1. 概要
本ソフトウェアは、画像に含まれる文字を認識してテキストファイルへ出力します。
あらかじめ座標を指定した範囲について文字を認識します。
1.1. サポートしている画像形式
サポートしている画像ファイル形式は以下の通りです。
| 画像 (拡張子) | Windows>ファイル「プロパティ」での表示 |
|---|
| PDF ※ | |
| jpeg ( .jpeg, .jpg ) | |
| png ( .png ) | |
| Tiff LZW圧縮 ( .tif, .tiff ) | LZW |
| Tiff ZIP圧縮 ( .tif, .tiff ) | – |
| Tiff Packbits圧縮 ( .tif, .tiff ) | Packbits |
| Tiff CCITT T6圧縮 ( .tif, .tiff ) | CCITT T6 |
| Tiff CCITT T4JPEG圧縮 ( .tif, .tiff ) | CCITT T4 |
| Tiff 圧縮しない ( .tif, .tiff ) | 圧縮しない |
※PDFは中に含んでいる画像がサポートしていない形式の場合は対象外となります。
| 画像 (拡張子) | Windows>ファイル「プロパティ」での表示 |
|---|
| jpeg2000 ( .jp2 ) | |
| gif ( .gif ) | |
| bitmap ( .bmp ) | |
| Tiff JPEG圧縮 ( .tif, .tiff ) | JPEG |
2. 実行手順
2.1. 処理フロー
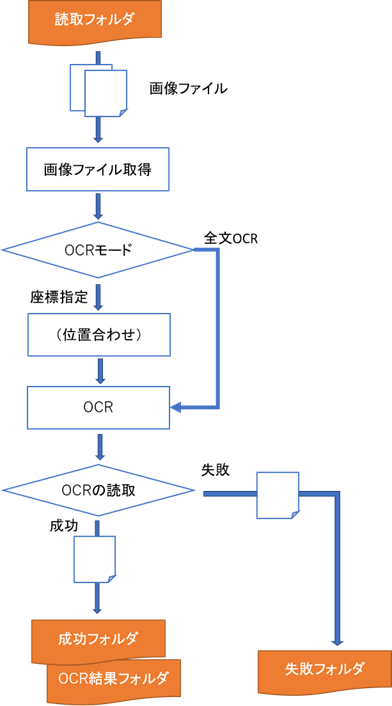
2.2. 実行方法
Standard版では、全文OCR、座標指定OCRの2種類の実行方法があります。
それぞれの機能と起動方法の違いは次の通りです。
2.2.1. 座標指定OCRの実行
画像中の指定した箇所に対してOCRを行ってテキストデータ化します。
対象文字種は活字・手書きの両方です。
以下のコマンドで実行します。
| "%AIREAD_JAVA%/java" -jar ./IDELibrary/lib/AIReadEE.jar -s [SettingFile] -C [FormID] |
| No. | 引数 | 説明 |
|---|
| 1 | -s [SettingFile] | 共通設定ファイルを指定
※共通設定ファイルの作成方法は3. 共通設定を参照 |
| 2 | -C [FormID] | 座標指定モードでフォームIDを指定して実行
※定義の作成方法は4. フォーマット定義を参照 |
※run.bat はサンプル帳票の実行ファイルです。ダブルクリックで実行できます。
2.2.2. 全文OCRの実行
画像中の文字列を探索し、見つかった全ての文字列にOCRを行ってテキストデータ化します。
対象文字種は活字のみです。
なお、全文OCRはGUIから実行することはできません。
本設定で主に利用する表検出付きOCRの詳細は3.4.4 表検出付全文OCRをご参照ください。
以下のコマンドで実行します。
| "%AIREAD_JAVA%/java" -jar ./IDELibrary/lib/AIReadEE.jar -W -s [SettingFile] -p [FormID] |
| No. | 引数 | 説明 |
|---|
| 1 | -W | 全文OCRを実行する |
| 2 | -s [SettingFile] | 共通設定ファイルを指定
※設定ファイルの作成方法は3. 共通設定を参照 |
| 3 | -p [FormID] | (任意)FormIDを指定 FormIDを指定すると、座標指定時と同じ方法で個別設定が可能となる
※個別設定ファイルの配置方法は4.1フォーマット定義フォルダの構成を参照 |
※run_whole_ocr.bat はサンプル帳票の実行ファイルです。ダブルクリックで実行できます。
3. 共通設定
3.1. AIRead ControlPanelで設定
以下のプログラムを起動することで、AIRead ControlPanel(以下ControlPanel)にて共通設定ファイルを編集することができます。
<AIReadインストールフォルダ>/ControlPanel/AIReadControlPanel.exe
共通設定ファイル名は以下の通りです。
Standard (座標指定) :AIRead_setting.ini
