 30 丸い角の除去範囲を拡張する長さ ROUNDED_CORNER_PADDING 10
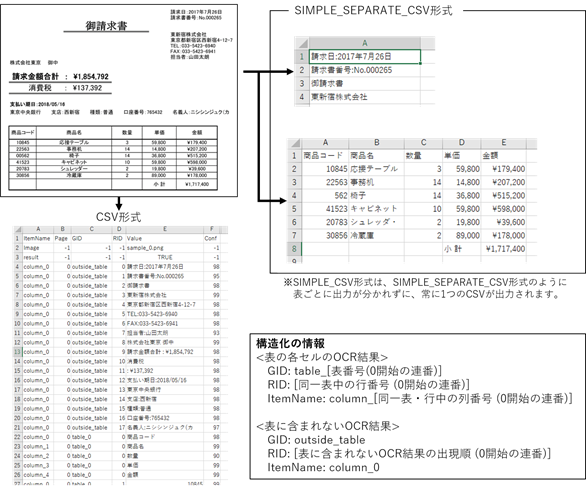
3.4.4. 表検出付全文OCR
コントロールパネルの抽出モードの設定で「キーワード指定(表検出付)」を指定した状態で全文OCRを実行すると、認識した罫線を基に表を検出し、表の各セルに対してOCRを行います。
なお、構造化情報の利用に応じて出力形式を選択可能です。
※表が段組みになっている場合には正しく構造化されません。
3.4.5. 色の抽出・除去
帳票上の印影や背景の色がOCRに影響し、正しく読み取りを行えない場合があります。
3.4.5.1. HSV色空間について
要素 指定範囲 説明 H 色相 0~179 具体的な色を定義する要素 S 彩度 0~255 色相で定義された色の鮮やかさ・濃さを表す要素 V 明度 0~255 色相で定義された色の明るさ・暗さを表す要素
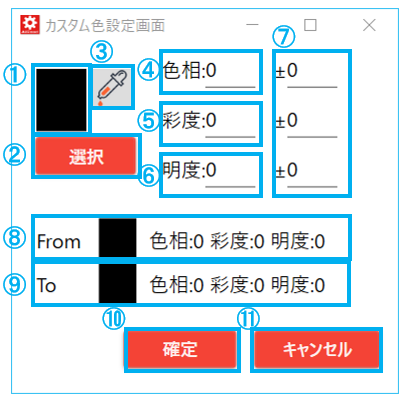
3.4.5.2. 色の指定方法(GUI)
No. 項目名 説明 1 指定した色 カラーパレット、もしくはスポイトで対象とした色が表示される 2 色の選択ボタン カラーパレットを開き、対象とする色を指定する 3 スポイトボタン スポイト画面を開き、クリックした場所の色を抽出して対象とする 4 色相 対象とした色の色相の表示、または色相を直接入力する 5 彩度 対象とした色の彩度の表示、または彩度を直接入力する 6 明度 対象とした色の明度の表示、または明度を直接入力する 7 ±(指定幅) 対象とした色の色相、彩度、明度に対して、指定した数値分の幅を上下に持たせる 8 色の対象範囲(from) 対象とした色から±で指定した数値分をマイナスして表示する 9 色の対象範囲(to) 対象とした色から±で指定した数値分をプラスして表示する 10 確定ボタン 指定した色の範囲をAIRead ContorlPanel に反映させる 11 キャンセルボタン 編集内容を反映させずに、AIRead ContorlPanel へ戻る
例)赤い色の範囲を指定する場合(GUI)
対象の色の値に対して幅を持たせることで、近い色も対象とすることができます。
3.4.5.3. 色の指定方法(テキスト)
テキストで設定を行う場合、対象としたい色の色相、彩度、明度の順で”:”(コロン)で区切り、色の指定を行います。
0 : 200 : 200 – 0 : 200 : 200
色相に前後の幅を持たせ、さらに明るい色も対象としたい場合は、下記のような指定を行います。
-15 : 200 : 200 – 15 : 200 : 255
色相(-15 – 15) 明度(200 – 255) 0から±15の値 明度200より明るい色を取得するため、55プラスした値
※彩度を変更しない場合は、同じ値とします。
例)赤い色の範囲を指定する場合(テキスト)
純粋な赤色の表現
実際は印刷等の条件により赤色の色合いは異なるため、範囲に幅を持たせることで色を対象とすることが可能です。
※色相 -10 は 170 と同義
4.2. AIRead FormEditorで設定 以下のプログラムを起動することで、AIRead FormEditor(以下FormEditor)にて共通設定ファイルを編集することができます。
<AIReadインストールフォルダ>/FormEditor/ AIReadFormEditor.exe
4.2.1. グループの作成・選択
グループを作成 を選択するとダイアログが表示されます。
グループを開く を選択すると、フォルダ選択のダイアログが開かれます。
4.2.2. フォームの追加
フォームを追加 を選択すると、ダイアログが表示されます。
各フォームIDを選択すると、定義済みの設定を確認・編集を行うことができます。
保存 を押下すると、編集済みのフォームを保存することができます。
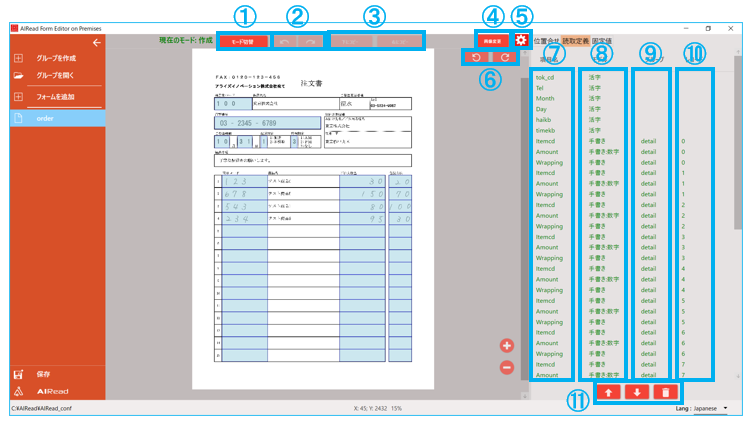
4.2.3. フォームの定義
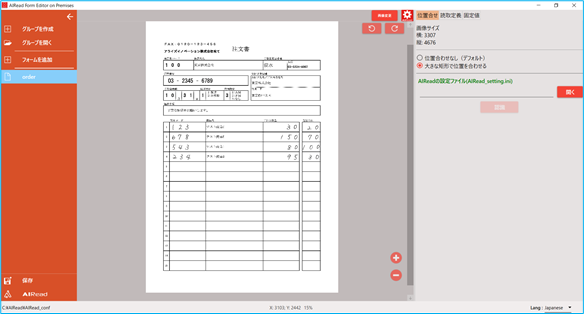
帳票自体の傾きや大きさの違いを補正します。
No. 項目名 説明 1 位置合わせ定義 位置合わせ定義画面を表示 2 位置合わせ方法の選択 (1) 位置合わせなし
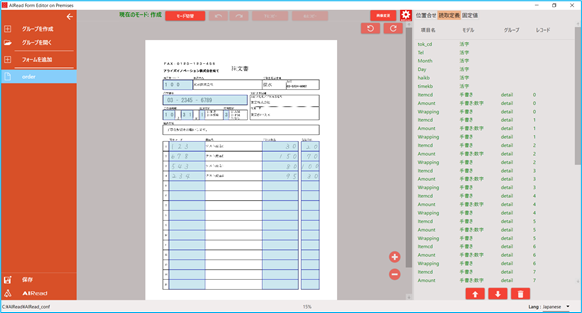
帳票上の読み取り範囲、読み取り方法、項目名を設定します。
No. 項目名 説明 1 モード切替 「選択モード」と「作成モード」を切り替える 2 元に戻す・やり直し 操作を1つ戻す(やり直す) 3 下にコピー・右にコピー 選択中の項目を下(右)にコピーする 4 画像変更 画面上で表示する画像を変更する 5 個別OCR設定の呼出 開いている定義用の個別OCR設定画面を起動する4.2.5. 個別OCR設定 を参照 6 90度回転 表示中の画像を90度回転する 7 項目名 読み取り結果ファイルに出力する項目名 8 モデル 活字OCRエンジン・手書きOCRエンジン・チェックマーク認識のいずれかを選択 9 グループ名 同じグループ名の項目でグルーピングする 10 レコードID 同じレコードIDの項目でグルーピングする(1レコード=1行) 11 移動・削除 選択中の項目を移動・削除する
固定値(必ず出力させたい)項目を設定します。
No. 項目名 説明 1 項目名 固定値の項目名 2 値 固定値の値 3 グループ 固定値のグループ(設定することで、読取のグループに結合可) 4 レコード 固定値のレコード番号(設定することで、読取のグループに結合可)
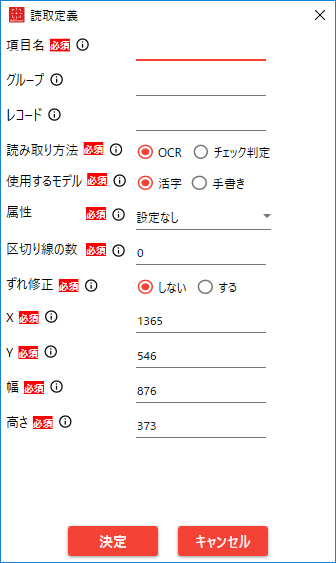
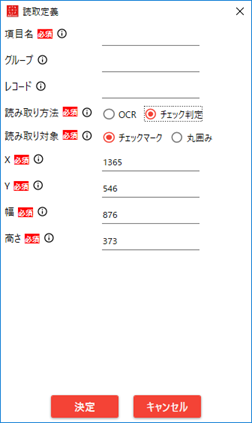
4.2.4. 読み取り定義ダイアログ
「作成モード」で読み取り範囲を指定した場合、および項目をダブルクリックした場合に開きます。
No. 項目名 説明 1 項目名 出力ファイルに出力する項目名 2 グループ名 同じグループ名の項目でグルーピングする 3 レコードID 同じレコードIDの項目でグルーピングする 4 読み取り方法 読み取り方法を「OCR(文字認識)」か「チェック判定」から選択する 5 使用するモデル 「活字」OCRエンジンで読むか「手書き」OCRエンジンで読むかを選択する 6 属性 読み取り箇所の文字の属性を指定する 7 言語 「日本語」、「カタカナ」、「英語」、「数字」、「通貨」、「数値・電話番号」から選択する(手書きのみ) 8 文字数 読み取り範囲の文字数が「複数文字」か「1文字」かを指定する 9 区切り線の数 指定した範囲中にある桁や文字を区切るための縦罫線(点線)の本数を指定する区切り線が等間隔に並んでいる必要がある 10-1 ずれ修正 ずれ修正の有効の有無を選択する 10-2 基準 ずれ修正時に、修正の基準を「セル」か「文字列」から選択 「セル」を選択した場合、ずれた読み取り範囲に最も近いセル(矩形)に読み取り位置を修正する 11 対象 (基準が「セル」の時 に使用) 読み取り範囲のずれ修正の対象となるセルに合わせる修正方向を「左」、「右」、「上」、「下」から選択する4.3.3.1ずれ修正(セルに合わせる場合)について に記載 12 方法 (基準が「文字列」の時 に使用) 読み取り範囲のずれ修正の対象となる文字列に対して行う修正の方法を「移動」か「拡張」とするかを選択する4.3.3.2ずれ修正(文字列に合わせる場合)について に記載 13 X 読み取り範囲の左上のX座標(ピクセル) 14 Y 読み取り範囲の左上のY座標(ピクセル) 15 幅 読み取り範囲の幅(ピクセル) 16 高さ 読み取り範囲の高さ(ピクセル)
No. 項目名 説明 1 項目名 出力ファイルに出力する項目名 2 グループ名 同じグループ名の項目でグルーピングする 3 レコードID 同じレコードIDの項目でグルーピングする 4 読み取り方法 読み取り方法をOCR(文字認識)かチェック判定かを選択する 5 読み取り対象 読み取り対象が「チェックマーク」か「丸囲み」かを指定する 6 閾値 テンプレート画像に対する黒領域の割合(パーセント) 7 X 読み取り範囲の左上のX座標(ピクセル) 8 Y 読み取り範囲の左上のY座標(ピクセル) 9 幅 読み取り範囲の幅(ピクセル) 10 高さ 読み取り範囲の高さ(ピクセル)
4.2.5. 個別OCR設定
フォームごとに個別でOCR設定の定義を行います。
呼び出す際に、共通のOCR設定を引継ぐか指定します。
「個別設定に使う」にチェックのついたパラメータは、AIRead実行時に共通設定ファイルのパラメータを上書きして実行されます。
設定内容については、3. 共通設定 を参照して下さい。
4.2.5.1. 設定方法
新規で個別設定を行う場合、すべての個別設定は無効となっており設定値が編集できません。□ )をクリックし、設定値を編集してください。□ )がついた項目のみとなります。
設定の編集が完了したら、保存してください。個別設定が反映されます。
保存が完了したら、右上の×ボタンで画面を閉じてください。
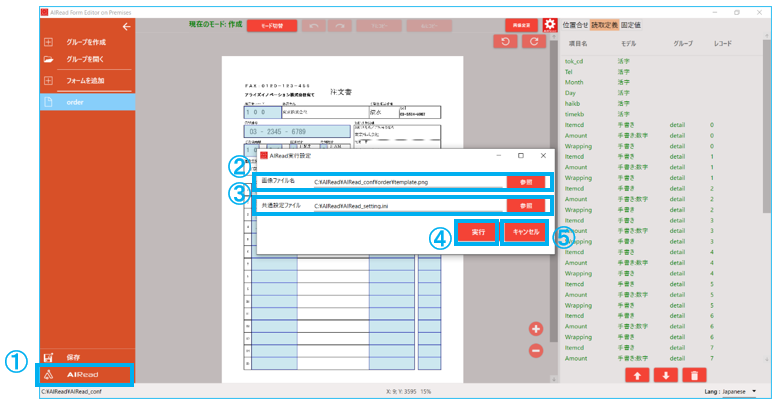
4.2.6. AIReadの実行
作成したフォームでAIReadを実行します。
No. 項目名 説明 1 AIRead実行 AIRead実行設定ダイアログを開く 2 画像ファイル名 AIReadを実行する画像ファイルを指定する 3 共通設定ファイル 使用する共通設定ファイルを指定する 4 実行 AIReadの実行を開始する 5 キャンセル ダイアログを閉じる