Enterprise(ルール指定):AIRead_setting_kw.ini
共通設定ファイルには“項目名=値”の書式で定義されます。
共通設定ファイルはUTF-8で保存する必要があります。
3.1.1. 基本設定
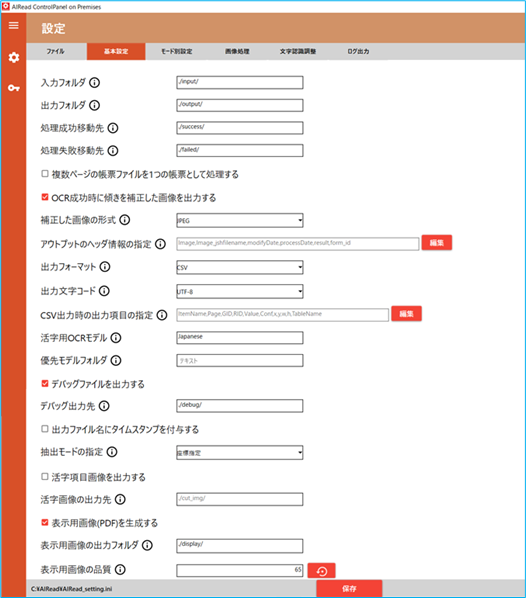
ファイルの入出力や抽出モードに関わる設定を行います。
| No. | 内容 | 項目名 | 書式 | 説明 |
|---|
| 1 | 入力フォルダ | INPUT | 文字列 | 画像を取り込むフォルダパス |
| 2 | 出力フォルダ | OUTPUT | 文字列 | OCR結果を出力するフォルダパス |
| 3 | 処理成功移動先 | MOVE_SUCCESS_DIR | 文字列 | OCR処理に成功した画像を格納するフォルダパス |
| 4 | 処理失敗移動先 | MOVE_FAILED_DIR | 文字列 | OCR処理に失敗した画像を格納するフォルダパス |
| 5 | 複数ページの帳票ファイルを1つの帳票として処理する | FILE_IDENFICATION_TYPE | 0, 1 | 帳票を識別する単位
・チェックなし(0):ページ単位で帳票を識別して処理する
・チェックあり(1):1ページ目で帳票を識別し、1ファイルすべてのページを1つの帳票として処理する
CORRECT_MOVED_FILE がtrueかつ、MOVED_FILE_FORMAT の出力形式がJPEGのとき、複数のJPEGを出力する |
| 6 | OCR成功時に傾きを補正した画像を出力する | CORRECT_MOVED_FILE | true, false | チェック(true)の時、OCR成功時に成功フォルダ(MOVE_SUCCESS_DIR)に移動する画像を天地・傾き補正後画像にする
(位置合わせ補正は行われない) |
| 7 | 補正した画像の形式 | MOVED_FILE_FORMAT | PDF, JPEG | CORRECT_MOVED_FILE が true の時に出力する画像のフォーマットを指定する
(デフォルト PDF)
<以下はEnterpriseのみ>
「複数ページの帳票ファイルを1つの帳票として処理する」を指定している場合は常にPDF出力となる |
| 8 | アウトプットヘッダ情報の指定 | HEADER_ITEM | 文字列 | アウトプットファイルへ出力するヘッダ情報の項目とその順番を指定可能
※各項目の説明は5.1 共通を参照 |
| 9 | 出力フォーマット | OUTPUT_FORMAT | CSV
XML
CSV4DB
XMLWAGBY
SIMPLE_CSV SIMPLE_SEPARATE_CSV
SIMPLE_TXT SIMPLE_SEPARATE_TXT | OCR読取結果の出力形式を選択する
<Standard/Enterprise共通>
・CSV
・XML
<Standardのみ>
・CSV4DB(DB連携のしやすいCSVフォーマット)
・XMLWAGBY(Wagbyフォーマット)
<Standard全文OCRのみ>
・SIMPLE_CSV (画像の見た目に近い出力)
・SIMPLE_SEPARATE_CSV (画像の見た目に近い出力、表ごとに1つのCSVを出力)
・SIMPLE_TXT (SIMPLE_CSVのタブ区切りになったもの)
・SIMPLE_SEPARATE_TXT (SIMPLE_SEPARATE_CSVのタブ区切りになったもの)
※SIMPLE_CSV(TXT)・SIMPLE_SEPARATE_CSV(TXT)については3.4.4 表検出付全文OCRを参照 |
| 10 | 出力文字コード | OUTPUT_ENCODING | UTF-8
Shift_JIS
EUC-JP
UTF-8with BOM | 出力ファイルの文字コードを選択する
(出力フォーマットがCSV、CSV4DBの場合) |
| 11 | CSV出力時の出力項目の指定 | CSV_COLUMN_ITEM | 文字列 | CSVへ出力する項目とその順番を指定可能。 ※各出力項目の説明は5.2 CSVを参照 |
| 12 | 活字用OCRモデル | OCR_LANG | 文字列 | 活字OCRエンジンで利用するモデル名
OCRモデルフォルダに存在するファイルの拡張子”.traineddata”を除外したファイル名を指定する
例)Japanese.traineddata → Japanese |
| 13 | 優先モデルフォルダ | PRIORITY_MODEL_PATH | 文字列 | 優先モデルフォルダとして指定するフォルダパス
※モデルは下記のフォルダ構成で配置すること※
[優先モデルフォルダ]\tessdata\[任意のモデル]
指定したフォルダ内のモデルを優先して使用し、指定されたモデルが存在しない場合、共通のモデルフォルダから使用する
個別設定と組み合わせることで、帳票ごとに優先モデルと共通モデルの使い分けができる |
| 14 | デバッグファイルを出力する | IS_DEBUG | true, false | チェック(true)の時、DEBUG_PATHで設定されたフォルダへデバッグ情報を出力する |
| 15 | デバッグ出力先 | DEBUG_PATH | 文字列 | デバッグファイルを出力するフォルダパス |
| 16 | 出力ファイル名にタイムスタンプを付与する | MOVED_FILE_NAME | 0,1 | チェック(1)の時、抽出処理完了後の出力ファイル名にタイムスタンプを付与する |
| 17 | 抽出モードの設定 | COMPONENT_LEVEL | MANUAL
ITEM
CELL | 抽出モードを選択する
・MANUAL : 座標指定
・ITEM : キーワード指定
・CELL : キーワード指定(表検出付き)
※全文OCR時はキーワード指定・キーワード指定(表検出付き)を選択
※キーワード指定(表検出付き)の詳細については3.4.4 表検出付全文OCRを参照 |
| 18 | 活字項目画像を出力する | CREATE_PR_COMP_IMAGE | true, false | チェック(true)の時、活字として読み取った範囲の切取画像を出力する
(デフォルト false) |
| 19 | 活字画像の出力先 | PR_CUT_IMAGE_DIR | 文字列 | 活字項目画像を出力するフォルダパス |
| 20 | 表示用画像(PDF)を生成する | CREATE_DISPLAY_IMAGE | true, false | チェック(true)の時、データサイズを減らしたPDFを生成する
天地補正・傾き補正後(位置合わせ無し)の画像がPDFに埋め込まれる
入力ファイルが複数ページの場合、FILE_IDENFICATION_TYPEに関係なく複数ページのPDFを生成する |
| 21 | 表示用画像の出力フォルダ | DISPLAY_IMAGE_DIR | 文字列 | 生成した表示用PDFを出力するフォルダパス
(デフォルト:指定なし、CREATE_DISPLAY_IMAGE=trueのとき指定必須) |
| 22 | 表示用画像の品質 | DISPLAY_IMAGE_QUALITY | 1~100 | 生成する表示用PDFの品質を指定する
指定した値が低いほど画像品質は下がるが、データサイズも小さくなる
(デフォルト 65) |
3.1.2. モード別設定
モード別(座標指定、キーワード指定)のパラメータを設定します。

3.1.2.1. 座標指定モード
<Standardのみ>
座標指定OCRを実行時の設定はこちらで行います。
| No. | 内容 | 項目名 | 書式 | 説明 |
|---|
| 1 | フォーマットフォルダ | PROFILE_CONFIG_DIR | 文字列 | <Standardのみ>
フォーマット定義フォルダのパス |
| 2 | 手書き用OCRモデル | HAND_WRITE_OCR_LANG | 文字列 | 指定された手書きモデルが存在しないときに使用するモデル名
“OCR_MODEL_PATH/tessdata/”以下に存在するフォルダ名
例)jpn |
| 3 | 改善した手書きの文字切り取りロジックを使用する | USE_SEGMENT_MODEL | true, false | フリーピッチで複数行の手書き文字を読み取る場合はチェック(true)する
※処理時間がチェックをしない場合と比べて1.5~2.5倍ほど増加する |
| 4 | OCR結果にスペースを含める | EXPORT_SPACE | true, false | チェック(true)の時、OCR結果にスペースを含める
(活字読み取り時のみ) |
| 5 | 手書き画像の出力先 | HW_CUT_IMAGE_DIR | 文字列 | 手書き項目/文字画像を出力するフォルダパス |