4.2.7. AIReadの実行結果を確認
実行後にAIReadの実行結果確認画面を表示します。
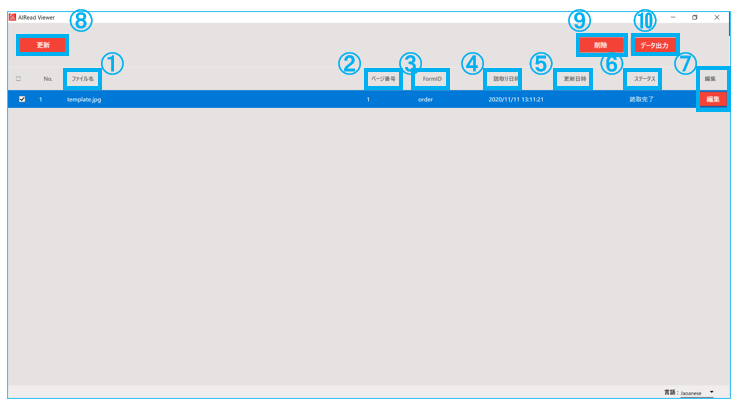
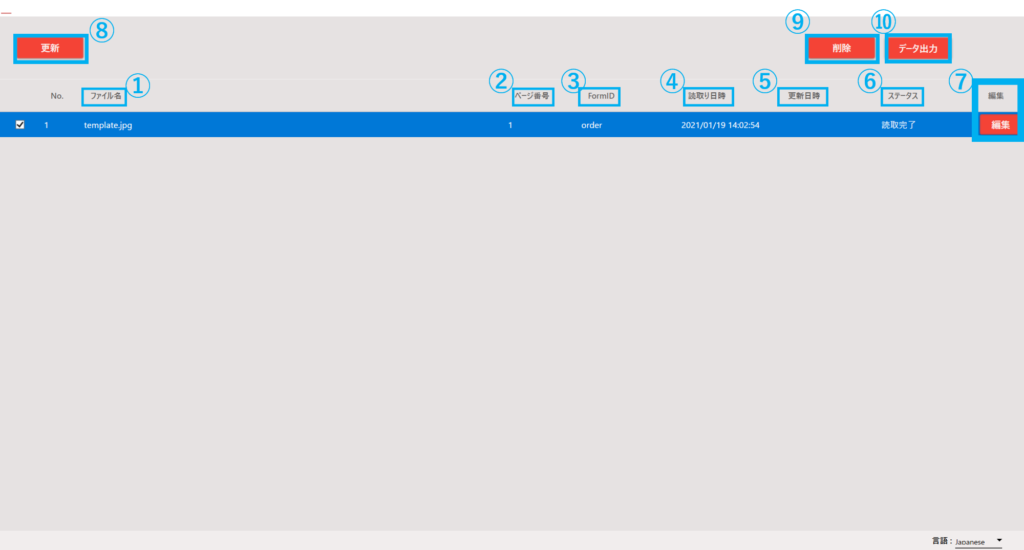
4.2.7.1. 実行結果一覧画面
No. 項目名 説明 1 ファイル名 読み取ったファイル名を表示する 2 ページ番号 読み取ったファイルのページ数を表示する 3 FormID 読み取りに使用したフォーム名を表示する 4 読取り日時 読み取りを実行した日時を表示する 5 更新日時 最終更新日時を表示する 6 ステータス 実行結果の状態を表示する 7 編集ボタン 対象の実行結果の実行結果確認画面を表示する 8 更新ボタン 実行結果一覧を最新の状態へ更新する 9 削除ボタン チェックボックスで選択した実行結果を削除する 10 データ出力ボタン チェックボックスで選択した実行結果をCSV出力する
4.2.7.2. 実行結果一覧画面
「複数ページの帳票ファイルを1つの帳票として処理する」が 有効
「複数ページの帳票ファイルを1つの帳票として処理する」が 無効
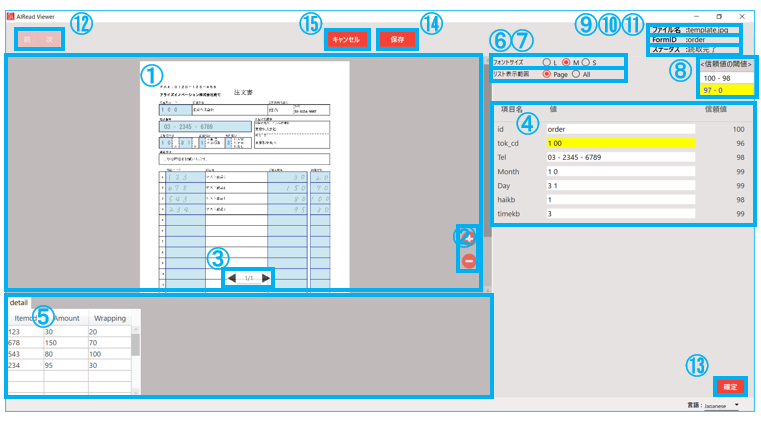
No. 項目名 説明 1 帳票画像 OCRを行った画像を表示 2 拡大縮小ボタン 帳票画像の拡大縮小操作に使用 3 ページ変更ボタン 表示する確認画面変更に使用 4 OCR結果一覧(リスト) 項目名と読み取った値(編集可能)のリスト一覧表示 5 OCR結果一覧(明細) 項目名と読み取った値(編集可能)の明細一覧表示 6 フォントサイズ変更ボタン ラジオボタンの選択でOCR結果一覧のフォントサイズを変更する 7 リスト表示変更ボタン ラジオボタンの選択で結果表示一覧を変更する 8 信頼値の閾値 OCR結果一覧の背景色の設定の表示 9 ファイル名 読み取ったファイル名を表示する 10 FormID 読み取りに使用したフォーム名を表示する 11 ステータス 読み取り結果の状態を表示する 12 前・次ボタン 実行結果一覧画面の前後の実行結果へ移動する 13 確定・確定解除ボタン ステータスを”確定済み”へ変更する 14 保存ボタン 編集後の各項目の値を保存 15 キャンセルボタン 編集内容を保存せず、実行結果一覧画面へ戻る
4.2.8. 実行結果の保存
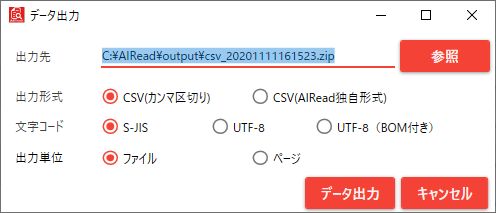
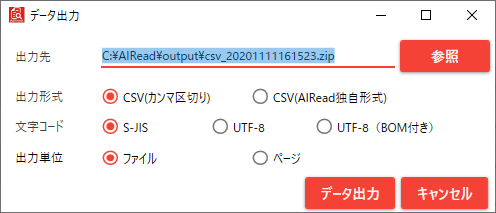
データ出力ボタンを押下すると、保存用のダイアログが表示されます。
No. 項目名 説明 1 出力先 実行結果の保存先を指定する 2 出力形式 実行結果の保存形式をCSV(カンマ区切り) か CSV(独自形式) かを設定する 3 文字コード 出力する実行結果の文字コードを、S-JIS、UTF-8、UTF-8(BOM付き)から選択する 4 出力単位 「複数ページの帳票ファイルを1つの帳票として処理する」が設定された帳票が含まれる場合のみ表示される 5 データ出力ボタン 指定された設定で実行結果を保存する 6 キャンセルボタン 保存用ダイアログを閉じる
4.2.9. 出力形式
FormEditorからの実行結果を出力する形式は2種類あります。
4.2.9.1. CSV(カンマ区切り)
1行目にヘッダ情報、2行目以降にデータ情報が出力される、一般的なCSV形式です。ヘッダ、明細それぞれでCSVファイルが出力されます。
CSVファイル名は、下記のルールに従って作成されます。
・グループ名の設定がない項目(ヘッダ項目)
[入力ファイル名].csv
・グループ名の設定がある項目(明細項目)
[入力ファイル名]_[グループ名].csv
※ファイル名に使用できない文字(\/:*?”<>|)がグループ名に含まれる場合、その文字は除外されます
明細データは、FormEditorの読み取り定義で指定した設定が、下記のルールに従ってまとめられます。
ファイル:グループ
ヘッダ項目の出力 ( [入力ファイル名].csv)
“Image”,”Image_jshfilename”,”modifyDate”,”processDate”,”result”,”form_id”,”tok_cd”
※固定で”Image”,”Image_jshfilename”,”modifyDate”,”processDate”,”result”,”form_id”が出力されます。これらの項目には5.1 共通 を参照ください。
明細項目の出力 ([入力ファイル名]_[グループ名].csv
“Itemcd”,”Amount”,”Wrapping”
4.2.9.2. CSV(独自形式)
5.2. CSV を参照ください。
4.3. フォーマット定義ファイル 帳票の位置を合わせるための情報、出力ファイルに記載する情報、OCRで読み取る位置の情報はフォーマット定義ファイルで設定します。
項目名 書式 説明 セクションID 0 位置合わせ情報 1 出力情報(固定値) 2 OCR情報 3 チェックマーク情報(画像差分で判定) 4 チェックマーク情報(✔の形で判定)
※位置合わせ情報は省略可です。省略した場合、絶対座標で抽出します。
ファイル名:AIRead_format.ini フォーム定義ファイルイメージ: ずれ修正なしの場合
0 3307 4676 300 1745 2645 1745 300 4295
ずれ修正ありの場合
1 -1 id order
4.3.1. 位置合わせ情報
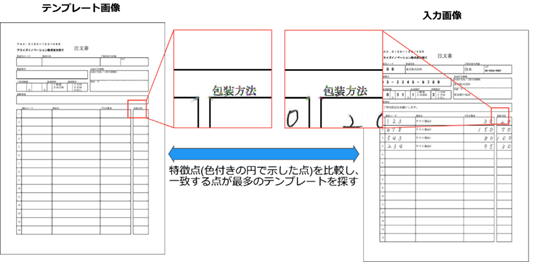
帳票の中で一番大きな矩形を基準に位置を合わせます。
No. 項目名 書式 必須 説明 1 セクションID 0 必須 2 width 整数 必須 ベースとなる画像サイズの幅 3 height 整数 必須 ベースとなる画像サイズの高さ 4 x1 整数 必須 ベースとなる矩形の左上の点のx座標 5 y1 整数 必須 ベースとなる矩形の左上の点のy座標 6 x2 整数 必須 ベースとなる矩形の右上の点のx座標 7 y2 整数 必須 ベースとなる矩形の右上の点のy座標 8 x3 整数 必須 ベースとなる矩形の左下の点のx座標 9 y3 整数 必須 ベースとなる矩形の左下の点のy座標
※位置合わせ情報は省略可です。省略した場合、位置合わせは行われず絶対座標で抽出します。
■位置合わせイメージ
画像内の最大の矩形を検知し、左上・右上・左下の3点を基点に位置を合わせます。
4.3.2. 出力情報(固定値)
No. 項目名 書式 必須 説明 1 セクションID 1 必須 2 シーケンス番号 整数 (使用しない) 3 項目名 文字列 必須 出力情報に記載する項目名 4 値 文字列 必須 出力する文字列 5 グループID 文字列 グループID(明細・表の名前)を指定 6 レコードID 整数 レコードID(明細の行番号)を指定
4.3.3. 出力情報(OCR)
No. 項目名 書式 必須 説明 1 セクションID 2 必須 2 シーケンス番号 整数 (使用しない) 3 グループID 文字列 グループID(明細・表の名前)を指定 4 レコードID 整数 レコードID(明細の行番号)を指定 5 x 整数 必須 読取範囲の基準となる座標(左上の点)のx座標 6 y 整数 必須 読取範囲の基点となる座標(左上の点)のy座標 7 width 整数 必須 読取範囲の幅 8 height 整数 必須 読取範囲の高さ 9 type 0, 1 必須 0 : 活字 10 length 0以上の整数 必須 typeが 0(活字)の場合 11 フィールドID 文字列 必須 項目名 12 ずれ修正 0, 1 0:文字列でのずれ修正 13 修正対象(左) 0, 1 ずれ修正が1(セル)の場合のみ有効 14 修正対象(右) 0, 1 ずれ修正が1(セル)の場合のみ有効 15 修正対象(上) 0, 1 ずれ修正が1(セル)の場合のみ有効 16 修正対象(下) 0, 1 ずれ修正が1(セル)の場合のみ有効 17 修正方法 0, 1 ずれ修正が0(文字列)の場合のみ有効 18 属性 文字列 後処理を行う属性を指定する
※修正対象(右)、修正対象(左)、修正対象(上)、修正対象(下) は併用可能
4.3.3.1. ずれ修正(セルに合わせる場合)について
セルに合わせるずれ修正を行う場合、下記のルールで行われます。
<合わせる対象>
読み取り範囲に対し、以下の 2つの条件を満たすセルが合わせる対象となります。30%以上重なっている こと重なっている面積が最大 であること
<例外>
修正後のセルの高さが元の読み取り範囲の高さの1.2倍を超える場合、ずれ修正は行われません。
<修正対象(左右上下)について>
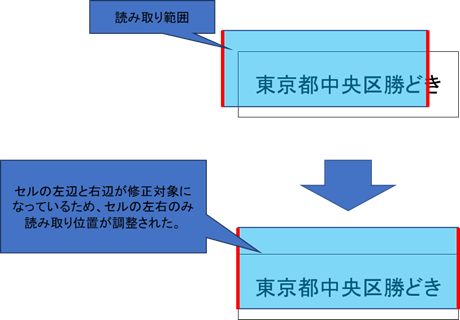
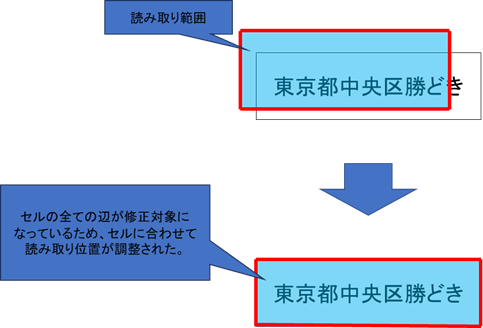
修正の対象の選択によって、修正結果が下記の例のように変わります。
ずれ修正の修正対象(左、右)が有効の場合
ずれ修正の修正対象(左右上下)が有効の場合
4.3.3.2. ずれ修正(文字列に合わせる場合)について
文字列に合わせるずれ修正を行う場合、下記のルールで行われます。
<合わせる対象>
読み取り範囲に対し、面積が30%以上重なっている文字列 が合わせる対象となります。
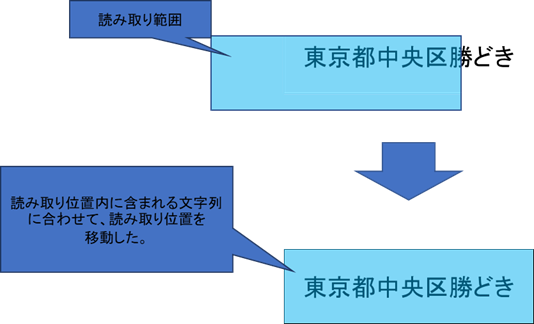
<修正方法:移動について>
修正方法に「移動」を指定した場合、読み取り範囲(矩形の形)は変更せず合わせる対象の文字列が入るように読み取り位置を移動させます。
※重なっている文字列の範囲より読み取り範囲が小さい場合は修正しません。