| 6 | 手書き項目画像を出力する | CREATE_HW_COMP_IMAGE | true, false | チェック(true)の時、手書きで座標指定した範囲の切取画像を出力する |
| 7 | 手書き文字画像を出力する | CREATE_HW_CHAR_IMAGE | true, false | チェック(true)の時、手書きで座標指定した範囲内の文字単位の切取画像を出力する |
| 8 | 文字を置換する信頼度(手書き) | HW_REPLACE_THRESH | 0~100 | 手書きの項目が指定された閾値未満の信頼度の時、任意の文字に変換する |
| 9 | 置換後の文字 | HW_REPLACE_CHAR | 文字列 | No. 8(HW_REPLACE_THRESH)で変換する文字(1文字) |
| 10 | 位置合わせ矩形の認識マージン | FORMAT_MARGIN | 0以上 | 位置合わせ時に大きな矩形を認識しない画像端(上下左右)からの範囲を指定する
単位はピクセル
(デフォルト 15) |
| 11 | 活字のノイズ閾値 | PRINT_NOISE_FILTERS | -1~100 | 活字の認識で、項目中の最大文字高さに対して指定された閾値以下の文字をノイズとして除去する
例)
30 を指定 → 読み取り範囲内の最大文字に対し30%以下の高さの文字をノイズとみなして除去する
(デフォルト -1:本機能は動作しない)
※小さい文字や記号がノイズとして削除される可能性有り |
| 12 | 手書きノイズの閾値 (文字の高さ、複数文字指定時) | HW_NOISE_FILTERS | 文字列 | 手書き文字の認識で指定したモデルについて、項目中の最大文字高さに対して任意の割合以下の文字をノイズとして除去する
手書き文字の文字数を「複数」で設定した項目を対象とする
[モデル名]:[閾値(%)]の形式で記載する
カンマ区切りで複数指定可能
例) number:25,money:30
→ 数値モデルは25%、通貨モデルは30%の高さの文字をノイズとみなして除去する
※小さい文字や記号がノイズとして削除される可能性があります |
| 13 | 手書きノイズの閾値 (白画素の割合、1文字指定時) | HW_WHITE_THRESHOLD | 0~1.0 | 手書き項目に1文字指定をしているとき、 その項目画像を読取対象外(ノイズ)と判断する白ピクセルの割合と判断する閾値を指定する
例)
0.99 を指定 → 手書き項目が1文字指定のとき、項目内の白ピクセルの割合が99%以上であれば、項目内の記載をノイズと判断して除去する
(デフォルト 0.975) |
3.1.2.2. キーワード指定モード
<Enterpriseのみ>
キーワード指定実行時の設定はこちらで行います。
<Standard/Enterprise共通>
全文OCRを実行時の一部の設定もこちらで行います。
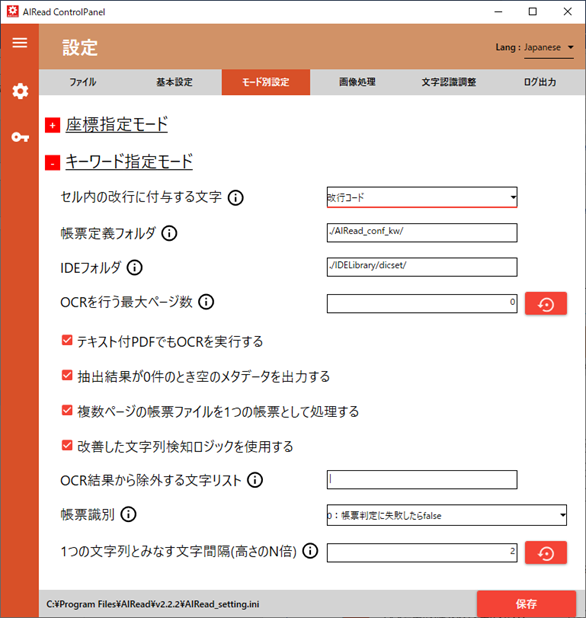
| No. | 内容 | 項目名 | 書式 | 説明 |
|---|
| 1 | セル内の改行に付与する文字 | LINE_SEPARATER | SPACE
LF
NONE | <抽出モードの設定=キーワード指定(表検出付き)のみ指定>
認識されたセル中の文字列が改行されていた場合、行間に付与する文字を指定する
改行コードを指定した場合、LF(\n)が付与される |
| 2 | 帳票定義フォルダ | PROFILE_KWCONFIG_DIR | 文字列 | <Enterpriseのみ>
帳票定義フォルダのファイルパス |
| 3 | IDEフォルダ | IDE_DIR | 文字列 | <Enterpriseのみ>
IDELibraryフォルダのパス
“?”区切りで文書種別を指定可能
※「帳票識別(DEFAULT_PROFILE_MODE)」が 1 or 2 の場合に有効
例)
./IDELibrary/dicset/?Invoice |
| 4 | OCRを行う最大ページ数 | PROC_MAX_PAGE | 0以上の整数 | <Enterpriseのみ>
OCRを実行する最大ページ枚数
例)
MAX_PAGE=1 → 2ページ目以降は無視する
0の場合は全ページが対象 |
| 5 | テキスト付きPDFでもOCRを実行する | OCR_PDF_WITH_TEXT | true, false | <Enterpriseのみ>