ずれ修正の方法が文字列を基準とした移動の場合
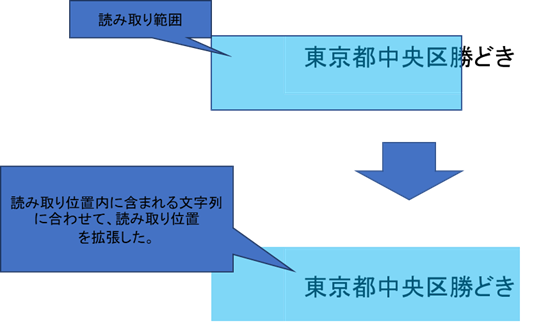
<修正方法:拡張について>
修正方法に「拡張」を選択した場合、読み取り範囲に重なる全文字列が包含できるように読み取り範囲を拡張します。
ずれ修正の方法が文字列を基準とした拡張の場合
4.3.4. 出力情報(チェックマーク)
No. 項目名 書式 必須 説明 1 セクションID 3 または 4 必須 3 : テンプレート画像との差分で判定 2 シーケンス番号 整数 (使用しない) 3 グループID 文字列 グループID(明細・表の名前)を指定 4 レコードID 整数 レコードID(明細の行番号)を指定 5 x 整数 必須 読取範囲の基準となる座標(左上の点)のx座標 6 y 整数 必須 読取範囲の基点となる座標(左上の点)のy座標 7 width 整数 必須 読取範囲の幅 8 height 整数 必須 読取範囲の高さ 9 type 0 必須 10 length 0~1000 必須 (セクションID=3のときのみ) 11 フィールドID 文字列 必須 項目名
4.4. AIRead RuleEditorで設定 以下のプログラムで、AIRead RuleEditor(以下RuleEditor)を起動することで、ルールを編集することができます。
<AIReadインストールフォルダ>/RuleEditor/RuleEditor.exe
4.4.1. ルールを作成・開く
「ルールを作成」を選択するとダイアログが表示されます。
「ルールを開く」を選択すると、フォルダを選択する画面を開きます。
4.4.2. 文書種別の管理
1つのルール一式を「文書種別」と呼びます。
No. 項目名 説明 1 +(文書種別列) 文書種別を追加する 2 +(識別キーワード列) 識別キーワードを追加する 3 -(識別キーワード列) 識別キーワードを削除する
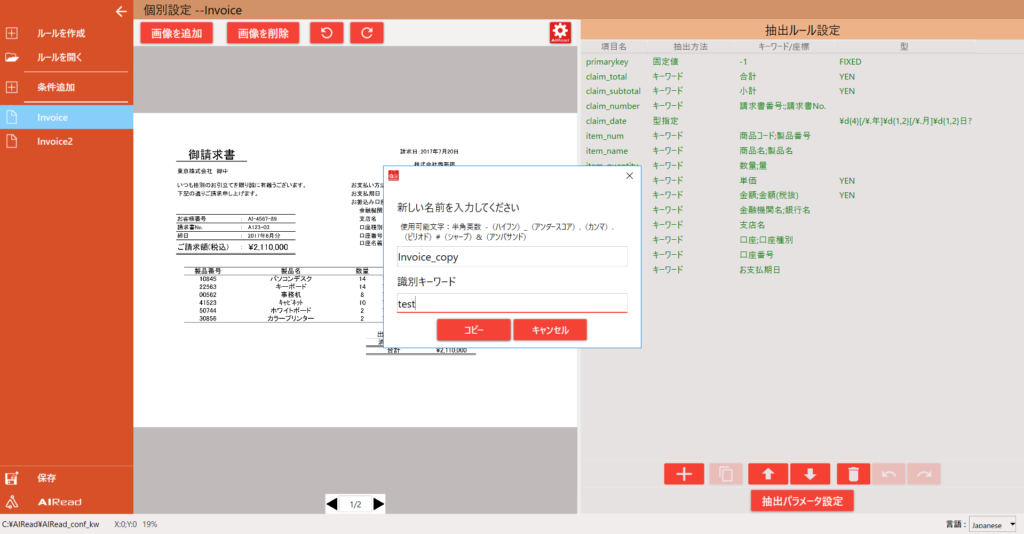
文書種別の追加 キーワードの設定 文書種別のコピー コピーを選択するとダイアログが表示されます。
ユニークな文書種別、識別キーワードを入力しコピーボタンを押下します。
文書種別がコピーされます。
制限事項: 4.4.3. 画像の追加
文書種別に対応する画像を追加します。
ファイルを選択し、「開く」ボタンを押すと画像を追加します。
No. 項目名 説明 1 ↺ ↻ (90度回転) 表示中の画像を90度回転する 2 ◀ ▶ (画像送り) 表示する画像を選択する 3 (画像上で Ctrlキー + マウスホイール操作) 画像を拡大/縮小する
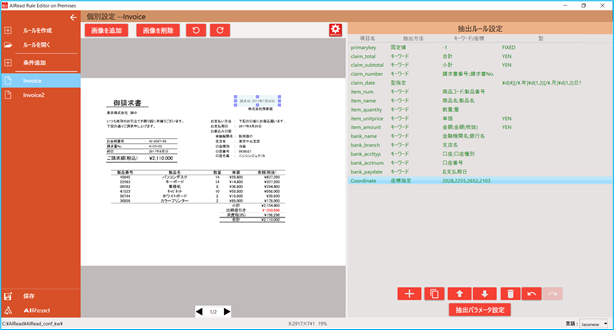
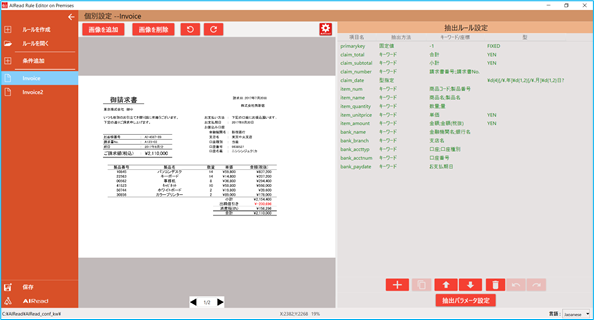
4.4.4. 抽出ルール編集
項目ごとに抽出ルールを設定します。
※下記、左から順に各ボタンの説明
No. 項目名 説明 1 + 抽出ルールにメタデータを追加するため設定画面を開く 2 コピーボタン 選択中の抽出ルールをコピーします 3 ⇑⇓ 選択したメタデータのリスト位置を上下する 4 トラッシュボックスマーク 選択したメタデータを削除する 5 ↶↷マーク 操作を元に戻す(↶)、やり直し(↷)
「+」ボタンを押すと、メタデータ設定画面を開きます。
抽出ルール設定の一覧から任意の項目をマウスダブルクリックするとメタデータ設定画面を開きます。
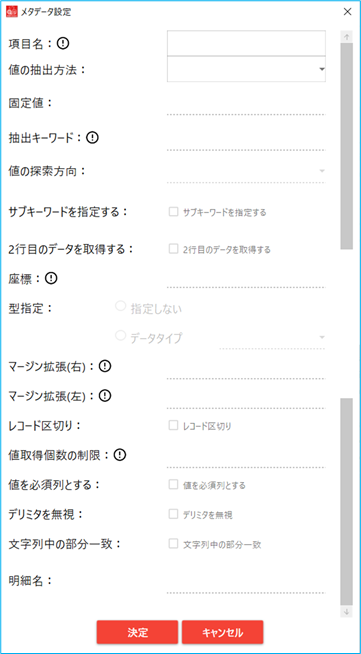
No. 項目名 説明 1 項目名 メタデータの項目名を入力する 2 値の抽出方法 下記より抽出方法を選択する 3 抽出キーワード 抽出するキーワード文字列を入力する 4 固定値 抽出結果に関わらず、定義された値を出力する 5 値の探索方向 下記より探索方向を選択する 6 サブキーワードを指定する 下記より指定方法の選択をする 7 2行目のデータを取得する 値の出力時に、抽出キーワードで指定された文字列 と 指定された文字列の下1列を抽出し結合する 8 座標 位置指定の場合、対象矩形領域の座標を入力する 9 型指定 下記より型を選択する 10 マージン拡張(右) 右側マージンを数字で入力する 11 マージン拡張(左) 左側マージンを数字で入力する 12 レコード区切り レコード区切りをするかチェック入力する 13 値取得個数の制限 制限値を数字で入力する 14 列を必須列とする 列を必須化するかチェック入力する 15 デリミタを無視 デリミタを無視するかチェック入力する 16 文字列中の部分一致 文字列の部分一致をするかチェック入力する 17 明細名(XML出力の場合) XML出力の際の明細名を入力する
「値の抽出方法」でキーワードの座標指定、および座標指定を選択した場合、座標の入力をマウスの範囲指定で行います。
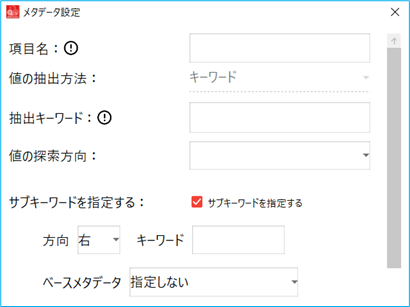
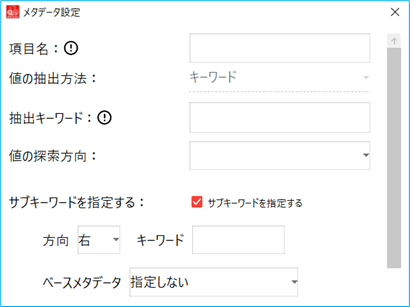
メタデータ設定画面で「キーワードの座標指定」もしくは「座標指定」を選択して決定を押し画面を閉じる 画像表示画面上で該当の位置をマウスドラッグで指定する 「サブキーワードを指定する」を選択した場合、ベースメタデータ、もしくは抽出キーワードに合わせ、サブキーワードを指定します。
(1) 「ベースメタデータ」を使用する場合
1. メタデータ設定画面で「値の抽出方法」をキーワードに指定し、「サブキーワードを指定する」にチェックを入れる
2. 「ベースメタデータ」を指定し、追加する条件に合わせ、「キーワード」と「方向」を指定する
(2) 「抽出キーワード」とサブキーワードを両方使用する場合
1. メタデータ設定画面で「値の抽出方法」をキーワードに指定し、「サブキーワードを指定する」にチェックを入れる
2. 「抽出キーワード」「値の探索方向」を指定し、「方向」「キーワード」を指定する
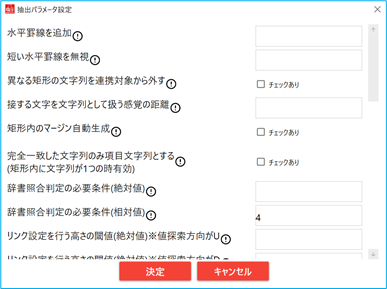
4.4.5. 抽出パラメータ設定
文書種別ごとの抽出に影響する設定を編集します。
画面右下「抽出パラメータ設定」を押すと、抽出パラメータ設定画面を開きます。
ユースケースは4.5.3抽出パラメータ設定 を参照してください。
No. 項目名 説明 1 水平線を追加 指定したY 座標(72DPI、左下原点)位置に水平罫線を追加する 2 短い水平線を無視 短い水平罫線を無視するかどうかの閾値。ページ幅に対する割合(N 倍)で指定 3 異なる矩形の文字列を連携対象から外す 有効にすると文字列が罫線に囲まれている場合に、異なる矩形に属する文字は連結対象から外す 4 接する文字を文字列として扱う間隔の距離 接する2つの文字を1つの文字列として扱うかどうかの閾値 文字間の文字行の高さに対する比率で指定する 5 矩形内のマージン自動生成 有効にすると1つの矩形にアイテムが1つだけある場合に、そのアイテムのマージンを自動生成する 6 完全一致した文字列のみ項目文字列とする 有効にすると1つの矩形に1つだけ文字列がある場合に、完全一致(編集距離での許容は有効)する時のみ項目文字列として扱う 7 辞書照合判定の必要条件(絶対値) 辞書照合判定の必要条件(絶対値):編集距離がこの値以下である場合は辞書に照合したとみなす 8 辞書照合判定の必要条件(相対値) 辞書照合判定の必要条件(相対値):許容する編集距離を照合対象の辞書単語と、抽出文字列のいずれか短い方に対する割合で指定 9 リンク設定を行う高さの閾値(絶対値)※値探索方向がU 項目文字列と値文字列間で、リンク設定を行うかどうかの高さの差の閾値(絶対値)。項目文字列に対し値文字列が上方向にある場合に適用される。(DIR=U) 10 リンク設定を行う高さの閾値(絶対値)※値探索方向がD 項目文字列と値文字列間で、リンク設定を行うかどうかの高さの差の閾値(絶対値)。項目文字列に対し値文字列が下方向にある場合に適用される。(DIR=D) 11 複数列にまたがる値文字列を無視する閾値 複数列にまたがる値文字列を無視するかどうかの閾値。2以上の場合有効となる。(0,1の場合は、複数列にまたがる値でも無視されない) 12 縦方向にリンクする閾値 項目文字列と値文字列の縦方向のリンクを設定する場合に、許容するYグリッドの差分の閾値。1(デフォルト)を指定した場合、Yグリッドが隣り合う項目文字列と値文字列のみがリンクされる 13 水平方向に並んだ値のレコード分割 レコード分割を行う値文字列数の閾値。この数以上の値文字列が水平に並んだ場合、レコードの分割を行う 14 罫線をリンクの接続条件とする 有効にすると項目文字列と値文字列のリンクを設定する場合に、間の罫線の本数を接続条件とする 15 項目文字列と値文字列が共存した際の正現ID” 同一文字行内に、項目文字列と値文字列が共存していると判定する場合の、項目-値の区切り文字の正現ID(複数指定は不可) 16 水平の罫線でレコードを区切る 有効にすると水平の罫線をレコード区切りとして利用する 17 値を必須列とした際の適用条件 複数のメタデータにREQUIRED を定義した場合に適用される条件を設定する 18 罫線情報を抽出する(テキストつきPDFのみ) 有効にするとメタデータ抽出時、イメージから罫線情報を抽出してPDFに埋め込む 19 罫線情報を削除する(テキストつきPDFのみ) 「罫線情報を抽出する」有効時、有効にすると既に埋め込まれている罫線の情報を削除する 20 年号の指定 DATE_YMD型で、年号が指定されておらず、かつ年が2桁の場合に設定する年号を指定する。R(*)、令和、H(*)、平成、S(*)、昭和、T(*)、大正、M(*)、明治のいずれかで指定する。 (*)半角または全角での指定が可能 21 横方向連結時の区切り文字 横方向に連結する時は区切り文字を半角スペース固定としているが、行の連結に使用する区切り文字を横方向の連結にも使用できるようにするパラメータを追加する。対象は以下のデータとする 22 キーワード検索時に無視する文字列 抽出キーワード検索時に対象外する文字を設定する 23 無視する文字列 抽出キーワードの検索時、及び値の抽出時に対象外とする文字列を設定する 24 半角スペースを出力しない 入力文書に含まれる文字の文字間隔が一定の間隔である場合、通常は、文字の間に半角空白を埋め込むが、半角空白の埋め込みを抑止したい場合にこのパラメータを指定する 25 抽出する項目を正規表現・データタイプで限定 抽出キーワードによる抽出された項目は、正規表現・データタイプに一致していない項目も全て出力される。本指定では、抽出される項目を正規表現・データタイプに一致したものに限定する事が可能 26 抽出キーワードの文字間隔許容値 抽出キーワードに指定された文字列の判定において、各文字間隔の許容値を指定する。 指定値は文字の高さに対する倍率で指定する。5.0の場合、文字の高さ×5.0の距離まで許容する 27 矩形内がキーワードのみの場合マージンを設定 SET_MARGIN_BY_BOXを有効にした場合、矩形内にキーワードのみある時にマージンが設定される。本指定を1にする事で、矩形内に他のキーワードでない他の文字があってもマージンを有効とする 28 キーワードと重なった文字列を抽出する 有効にするとキーワード抽出のキーワード(マージン含む)と重なっている文字列を抽出する 29 正規表現使用時に半角スペースを無視する 有効にするとメタデータで適用正規表現と一致する文字列を検索する際に半角空白を無視する 30 正規表現一致時に置換を適用する 有効にすると抽出キーワードの正規表現一致時に正規表現で指定した記憶範囲による項目の置換を適用する 31 データタイプと一致しない際に再判定する 抽出キーワードのデータタイプ判定において、データタイプに一致しなかった場合に、前後の文字列を削除して再判定するかを指定する
4.4.6. 個別OCR設定
ルール定義ごとに個別でOCR設定の定義を行います。
個別OCR設定の呼出 ボタンを押下することで、個別OCR設定用のAIRead ControlPanel 画面を呼び出します。
「個別設定に使う」にチェックのついたパラメータは、AIRead実行時に共通設定ファイルのパラメータを上書きして実行されます。3. 共通設定 を参照して下さい。
4.4.6.1. 設定方法
新規で個別設定を行う場合、すべての個別設定は無効となっており、設定値の編集ができません。
設定の編集が完了したら、保存してください。個別設定が反映されます。
保存が完了したら、右上の×ボタンで画面を閉じてください。
4.4.7. AIReadの実行
作成した文書種別でAIReadを実行します。
No. 項目名 説明 1 AIRead実行 AIRead実行設定ダイアログを開く 2 画像ファイル名 AIReadを実行する画像ファイルを指定する 3 共通設定ファイル 使用する共通設定ファイルを指定する 4 実行 AIReadの実行を開始する 5 キャンセル ダイアログを閉じる
4.4.8. AIReadの実行結果を確認
実行後にAIReadの実行結果一覧画面を表示します。
4.4.8.1. 実行結果一覧画面
No. 項目名 説明 1 ファイル名 読み取ったファイル名を表示する 2 ページ番号 読み取ったファイルのページ数を表示する 3 FormID 読み取りに使用した文書種別名を表示する 4 読取り日時 読み取りを実行した日時を表示する 5 更新日時 最終更新日時を表示する 6 ステータス 実行結果の状態を表示する 7 編集ボタン 対象の実行結果の実行結果確認画面を表示する 8 更新ボタン 実行結果一覧を最新の状態へ更新する 9 削除ボタン チェックボックスで選択した実行結果を削除する 10 データ出力ボタン チェックボックスで選択した実行結果をCSV出力する
4.4.8.2. 実行結果一覧画面
「複数ページの帳票ファイルを1 つの帳票として処理する」が 有効
「複数ページの帳票ファイルを1つの帳票として処理する」が 無効
No. 項目名 説明 1 帳票画像 OCRを行った画像を表示する 2 拡大縮小ボタン 帳票画像の拡大縮小操作に使用 3 確認画面変更ボタン 表示する確認画面変更に使用 4 OCR結果一覧(リスト) 項目名と読み取った値(編集可能)のリストの一覧表示 5 OCR結果一覧(明細) 項目名と読み取った値(編集可能)の明細の一覧表示 6 フォントサイズ変更ボタン ラジオボタンの選択でOCR結果一覧のフォントサイズを変更する 7 リスト表示変更ボタン ラジオボタンの選択で結果表示一覧を変更する 8 信頼値の閾値 OCR結果一覧の背景色の設定の表示 9 ファイル名 読み取ったファイル名を表示する 10 FormID 読み取りに使用した文書種別名を表示する 11 ステータス 読み取り結果の状態を表示する 12 前・次ボタン 実行結果一覧画面の前後の実行結果へ移動する 13 確定・確定解除ボタン ステータスを”確定済み”へ変更する 14 保存ボタン 編集後の各項目の値を保存 15 キャンセルボタン 編集内容を保存せず、実行結果一覧画面へ戻る
4.4.9. 実行結果の保存
データ出力ボタンを押下すると、保存用のダイアログが表示されます。
No. 項目名 説明 1 出力先 実行結果の保存先を指定 2 出力形式 実行結果の保存形式をCSV(カンマ区切り) か CSV(独自形式) に設定 3 文字コード 出力する実行結果の文字コードをS-JIS、UTF-8、UTF-8(BOM付き)に設定出力する実行結果の文字コードをS-JISかUTF-8に設定 4 出力単位 (「複数ページの帳票ファイルを1つの帳票として処理する」が設定された帳票が含まれる場合のみ表示) 5 データ出力ボタン 指定された設定で実行結果を保存 6 キャンセルボタン 保存用ダイアログを閉じる
4.4.10. 出力形式
RuleEditorからの実行結果を出力する形式は2種類あります。
4.4.10.1. CSV(カンマ区切り)
1行目にヘッダ情報、2行目以降にデータ情報が出力される、一般的なCSV形式です。ヘッダ、明細それぞれでCSVファイルが出力されます。
CSVファイル名は下記のルールに従って作成されます。
・明細名の設定がない項目(ヘッダ項目)
[入力ファイル名].csv
・明細名が設定された項目(明細項目)
[入力ファイル名]_[明細名].csv
※ファイル名に使用できない文字(\/:*?”<>|)が明細名に含まれる場合、その文字は削除されます
明細データは、Ruleditorの読み取り定義で指定した設定が、下記のルールに従ってまとめられます。
ファイル:明細名
ヘッダ項目の出力 ( [入力ファイル名].csv)
“Image”,”Image_jshfilename”,”modifyDate”,”processDate”,”result”,”form_id”,” primarykey”,” claim_total”, “sample1_1.jpg”,”C: \Result\20200325_175513_547\ sample1_1.jpg “,”2020-02-06T16:28:52″,”2020-03-25T17:55:13″,”true”,”Invoice”,”-1″,”2110000″
※固定で”Image”,”Image_jshfilename”,”modifyDate”,”processDate”,”result”,”form_id”が出力されます。これらの項目については、5.1. 共通 を参照してください。
明細項目の出力 ([入力ファイル名]_[明細名].csv
“item_num”,”item_name”,”item_quantity”,”item_unitprice”,”item_amount”
4.4.10.2. CSV(独自形式)
5.2. CSV を参照ください。
4.5. ルール定義ファイル 4.5.1. 文書種別定義
帳票の種類を定義します。
No. 項目名 書式 説明 1 文書種別ID 文字列 (半角英数) 文書種別ごとに帳票の識別ID、フォーマット定義ファイルのフォルダ名を設定 2 キーワード 文字列 帳票を識別するためのキーワード
documentType documentKeyWord
・1システムに作成できる文書種別数は1000
4.5.2. メタデータ定義
メタデータとは、「インボイス番号」「数量」「価格」など、抽出対象となるものを指します。項目名と値に分けられ、「インボイス番号」等が項目名、「2014-001」などが値の例となります。
指定可能なメタデータの設定とその説明を以下に示します。
ファイル名:IDE_metadata_setting.ini ファイルの場所:<AIREAD_HOME>/AIRead_conf_kw /documentType名/IDE_metadata_setting.ini