チェックあり(true):テキスト付きPDFの場合でもOCRを実行する
チェックなし(false):PDFのテキスト情報を使用して抽出する |
| 6 | 抽出結果が0件のとき空のメタデータを出力する | LAYOUT_TYPE | 0, 1 | <Enterpriseのみ>
0:空のメタデータは出力しない
1:空のメタデータを出力する
※明細は空の場合出力しない |
| 7 | 改善した文字列検知ロジックを使用する | USE_DL_STRING_DETECTION | true, false | チェック(true)の時、従来のOCRよりも文字列検知の改善した処理を行う
※メモリの使用量が約500MB程度増加し、処理時間がA4画像1枚当たり5秒/枚ほど増加する
※文字列検知の処理が従来のものと変更となるため、読み取り結果に影響する可能性有り |
| 8 | OCR結果から除外する文字リスト | BLACK_LIST_EXT | 文字列 | <Enterpriseのみ>
抽出処理時にキーワードおよび抽出する値から除外する文字を指定する |
| 9 | 帳票識別 | DEFAULT_PROFILE_MODE | 0~2 | <Enterpriseのみ>
帳票識別の動作を指定する
0:帳票識別に失敗したらfalse
1:帳票識別に失敗したら、指定した文書種別定義で抽出
2:指定した文書種別定義で抽出(帳票識別なし)
例)
IDE_DIRへ”?”区切りで記載する
例)IDE_DIR=./dicset/?invoice |
| 10 | 1つの文字列とみなす文字間隔 | LINKED_ITEM_THRESHOLD | 数値 | <Enterpriseのみ>
1つの文字列とみなす文字の間隔を設定
値は文字の大きさ(高さ)に対する倍率 |
3.1.3. 画像処理
文字認識の前に実施する画像処理関連の設定を変更します。

| No. | 内容 | 項目名 | 書式 | 説明 |
|---|
| 1 | ノイズ除去を行う | DE_NOISE | true, false | ノイズ除去処理の有無
チェック(true)の時、文字認識前にノイズ除去を行う |
| 2 | 傾き補正を行う | IS_SLOPE_CORRECTION | true, false | チェック(true)の時、文字認識前に傾き補正を行う(35度まで) |
| 3 | 回転補正を行う | AUTO_ROTATION | true, false | チェック(true)の時、文字認識前に90/180/270度の画像回転補正を行う |
| 4 | 罫線除去を無効化する | SKIP_LINE_REMOVE | true, false | チェック(true)の時、文字認識前の罫線除去を無効化する(罫線除去は行わない) |
| 5 | 直線除去を行う最短の長さ | LINE_REMOVAL_THRESHOLD | 0以上の整数 | 直線とみなす長さのしきい値(ピクセル)
0の場合、文字の大きさから自動で設定する |
| 6 | 点線除去を行う最短の長さ | HOUGH_THRESHOLD | 0以上の整数 | 点線とみなす長さのしきい値(ピクセル) |
| 7 | 罫線除去で欠けてしまった文字の復元処理を行う | RESTORE_TEXT | true, false | チェック(true)の時、罫線除去時に欠けてしまう罫線と隣接した文字を復元する
※必ず復元できるわけではない
※副作用として文字にノイズがつく場合がある |
| 8 | 二値化の閾値 | THRESH_VALUE | 0~255 | 文字認識前の画像の二値化(白黒化)のしきい値
0の場合、画像全体のヒストグラムから自動で設定する
詳細は3.4.1. 二値化の閾値を参照 |
| 9 | 直線除去時の二値化の閾値 | BINTHRESH_ON_LINE_REMOVAL | 0~255 | 直線除去時の二値化パラメータのしきい値
0の場合、画像全体のヒストグラムから自動で設定する |
| 10 | 白黒反転処理を実施する黒の比率 | BLACK_WHITE_THRESHOLD | 0~100 | 二値化後に白黒を反転するしきい値(%)
設定した%より黒の割合が多い場合に白黒を反転する |
| 11 | シャープ補正値 | SHARPEN_VALUE | 0以上の少数 | OCR実行前に画像をシャープ化する
画像がぼやけている場合などに利用すると効果的
0の場合は処理しない |