No. 項目名 内容 指定可能な値 備考 1 type 値によって固定値の出力かデータ抽出となる 1,2 ・ 1の場合:固定の出力 2 itemName 項目名を指定する 文字列 使用できる文字 3 extractKeyWord 抽出キーワードを指定する 文字列 セミコロン(;)で区切ることで1つの項目に複数の抽出キーワードを割り当てることが可能(*1) 4 MARGIN_RIGHT 該当メタデータの抽出キーワード文字列の領域を、マージン分拡張したものと仮定して処理する 整数 単位はピクセル 6 LB 該当メタデータをレコード区切りとして使用する TRUE TRUE以外を指定した場合無効 7 DIR 該当メタデータの値探索方向を指定(限定)する R(右方向) 8 LMAX 該当メタデータで、抽出する値の個数を制限する 0以上の整数 9 REQUIRED 該当メタデータを必須列とします。値が入っていない場合、そのレコードは抽出対象外となる TRUE TRUE以外を指定した場合無効 10 NODELIMITER 該当メタデータは、項目文字列と値文字列の間にデリミタがないものとして扱う TRUE TRUE以外を指定した場合無効 11 GETITEMFROM 文字列中に項目文字列が部分一致した場合、そこで文字列を分割して処理する TRUE TRUE以外を指定した場合無効 12 POSITION 指定された座標位置に、キーワードが存在するとみなして処理する 整数を4つカンマで区切って設定(*2) 座標は左下原点、単位はピクセルで指定する(pdfを変換する場合は300dpiを推奨) 13 POSITIONTOEXTRACT 指定された座標位置の値を抽出する 整数を4つカンマで区切って設定(*2) 座標は左下原点、単位はピクセル値で指定する 14 TABLE_NAME タグをグルーピングする 文字列 15 REGEX 正規表現をメタデータに割り当てて、抽出した値をバリデーションする 文字列 シングルコーテーションで閉じる 16 DATATYPE 値のデータ型(数字、通貨、日付等)を定義する データタイプの指定については後述 17 DATATYPE_VALUE 「DATATYPE」SUB_KEYWORD_DIR / SUB_KEYWORD_NEAR を使用する場合の抽出条件を定義する 定義方法についてはXXX 参照 18 is_output 「DATATYPE」SUB_KEYWORD_NEARを使用する場合、抽出された文字列 と 抽出された文字列の下1列を抽出し結合する 0(結合して抽出を行わない)
(*1) 1つのメタデータ定義の中で ”extractKeyWord”を指定した項目を1つ以上設定する必要がある
( 4 )( 5 ) MARGIN_RIGHT, MARGIN_LEFT
該当メタデータ(抽出キーワード)の領域をマージン分拡張したものと仮定して処理します。単位はピクセルです。
(例)
( 6 ) LB
該当メタデータをレコード区切りとして使用します。値にTRUE以外を指定した場合は無効(指定していないのと同じ)となります。
ExtendedにLBを指定した場合、Extendedの値が抽出される高さでレコードを分割する。
( 7 ) DIR
該当メタデータの値探索方向を指定(限定)します。
( 8 ) LMAX
該当メタデータで、抽出する値の個数を制限します。指定できるのは整数とし、
No. DIRオプションの値 LMAXのデフォルト値 1 R(右方向)、L(左方向)、 U(上方向) 1 2 D(下方向) 0 3 RD(右+下方向)または指定なし 0
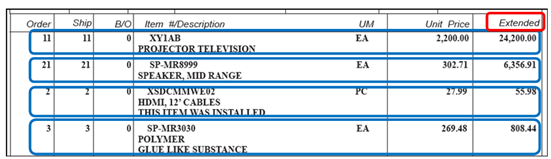
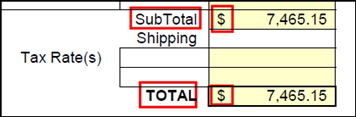
下記例の場合、SubTotalの値として $ 7,465.15 を取得するには、LMAXを0もしくは2以上に設定します。
( 9 ) REQUIRED
該当メタデータを必須項目として扱います。値がないレコードがある場合、そのレコードは抽出の対象外となります。
なお、複数のメタデータに指定した場合、指定されているメタデータすべてが 値を持たないレコードは抽出対象外となります(AND条件)。本設定は抽出パラメータにて切り替えが可能です。
( 10 ) NODELIMITER
IDEでは、項目文字列と値文字列が同一文字行内に共存している場合、定義されたデリミタで区切られていれば項目文字列と値文字列の分割を行います。ただし、データによってはデリミタ文字がなく、項目文字列と値文字列が1つの文字列になっている場合があるため、本パラメータが指定されたメタデータはデリミタ文字がなくても分割の対象とします。
( 11 ) GETITEMFROMSTRING
こちらのパラメータが指定されている場合、項目文字列が文字列中で部分一致すれば項目文字列として扱い、そこで文字列の分割を行って以降の処理を行います。項目文字列・値文字列のペアが横向きにいくつも並んでいる場合に必要となることがあります。
( 12 ) POSITION
こちらのパラメータが指定されている場合、指定された座標位置にキーワードが存在するとみなして処理を行う。座標は、300dpiの左下原点で指定する。
( 17 ) DATATYPE_VALUE
「DATATYPE」でSUB_KEYWORD_DIR / SUB_KEYWORD_NEAR が指定されている場合、抽出条件を指定することができる。
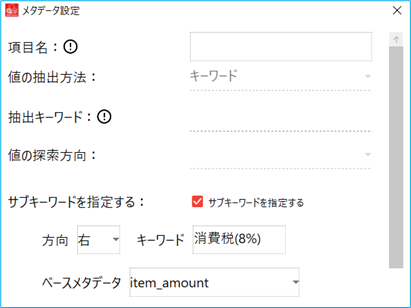
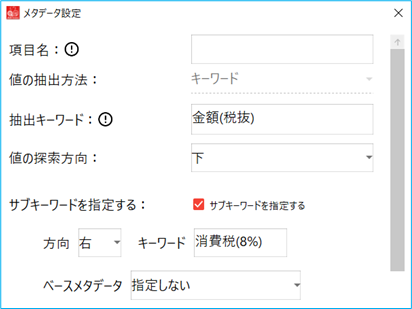
例1)SUB_KEYWORD_DIR メタデータ item_amount で、金額(税抜)の下方向を抽出する定義を行っている場合に、消費税の金額のみを抽出する
メタデータ item_amount を基準とし、消費税(8%)の右側を追加条件として指定する
R : item_amount : 消費税 (8%)
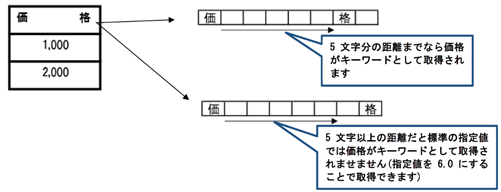
指定方向(R・L・U・D より選択):基準とするメタデータ(itemName を指定):追加するキーワード(正規表現で記述)
例2)SUB_KEYWORD_NEAR
メタデータ address で、住所の右方向を抽出する場合に、抽出できる文字列の下1行を抽出する
メタデータ address を基準とし、抽出される「東京都中央区勝どき3丁目13-1」の下1行を抽出する
指定方向(R・L・U・D より選択):基準とするメタデータ(itemName を指定):使用するデータタイプ
4.5.3. 抽出パラメータ設定
指定可能な抽出パラメータとその説明を以下に示します。
ファイル名:IDE_setting.ini ファイルの場所:<AIREAD_HOME>/AIRead_conf_kw /documentType名/IDE_setting.ini No. 項目名 内容 デフォルト値 1 USER_DEFINED_H_LINES 指定したY座標(72DPI、左下原点)位置に水平罫線を追加する(結果、指定したY座標にYグリッドが作成される) – 2 RATIO_TO_IGNORE_H_LINE 短い水平罫線を無視するかどうかの閾値。ページ幅に対する割合(N倍)で指定 0 3 DIVIDE_STRING_BY_BOX 文字列が罫線に囲まれている場合に、異なる矩形に属する文字は連結対象から外すかどうかのパラメータ 1 4 LINE_SEG_SPACE_RATE 接する2つの文字を1つの文字列として扱うかどうかの閾値。文字間の文字行の高さに対する比率で指定する 1.5 5 SET_MARGIN_BY_BOX 1つの矩形にアイテムが1つだけある場合に、そのアイテムのマージンを自動生成するかどうかを設定する 1 6 ONE_ITEM_IN_BOX 1つの矩形に1つだけ文字列がある場合に、完全一致(編集距離での許容は有効)する時のみ項目文字列として扱うかどうかを設定する 1 7 DP_COST_MAX 辞書照合判定の必要条件(絶対値):編集距離(*1)がこの値以下である場合は辞書に照合したとみなす 1 8 DP_COST_RATE 辞書照合判定の必要条件(相対値):許容する編集距離を照合対象の辞書単語と、抽出文字列のいずれか短い方に対する割合で指定 5 9 MIN_UPPER_SPACE_HEIGHT_TO_LINK 項目文字列と値文字列間で、リンク設定を行うかどうかの高さの差の閾値(絶対値) 文字高さの平均×2倍 10 MIN_LOWER_SPACE_HEIGHT_TO_LINK 項目文字列と値文字列間で、リンク設定を行うかどうかの高さの差の閾値(絶対値) 文字高さの平均×5倍 11 TABLE_ITEM_NUM_TO_IGNORE_WORDS 複数列にまたがる値文字列を無視するかどうかの閾値 2以上の場合有効となる 0 12 MAX_YGRID_GAP_TO_LINK 項目文字列と値文字列の縦方向のリンクを設定する場合に、許容するYグリッドの差分の閾値 1 13 RECORD_SEG_NODE_COUNT レコード分割を行う値文字列数の閾値 3 14 USE_LINE_NUM_OF_FIRST_LINK 項目文字列と値文字列のリンクを設定する場合に、間の罫線の本数を接続条件とするかどうかを設定する 1 15 IV_SYMBOL_REGEX_ID 同一文字行内に、項目文字列と値文字列が共存していると判定する場合の、項目-値の区切り文字の正現ID (?:[: ])+ 16 USE_HORIZONTAL_LINE_AS_LINE_BREAK 水平の罫線をレコード区切りとして利用するかどうかのパラメータ 1 17 LOGICAL_OPERATOR_FOR_REQUIRED_METADATA 複数のメタデータにREQUIREDを定義した場合に適用される条件を設定する 1 18 LINE_RECOGNITION (テキスト付きPDFのみ) 0 19 REMOVE_EXIST_LINE (テキスト付きPDFのみ) 0 20 DEFAULT_ERA DATE_YMD型で、年号が指定されておらず、かつ年が2桁の場合に設定する年号を指定する – 21 USE_LINE_DELIMITER_FOR_HORIZONTAL_CONCAT 