| 12 | 短い罫線(横)除去の閾値 | SHORT_LINE_THRESH_H | -1以上 | 長い罫線に接している短い罫線(横)を検知・除去する閾値
罫線の長さ(ピクセル)を指定する
-1 : 除去を行わない
0 : 除去を行わない(-1と同じ)
1以上 : この値を直線検知の閾値とする |
| 13 | 短い罫線(縦)除去の閾値 | SHORT_LINE_THRESH_V | -1以上 | 長い罫線に接している短い罫線(縦)を検知・除去する閾値
罫線の長さ(ピクセル)を指定する
-1 : 除去を行わない
0 : 除去を行わない(-1と同じ)
1以上 : この値を直線検知の閾値とする |
| 14 | 短い点線も除去する | USE_SHORT_DOTLINE_REMOVAL | true, false | チェック(true)の時、短い罫線除去時に点線も除去対象とする
※処理時間がA4画像1枚当たり2秒ほど増加する
※文字が除去される副作用が発生する可能性がある |
| 15 | 細かいノイズ除去の閾値(幅) | THIN_LINE_REMOVAL_THRESHOLD_W | 0以上 | 指定した幅(ピクセル)より細かいノイズを除去する
値が大きいほど大きなサイズのノイズを除去する
(デフォルト 0、推奨値 3)
詳細は3.4.2. 細かいノイズ除去を参照 |
| 16 | 細かいノイズ除去の閾値(高さ) | THIN_LINE_REMOVAL_THRESHOLD_H | 0以上 | 指定した高さ(ピクセル)より細かいノイズを除去する
値が大きいほど大きなサイズのノイズを除去する
(デフォルト 0、推奨値 3)
詳細は3.4.2. 細かいノイズ除去を参照 |
| 17 | 細かいノイズ除去の縮小フィルタ(幅) | ERODE_THIN_LINE_W | 1以上 | 細かいノイズ除去の収縮処理のフィルターサイズ(幅)
値が大きいとより独立したノイズのみ除去する
(デフォルト 12)
詳細は3.4.2. 細かいノイズ除去を参照 |
| 18 | 細かいノイズ除去の縮小フィルタ(高さ) | ERODE_THIN_LINE_H | 1以上 | 細かいノイズ除去の収縮処理のフィルターサイズ(高さ)
値が大きいとより独立したノイズのみ除去する
(デフォルト 7)
詳細は3.4.2. 細かいノイズ除去を参照 |
| 19 | TIFFを300DPIに変換してからOCRを実行する | CONV_TIFF_DPI | true, false | チェック(true)の時、TIFFを300DPIに変換してからOCRを実行する
TIFFで縦横のDPIが異なる場合に指定する |
| 20 | 抽出する色 | EXTRACTION_COLORS | 文字列 | 抽出する色を指定する(指定した色以外を除去する)
複数色を指定する場合はカンマ区切りで記載する
例) EXTRACTION_COLORS=K,R
指定可能な色
・K(黒)
・R(赤)
・Y(黄)
・G(緑)
・C(シアン)
・B(青)
・P(紫)
個別で指定する場合は、直接数値を指定
詳細は3.4.5. 色の抽出・除去を参照 |
| 21 | 除去する色 | REMOVAL_COLORS | 文字列 | 除去する色を指定する
指定方法は色抽出(EXTRACTION_COLORS)と同様
抽出する色と両方指定した場合は抽出を優先する
詳細は3.4.5. 色の抽出・除去を参照 |
| 22 | 色抽出・除去を罫線除去の前に行う | FILTER_COLOR_BEFORE_LINEREMOVAL | true, false | チェック(true)の時、罫線除去の前に色抽出・除去を行う |
| 23 | 罫線を延長する長さ | LINE_EXTENSION_LEN | 0以上 | 検知した罫線を延長する
単位はピクセル
(デフォルト 0) |
| 24 | 矩形の丸い角を除去する閾値 | ROUNDED_CORNER_THRESHOLD | 0~100 | 半径が指定した値未満の丸い角を除去する
単位はピクセル
0の場合は除去されない
(デフォルト 0)
詳細は3.4.3. 丸い角の除去を参照 |
| 25 | 丸い角の除去範囲を拡張する長さ | ROUNDED_CORNER_PADDING | 0~100 | 丸い角を除去する際に、指定した値分の除去範囲を拡大する
単位はピクセル
(デフォルト 10)
詳細は3.4.3. 丸い角の除去を参照 |