横方向に連結する時は区切り文字を半角スペース固定としているが、行の連結に使用する区切り文字を横方向の連結にも使用できるようにするパラメータを追加する 0 22 IGNORE_CHAR_IN_KEYWORD 抽出キーワード検索時に対象外する文字を設定する – 23 IGNORED_KEYWORD 抽出キーワードの検索時、及び値の抽出時に対象外とする文字列を設定する – 24 NO_ADD_SPACE 入力文書に含まれる文字の文字間隔が一定の間隔である場合、通常は、文字の間に半角空白を埋め込むが、半角空白の埋め込みを抑止したい場合にこのパラメータを指定する – 25 KEYWORD_EXTRACT_LEVEL 抽出キーワードによる抽出された項目は、正規表現・データタイプに一致していない項目も全て出力される 0 26 CH_GRPH_SPACE_RATE_HORIZONTAL 抽出キーワードに指定された文字列の判定において、各文字間隔の許容値を指定する 指定値は文字の高さに対する倍率で指定する 5.0 27 MARGIN_BY_BOX_EXT SET_MARGIN_BY_BOXを有効にした場合、矩形内にキーワードのみある時にマージンが設定される 0 28 KEYWORD_RANGE_CHECK キーワード抽出のキーワード(マージン含む)と重なっている文字列を抽出対象とするか指定する 0 29 REMOVE_SPACE_FOR_REGEX_MATCH メタデータで適用正規表現と一致する文字列を検索する際に半角空白を無視するか指定する 0 30 KEYWORD_REG_EXT 抽出キーワードの正規表現一致時に正規表現で指定した記憶範囲による項目の置換を適用するか指定する 0 31 KEYWORD_DTY_EXT 抽出キーワードのデータタイプ判定において、データタイプに一致しなかった場合に、前後の文字列を削除して再判定するかを指定する 0
(1)USER_DEFINED_H_LINES
IDE_Libraryでは、項目と値のリンク付けにおいて罫線情報を参考に処理を行っています。本パラメータを指定することにより、指定位置に水平線が引かれているものとみなして処理を行います。フッタ部分など、表内の項目文字列と結び付けたくない文字列がある場合に使用します。
(2)RATIO_TO_IGNORE_H_LINE
罫線情報を活用した処理において、本パラメータで指定した長さ以下の罫線を無視するパラメータです。ページ幅に対する割合(N倍)で指定します。デフォルト値は0で、長さにかかわらずすべての罫線を分析に利用します。
(3)DIVIDE_STRING_BY_BOX
文字列が罫線に囲まれている場合に、罫線で文字列を分割するかどうかを指定します。
(1:有効(デフォルト)、0:無効)
1の場合、赤で囲まれた文字列はそれぞれ異なる矩形の中にあるので異なる文字列として認識されます。本機能により、P/O#を項目文字列として認識するための字間値調整が不要となります。
(4)LINE_SEG_SPACE_RATE
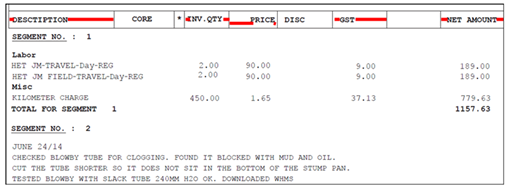
隣接する2つの文字を1つの文字列として扱うかどうかの閾値を指定します。文字間の文字行の高さに対する比率 で指定します。
デフォルト値(1.5)が設定されている場合、右記の例では、LとF, R と S の距離はL, Rの高さの1.5倍より小さいため、 “TOTAL FOR SEGMENT” は1つの文字列として扱われます。
注意:
(5)SET_MARGIN_BY_BOX
1つの矩形に抽出キーワードが1つだけある場合に、その文字列のマージンを自動生成するかを指定します。
(1:有効(デフォルト)、0:無効)
下記の例で、Description、INV.QTY、PRICE、GST、NETAMOUNTが抽出キーワードに登録されている場合、それらの左右のマージンを矩形から自動計算します。自動計算は一つの矩形に抽出キーワードが一つだけ存在する場合のみ行います。
注意:
分割位置が偶然スペースの場合はそこで分割されてしまうため、 (TABLE_ITEM_NUM_TO_IGNORE_WORDS )の指定で無視することができなくなる。
1つの矩形に1つだけ文字列がある場合に、完全一致(編集距離での許容は有効)する時のみ項目文字列として扱うかどうかを指定します。
(1:有効(デフォルト)、0:無効)
本パラメータが有効に設定されている場合、 右記の例でShipのみ抽出キーワードとして登録されていたとしても、Ship To:、Ship Via、Ship Dateの一部がShipとして扱われることはありません。
(7)DP_COST_MAX (8)DP_COST_RATE
辞書照合判定の必要条件を指定します(MAX:絶対値/RATE:相対値)。編集距離がこの値以下である場合は、抽出キーワードに合致したとして扱います。OCR処理での軽微な誤認識を許容することが主な目的です。
補足説明:
例)DP_COST_MAX = 2,DP_COST_RATE = 3, “keyword”が項目文字列として定義されている場合 Keyword -> マッチ (編集距離1)
(9)MIN_UPPER_SPACE_HEIGHT_TO_LINK (10)MIN_LOWER_SPACE_HEIGHT_TO_LINK
IDE_Libraryでは項目文字列と値文字列の間に一定以上の高さの空間が存在すると、それを超えてのリンク付けは行いません。その高さを本項目で指定できます(絶対値で指定)。単位はピクセルです。
本パラメータが設定されていない場合(デフォルト)は、ページ中のすべての文字列の高さの平均に対する割合
(11)TABLE_ITEM_NUM_TO_IGNORE_WORDS
複数の列にまたがる値文字列があった場合に、無視するかどうかの閾値を設定します。0また1が指定された場合は、複数列にまたがる値でも無視されません。
右記例の場合、注意:
(12) MAX_YGRID_GAP_TO_LINK
項目文字列と値文字列の間に含まれる罫線の数の閾値を指定します。ここで指定した値以上の水平罫線がある場合は、項目文字列と値文字列間のリンクを行いません。
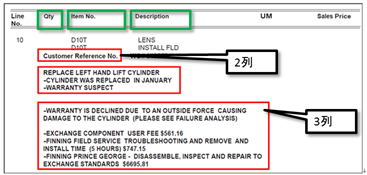
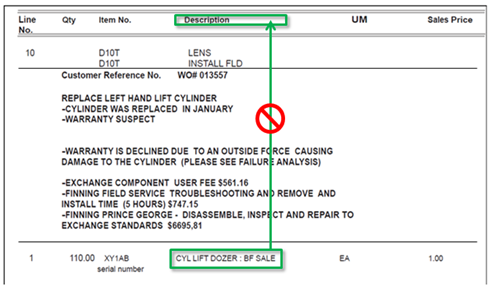
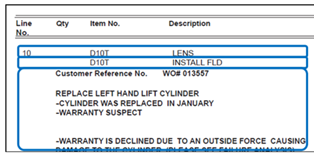
デフォルト値は”1”のため、下記例ではDescriptionの値としてCYL LIFT DOZER : BF SALEは抽出されません。
補足説明:
注意:
(13)RECORD_SEG_NODE_COUNT
レコード分割を行う値文字列数の閾値を指定します。
(14)USE_LINE_NUM_OF_FIRST_LINK
項目文字列-値文字列の連結を行う際に、項目文字列と最初の値文字列の間の罫線数を超えない範囲内でリンクを行うかどうかのパラメータです。
(1:有効(デフォルト)、0:無効)
1の場合、値文字列が項目文字列にリンクできるか判定する際、“最初の値との間の罫線の数”より多い場合はリンクを行いません。
(15)IV_SYMBOL_REGEX_ID
IDE_Libraryでは、下記条件に該当する場合に、項目文字列と値文字列が同一文字行内に共存していると判断し、分割処理を行います。
システムに定義された抽出キーワードと前方部分一致する 上記一致した部分の一文字右が、単語境界を示唆する文字(=IV_SYMBOL_REGEX_IDに定義した正規表現定義)に合致する 抽出キーワードと単語境界の記号を除いた文字列の長さが1文字以上
右記の例の場合、次の条件をすべて満たせば分割処理の対象となります。
(16)USE_HORIZONTAL_LINE_AS_LINE_BREAK
水平(横向き)の罫線を、レコードの区切りとして使用するかどうかのパラメータです。
(1:有効(デフォルト)、0:無効)
1の場合、水平(横向き)の罫線がある場合は、罫線の上下は異なるレコード(行)であると判断します。
(17)LOGICAL_OPERATOR_FOR_REQUIRED_METADATA
複数のメタデータにREQUIREDを定義した場合に適用される条件を設定します。
(1:AND条件、2:OR条件)
1の場合はAND条件となり、REQUIREDが指定されたメタデータすべてが値を持つレコードのみが抽出の対象となります。2の場合はOR条件となり、REQUIREDが指定されたメタデータのうち、1つでも値を持つメタデータのあるレコードが抽出の対象となります。
(18)LINE_RECOGNITION
メタデータ抽出の前処理として、イメージに含まれる罫線情報を抽出してPDFに埋め込む(追加する)処理を行うかどうかのパラメータです。
(1:有効、0:無効)
(19)REMOVE_EXIST_LINE
前述の罫線情報の付加を行う場合に、既存の罫線情報を削除するかどうかのパラメータです。
(1:有効、0:無効)
(20)DEFAULT_ERA
DATE_YMD型で、年号が指定されておらず、かつ年が2桁の場合に使用する年号を指定します。
R(全角)、R(半角)、令和、 H(半角)、平成
不正な値を設定した場合、フォーマット変換は行われません。
(21)USE_LINE_DELIMITER_FOR_HORIZONTAL_CONCAT
PDF上で文字の間のスペースが一定以上の幅があると、半角スペースを区切り文字として結合します。この区切り文字として半角スペースではなく、複数行連結時の区切り文字を使用する場合に指定します。デフォルトでは、半角スペースを使用します。
0: 区切り文字としてスペースを使用する
(22)IGNORE_CHAR_IN_KEYWORD
キーワード抽出の判定時に無視する文字を指定します。
(23)IGNORED_KEYWORD
抽出キーワードの検索時、及び値の抽出時に無視する文字列を指定します。
(24)NO_ADD_SPACE
入力文書に含まれる文字の文字間隔が一定の間隔である場合、通常は、文字の間に半角空白を埋め込みますが、半角空白の埋め込みを抑止したい場合にこのパラメータを指定します。0を指定すると、半角空白の埋め込みが行われなくなります。デフォルトは、「指定なし」で、文字間隔が一定の間隔である場合は、半角空白の埋め込みを行います。
例えば、「アライズ AIRead」という文字列があった場合、「アライズ」と「AIRead」の間(「ズ」と「A」の間)は、少し文字間隔があいています。実際に空白文字が入っている場合は、その空白文字は元々存在していた文字として扱われますが、空白文字が入っていない場合、空白文字を補います(ただし、文字間隔が一定の間隔である場合)。
本パラメータを「0」に指定することで、空白文字を補う動作を抑止することができます。
(25)KEYWORD_EXTRACT_LEVEL
抽出キーワードを用いてメタデータ抽出を行う際、正規表現、データタイプに基づいた絞り込みは行われません。
0: 従来同様候補全てを抽出します
(26)CH_GRPH_SPACE_RATE_HORIZONTAL
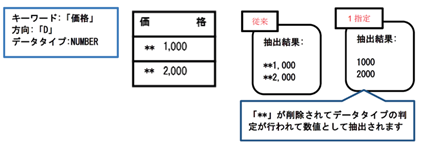
文字間隔が広い場合、文字列が抽出キーワードとして判定されないことがあります。
ただし、文字と文字の間に半角空白が含まれている場合等には、半角空白を含む文字列として判定されてしまいます。例えば、「価」と「格」の間に半角空白が存在する場合には、「価 格」となるため、事前に「価 格」を抽出キーワードとして定義しておく必要があります。または、「IGNORE_CHAR_IN_KEYWORD」、「NO_ADD_SPACE」のパラメータを指定し、半角スペースを削除するよう設定する必要があります。
(27)MARGIN_BY_BOX_EXT
SET_MARGIN_BY_BOXが有効な場合、表のヘッダ部にキーワード以外の文字が含まれていると列幅を考慮せずにメタデータの抽出が行われます。
0:矩形内にキーワードのみの時に有効
ただし、「KEYWORD_RANGE_CHECK」が指定されていない場合、上記例では、「価」を抽出キーワードとした際に、「格」がデータとして抽出されてしまいます。本パラメータの指定時には、併せて「KEYWORD_RANGE_CHECK」を指定することを推奨します。
(28)KEYWORD_RANGE_CHECK
抽出キーワードを用いてメタデータの抽出を行う際、キーワードの文字列付近の文字が誤って抽出されてしまう場合があります。
0:キーワードと重なる文字列も抽出します
(29)REMOVE_SPACE_FOR_REGEX_MATCH
メタデータに対して正規表現を割り当てて抽出を行う際、文字列から半角空白を取り除いた上で判定を行うかを指定します。
0:半角空白を取り除かず判定を行います
(30)KEYWORD_REG_EXT
抽出キーワードを用いてメタデータの抽出を行う際、メタデータに対して割り当てられた正規表現に記憶(()にて囲まれた記述)が含まれている場合、記憶された文字列のみを抽出するか指定します。
0:正規表現に一致した文字列をそのまま抽出します。
(31)KEYWORD_DTY_EXT
抽出キーワードを用いてメタデータの抽出を行う際、設定されたデータタイプにメタデータが一致しなかった場合に前後の文字列を削除して再判定するかを指定します。
0:前後の文字を削除することなく判定します。
4.5.4. データタイプの指定
メタデータ毎に値のデータ型(数字、通貨、日付等)を定義することができ、このデータ型をデータタイプと呼びます。メタデータ抽出時には、データ型に合致しているかどうかのバリデーションおよび抽出結果の整形を行います。
定義できるデータタイプの種類と、各データタイプの仕様を以下に示します。
No. データタイプ名 説明 出力フォーマット(*1) 1 STRING (文字列) デフォルトのデータタイプ – 2 STRING_FIRST_LINE (単一行文字列) 値が複数行の場合、1行目だけを抽出する 文字列のうち、1行目 3 STRING_FIRST_WORD 1行目の1語目だけを抽出する 文字列のうち、1行目の1語目 4 NUMBER 整数と小数 -{0,1}[0-9]+(\.[0-9]+)* 5 DOLLAR 米ドル、カナダドルなど、小数点付きの通貨 -{0,1}[0-9]+\.[0-9]{2} (*3) 6 DATE_YMD 日付(年、月、日) yyyy-mm-dd 7 DATE_MDY 日付(月、日、年) yyyy-mm-dd 8 DATE_DMY 日付(日、月、年) yyyy-mm-dd 9 PAGE ページ番号 pn /pc pn (ページ総数が取得できなかった場合)(*2)10 STRING_FIRST_LINE 固定桁数の文字列を抽出する 抽出文字列(必要に応じ空白を追加) 11 ALIAS 他のメタデータを複製する 他のメタデータの値 12 STRING_SINGLE_LINE 文字列中の指定行を抽出する 文字列の内、指定された行 13 YEN(円) 円(整数表記する通貨) -{0,1}[0-9]+
*1 : 抽出結果をこのフォーマットに整形します。
(1) STRING
デフォルトのデータタイプです。データタイプの指定がない場合は、STRINGとして扱われます。抽出結果のバリデーションおよび整形は行わず、抽出した結果をそのまま出力します。値が複数行にわたる場合は、連結して1つの値として出力します。その際、半角スペースが区切り文字として設定されます。
(2) STRING_FIRST_LINE
単一行文字列を表します。
(3) STRING_FIRST_WORD
単語を表します。
(4) NUMBER
数値(整数と小数)を表します。
No. 想定フォーマット 合致する例 1 -{0,1}[0-9]+ 123 2 -{0,1}[0-9]*\.[0-9]+ -5.00 3 -{0,1}[0-9]{1,3}(,[0-9]{3})* 1,890 4 -{0,1}[0-9]{1,3}(,[0-9]{3})*\.[0-9]+ -530,636.12 5 ([0-9]+) (420) 6 ([0-9]*\.[0-9]+) (236.32) 7 ([0-9]{1,3}(,[0-9]{3})*) (2,237) 8 ([0-9]{1,3}(,[0-9]{3})*\.[0-9]+) (1,100,000.00) 9 [0-9]+ -{0,1} 123- 10 [0-9]*\.[0-9]+ -{0,1} 5.00- 11 [0-9]{1,3}(,[0-9]{3})*-{0,1} 1,890- 12 [0-9]{1,3}(,[0-9]{3})*\.[0-9]+ -{0,1} 530,636.12- 13 <[0-9]+> <420> 14 <[0-9]*\.[0-9]+> <236.32> 15 <[0-9]{1,3}(,[0-9]{3})*> <2,237> 16 <[0-9]{1,3}(,[0-9]{3})*\.[0-9]+> <1,100,000.00>
抽出結果に含まれる”,(カンマ)”の位置が(数値表現として)誤っている場合、”,”はすべて削除し、フォーマットエラーとして扱います。 抽出結果に2つ以上の”.(ピリオド)”が含まれている場合、最も右にあるものを除いて”.”はすべて削除し、フォーマットエラーとして扱います。 “-(マイナス)”と1文字目または末尾の数字の間のスペース、カッコ前後のスペースは無視されます。 NUMBER型でサポートするのは、整数部分と小数部分合わせて16桁までです。16桁を超える場合、17桁目以降の値は保証対象外となります。 (5) DOLLAR
アメリカドル、カナダドル等、小数点以下1桁以上の通貨を表します。(小数点以下の桁数は、デフォルト2)
No. 想定フォーマット (*3) 合致する例 1 -{0,1}<DM>{0,1}[0-9]+\.[0-9]{2} $123.00 2 -{0,1}<DM>{0,1}[0-9]{1,3}(,[0-9]{3})*\.[0-9]{2} -$53,589.00 3 <DM>{0,1}-{0,1}[0-9]+\.[0-9]{2} $1,890.00 4 <DM>{0,1}-{0,1}[0-9]{1,3}(,[0-9]{3})*\.[0-9]{2} $-530,636.12 5 ({0,1}<DM>{0,1}[0-9]+\.[0-9]{2}) ($420.00) 6 ({0,1}<DM>{0,1}[0-9]{1,3}(,[0-9]{3})*\.[0-9]{2}) ($236,300.32) 7 <DM>{0,1}\( [0-9]*\.[0-9]{2}\) $(530.00) 8 <DM>{0,1}\([0-9]{1,3}(,[0-9]{3})*\.[0-9]{2}\) $(23,572.00) 9 <DM>{0,1}[0-9]+\.[0-9]{2}- $123.00- 10 <DM>{0,1}[0-9]{1,3}(,[0-9]{3})*\.[0-9]{2}- $53,589.00- 11 <DM>{0,1}[0-9]+\.[0-9]{2}(C|CR) $123.00CR 12 <DM>{0,1}[0-9]{1,3}(,[0-9]{3})*\.[0-9]{2}(C|CR) $53,589.00C 13 (C|CR)<DM>{0,1}[0-9]+\.[0-9]{2} CR$123.00 14 (C|CR)<DM>{0,1}[0-9]{1,3}(,[0-9]{3})*\.[0-9]{2} C$53,589.00 15 <DM>{0,1}(C|CR) [0-9]+\.[0-9]{2} $CR123.00 16 <DM>{0,1}(C|CR) [0-9]{1,3}(,[0-9]{3})*\.[0-9]{2} $C53,589.00 17 <{0,1}<DM>{0,1}[0-9]+\.[0-9]{2}> <$420.00> 18 <{0,1}<DM>{0,1}[0-9]{1,3}(,[0-9]{3})*\.[0-9]{2}> <$236,300.32>