| 26 | ドット背景除去を行う | REMOVE_DOTTED_BACKGROUND | true, false | チェック(true)の時、ドット背景除去を行う |
| 27 | ドットサイズ | DOT_SIZE_THRESHOLD | 1~10 | ドット背景除去時の削除するドットのピクセルサイズを指定する
縦横が指定したピクセル以下のものを削除する
(デフォルト 4) |
3.1.4. 文字認識調整
文字認識に関する設定を変更します。
| No. | 内容 | 項目名 | 書式 | 説明 |
|---|
| 1 | 文字列の切取ロジック | PAGE_SEG_MODE | 4, 6 | OCRエンジンの活字文字検知/分割アルゴリズムを指定する
・4 : 1行内の文字サイズが可変とみなして文字を検知
・6 : 1行内の文字サイズが固定とみなして文字を検知 |
| 2 | 文字の多重認識を減らす処理を行う | use_dup_char_reducer | true, false | 複数の同じ文字が連続で出力されてしまうとき、本設定を有効にすることで回避できる(活字のみ)
※文字間が近い場合、複数文字を1文字として出力してしまう副作用が起きる可能性がある
・チェックする(true) : 機能を有効にする
・チェックしない(false) : 機能を無効にする |
| 3 | 対象文字種 | reduce_target | 0~4 | 「文字の多重認識を減らす処理を行う(use_dup_char_reducer)」の対象となる文字種を指定する
・0 : 数字
・1 : 記号
・2 : ひらがな
・3 : カタカナ
・4 : アルファベット
カンマ区切りで複数指定可能 |
| 4 | 再読み込みの閾値 | RESCAN_THRESHOLD | 0~100 | 指定した値よりもコンポーネントのConf値が閾値より低い場合に読み直す(活字のみ)
※コンポーネント内の文字のConf値の平均値 |
3.1.5. ログ出力
ログ出力に関する設定を変更します。
| No. | 内容 | 項目名 | 書式 | 説明 |
|---|
| 1 | ログ出力フォルダ | LOGS_PATH | 文字列 | 実行ログを出力するフォルダパス |
| 2 | ログ出力レベル | LOGS_LEVEL | 0~3 | 指定したレベルで以下の内容を出力する
・0 : DEBUG, INFO, WARNING, ERROR
・1 : INFO, WARNING, ERROR
・2 : WARNING, ERROR
・3 : ERROR |
| 3 | ログ1ファイルあたりの
データサイズ | LOG_ROTATION_SIZE | 0~100 | ログ1ファイルあたりの最大サイズ(MB)
0 の場合、プロセス単位でログを出力する |
| 4 | ログ全体のデータサイズ | LOG_MAX_SIZE | 0以上の整数 | ログファイルを保存する最大容量(MB)
0 の場合、制限なし(削除しない)
※LOG_ROTATION_SIZEより大きい値を設定すること |
3.1.6. ファイル
共通設定ファイルファイルの新規作成、保存の操作ができます。
| No. | 項目名 | 説明 |
| 1 | 新規 | 新規で共通設定ファイルを作成する |
| 2 | 開く | 共通設定ファイルを指定して開く |
| 3 | 上書き保存 | 編集中の設定を上書き保存する |
| 4 | 名前を付けて保存 | 編集中の設定を別ファイルとして保存する |
| 5 | 履歴 | 過去に保存した共通設定ファイルの履歴を表示する
選択することで対象ファイルを編集できる |
3.2. 共通設定ファイルでのみ指定できる項目
| No. | 項目名 | 書式 | 説明 |
| 1 | AUTO_CROPS | true, false | trueの場合、周囲の余白を削除する |
| 2 | OCR_MODEL_PATH | 文字列 | OCRエンジンで利用するモデルのフォルダパス(tessdataが存在するフォルダ) |
| 3 | OCR_MODE | 1 | OCRエンジンのOCRアルゴリズムを指定する |
3.3. 項目/文字切り取り画像の出力
手書き項目画像を出力する機能が有効(CREATE_HW_COMP_IMAGE=true)、もしくは手書き文字画像を出力する機能が有効(CREATE_HW_CHAR_IMAGE=true)の際は、手書き画像の出力先(HW_CUT_IMAGE_DIR)の指定されたディレクトリにそれぞれの手書き画像を出力します。