(*3) <DM>部分に入る文字は、下記の通貨記号です。
抽出結果に含まれる”,(カンマ)”の位置が(数値表現として)誤っている場合、”,”はすべて削除し、フォーマットエラーとして扱います。 抽出結果に2つ以上の”.(ピリオド)”が含まれているか、ピリオドの位置が誤っている場合、すべての”.”を削除し、かつ指定された小数点以下の桁数となるように”.”を付加します。加えてフォーマットエラーとして扱います。また、”.(ピリオド)”および”,(カンマ)”をすべて削除すると抽出結果が小数点以下桁数未満になる場合、”.”の付加は行わずフォーマットエラーとして扱います。 “-(マイナス)”と”$(ドル)”の間のスペース、“-(マイナス)”と1文字目または末尾の数字の間のスペースは無視されます。 小数点以下の桁数は、本データタイプのオプションとして指定します。 DOLLAR型でサポートするのは、整数部分と小数部分合わせて16桁までです。16桁を超える場合、17桁目以降の値は保証対象外となります。 指定できる小数点以下の桁数に上限はありませんが(下限は1)、上述の制限事項を考慮に入れ、16-(整数部分の想定最大桁数)で設定することを推奨します。 注意:
(6) DATE_YMD
日付で、年、月、日の順のものを表します。年は西暦と和暦に対応します。
No. 想定フォーマット 合致する例 1 y/m/d 2015/1/16 2 y-m-d 15-1-16 3 y m d 2015 1 16 4 y.m.d 2015.1.16 5 g/m/d H27/1/16 6 g-m-d H27-1-16 7 g m d H27 1 16 8 g.m.d H27.1.16 9 g年m月d日 平成27年1月16日
なおy,m,dは日付(DATE)型で共通で、javaのYear、Month、Numberフォーマットの仕様にそれぞれ準拠します。
(7) DATE_MDY
日付で、月、日、年の順のものを表します。
No. 想定フォーマット 合致する例 1 m/d/y 2/21/2015 2 m-d-y 02-21-15 3 m d y February 21 2015 4 m.d.y Feb.21.2015 5 m d,y February 21,2015
(8) DATE_DMY
日付で、日、月、年の順のものを表します。
No. 想定フォーマット 合致する例 1 d/m/y 31/03/2015 2 d-m-y 31-Mar-2015 3 d m y 31 March 15 4 d.m.y 31.3.2015 5 d.m y 31.March 2015
(9) PAGE
ページ番号(pn)とページ総数(pc、ある場合)を表します。
No. 想定フォーマット 合致する例 1 pn/pc 1/5 2 pn / pc 1 / 5 3 pn of pc 1 of 5 4 pn (pc) 1 (5) 5 pn 1
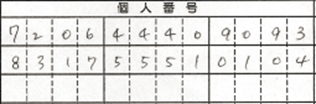
pnとpcの値の妥当性(pn ≦ pc)はチェックしていません。抽出した値をそのまま返します。 (10) STRING_FIRST_LINE_FIXED_COLUMN
固定桁数の文字列を表し、値内に空白がある場合はその位置に半角スペースを埋めて出力します。例を以下に示します。
該当するメタデータは、抽出キーワード、値(固定桁数分揃った場合)とも同じ幅であることを前提とします(上記例の場合は、「個人番号」が枠いっぱいの幅で出力されている必要があります)、個々の値はその幅内に均等に出力されているものと仮定して処理を行います。
(11) ALIAS
別のメタデータの値を複製することを表します。抽出結果にかかわらず、指定されたメタデータの値をすべてコピーして値とします。
(12) STRING_SINGLE_LINE
文字列のうち、指定された行の値のみを抽出することを表します。行番号として、1以上の整数または-1が指定でき、-1は最終行を示します。指定された行が抽出結果に存在しない場合(3を指定したが、値が2行しかない場合)は、抽出結果はnullとなります。
(13) YEN
日本円を表します。
No. 想定フォーマット (*3) 合致する例 1 ^(-|―|ー|-|CR|C)? ? <YM> ?[0-9]+ $ ¥1000, -¥1000 2 ^(-|―|ー|-|CR|C)? ? <YM> ?[0-9]{1,3}(,[0-9]{3})* ¥1,000,-¥1,000 3 ^<YM> ?(-|―|ー|-|CR|C)? ?[0-9]$ ¥1000, ¥-1000 4 ^<YM> ?(-|―|ー|-|CR|C)? ?[0-9]{1,3}(,[0-9]{3})* ¥1000, -¥1000 5 ^(-|―|ー|-|CR|C)? ?[0-9]+ ? <YM>$ 1000円, -1000円 6 ^(-|―|ー|-|CR|C)? ?[0-9]{1,3}(,[0-9]{3})* ? <YM>$ 1,000円, -1,000円 7 ^<YM> ?[0-9]+ ?(-|―|ー|-)?$ ¥1000, ¥1000- 8 ^<YM> ?[0-9]{1,3}(,[0-9]{3})* ?(-|―|ー|-)?$ ¥1,000, ¥1,000- 9 ^\\( ? <YM> ?[0-9]+ ?\\)$ (¥1000) 10 ^\\( ? <YM> ?[0-9]+ ?\\)$ ¥(1000) 11 ^\\( ? <YM> ?[0-9]{1,3}(,[0-9]{3})* ?\\)$ (¥1,000) 12 ^<YM> ?\\( ?[0-9]{1,3}(,[0-9]{3})* ?\\)$ ¥(1,000) 13 ^\\( ?[0-9]{1,3}(,[0-9]{3})* ? <YM> ?\\)$ (1,000円) 14 ^\\( ?[0-9]{1,3}(,[0-9]{3})* ?\\) ? <YM>$ (1,000)円 15 ^< ? <YM> ?[0-9]+ ?>$ <¥1000> 16 ^< ? <YM> ?[0-9]+ ?>$ ¥<1000> 17 ^< ? <YM> ?[0-9]{1,3}(,[0-9]{3})* ?>$ <¥1,000> 18 ^<YM> ?< ?[0-9]{1,3}(,[0-9]{3})* ?>$ ¥<1,000> 19 ^< ?[0-9]{1,3}(,[0-9]{3})* ? <YM> ?>$ <1,000円> 20 ^< ?[0-9]{1,3}(,[0-9]{3})* ?> ? <YM>$ <1,000>円
(*3) <YM>部分に入る文字は、下記の円記号です。
抽出結果に含まれる”,(カンマ)”の位置が(数値表現として)誤っている場合、”,”はすべて削除し、フォーマットエラーとして扱います。 抽出結果に”.(ピリオド)”が含まれている場合、すべての”.”を削除しフォーマットエラーとして扱います。 “-(マイナス)”と”¥”の間のスペースは無視されます。 YEN型でサポートするのは16桁までです。16桁を超える場合、17桁目以降の値は保証対象外となります。 補足情報:
No. オリジナルデータ 修正後の文字 1 ! 1 2 | 1 3 | 1 4 I 1 5 l 1 6 i 1 7 B 8 8 O 0 9 o 0 10 @ 0 11 - – 12 ― –
(14) SUB_KEYWORD_DIR (15) SUB_KEYWORD_NEAR
指定したメタデータで「DATATYPE_VALUE」パラメータの指定を行うことができます。
4.6. システム設定 “項目名=値”の書式で記載します。
ファイル名:<AIREAD_HOME>\IDELibrary\dicset\conf\kme.conf No. キー名 内容 指定 補足 1 JAVA_EXE_PATH Javaコマンドのパス 必須 絶対パス 2 DUMP_ELEM_JAR_PATH DumpElem.jarファイルのパス 任意(*) 絶対パス 3 DUMP_ELEM_PY_PATH DumpElem.pyファイルのパス 任意(*) 絶対パス 4 MKDARTS_ITEM_COMMAND_PATH mkdarts-itemファイルのパス 必須 絶対パス 5 TIMEOUT_DEFAULT 抽出処理メソッドのタイムアウトデフォルト値(単位:ミリ秒) 任意 設定なしの場合、5000 (5秒) 6 DELETE_TEMPFILE_DURING_INIT 中間ファイルを削除するかどうかのパラメータ 任意 設定なしの場合、true(削除する) 7 KEYWORD_SPACE_DEL 文書種別判定を行う際、文書内の文字列に含まれる半角空白・全角空白を無視するかどうかを指定 任意 設定なしの場合、false 8 KEYWORD_REG_USE 文書種別判定を行うためのキーワードセットに指定した文字列を正規表現として解釈するようにするかどうかを指定 任意 設定なしの場合、false 9 KEYWORD_CR_DEL 文書種別判定を行う際、文書内の文字列に含まれる改行コードを無視するかどうかを指定する 任意 設定なしの場合、false