?指定した出力先(HW_CUT_IMAGE_DIR)
├ ─ ─ ?char(手書きのみ)
│ ├ ? FileA.jpg_0_0.jpg
│ ├ ? FileA.jpg_0_1.jpg
│ ├ ? FileA.jpg_0_2.jpg
│ ├ ⁝
│ └ ? FileA.jpg_3_7.jpg
│
└ ─ ─ ?component(活字・手書き)
├ ? FileA.jpg_0.jpg
├ ? FileA.jpg_1.jpg
├ ? FileA.jpg_2.jpg
└ ? FileA.jpg_3.jpg
項目(component)画像の数字は、同一入力ファイル中の連番です。
文字(char)画像の数字は、ファイル名で紐づく、項目画像ごとの連番です。
3.4. ユースケース
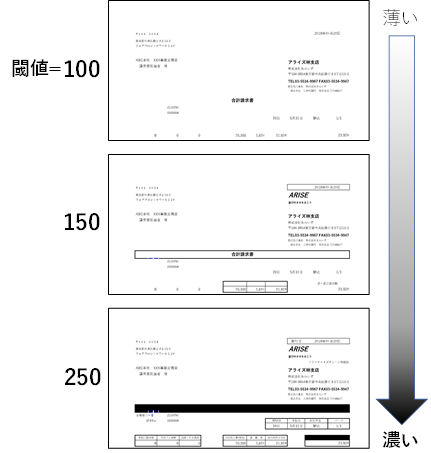
3.4.1. 二値化の閾値
OCRは画像を白と黒だけに変換(二値化)した状態で行います。各ピクセルの明るさ(黒0~255白)に対して、黒と白の境界とする値が二値化の閾値です。閾値は0~255を設定します。
二値化の閾値が低いと元の画像で濃い色のみが二値化で黒くなり、高いと薄い色でも黒くなります。
また、閾値を0とした場合は画像全体の明るさを基に自動で閾値を判定します。それによって目的の文字が消えてしまうなどあった場合は閾値を直接調整してください。
二値化の閾値の設定によって、下記画像のように変化します。

3.4.2. 細かいノイズ除去
細かいノイズ除去の閾値では、除去対象とするノイズの幅・高さを指定します。
どちらかのパラメータの対象となる場合は除去対象となります。
| ControlPanel項目名 | 共通設定ファイル項目名 | 推奨値 |
|---|
| 細かいノイズ除去の閾値(幅) | THIN_LINE_REMOVAL_THRESHOLD_W | 3 |
| 細かいノイズ除去の閾値(高さ) | THIN_LINE_REMOVAL_THRESHOLD_H | 3 |
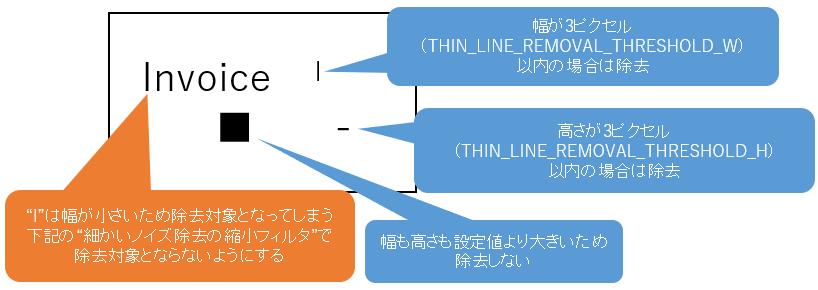
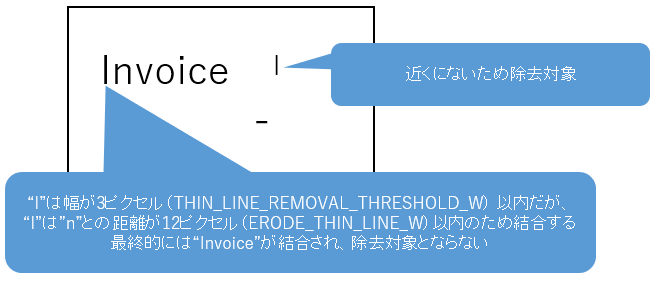
細かいノイズ除去の縮小フィルタは、近隣の文字・ノイズを結合して除去対象となるのを防ぎます。
結合する文字・ノイズ間の距離(ピクセル)を指定します。
| ControlPanel項目名 | 共通設定ファイル項目名 | 推奨値 |
|---|
| 細かいノイズ除去の縮小フィルタ(幅) | ERODE_THIN_LINE_W | 12 |
| 細かいノイズ除去の縮小フィルタ(高さ) | ERODE_THIN_LINE_H | 7 |
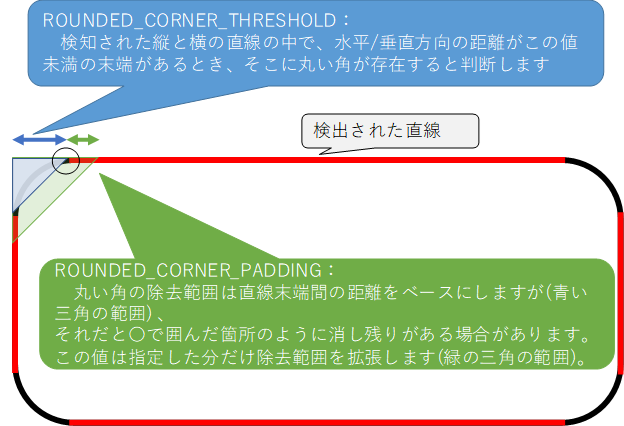
3.4.3. 丸い角の除去
帳票によっては丸い角の矩形が存在し、直線除去では角が残ってしまい誤読の原因となる場合があります。
そういった場合に、下記のパラメータを設定することで丸い角の除去を行います。
| ControlPanel項目名 | 共通設定ファイル項目名 | 推奨値 |
|---|
| 矩形の丸い角を除去する | ROUNDED_CORNER_THRESHOLD | 30 |
| 丸い角の除去範囲を拡張する長さ | ROUNDED_CORNER_PADDING | 10 |
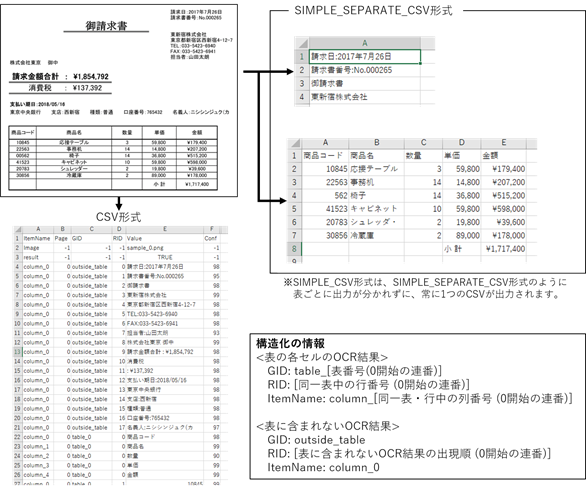
3.4.4. 表検出付全文OCR
コントロールパネルの抽出モードの設定で「キーワード指定(表検出付)」を指定した状態で全文OCRを実行すると、認識した罫線を基に表を検出し、表の各セルに対してOCRを行います。
この際、表の各セルのOCR結果は表の行・列の形に再現可能な情報が付与され構造化されます。ETL等で後続処理に表の情報を渡したい場合などにご利用ください。
なお、構造化情報の利用に応じて出力形式を選択可能です。
・付与された構造化情報含め出力したい場合: CSV形式
・構造化した表の形で出力したい場合: SIMPLE_CSV / SIMPLE_SEPARATE_CSV形式
※v2.3.1からタブ区切りのSIMPLE_TXT / SIMPLE_SEPARATE_TXT形式も追加されました
※表が段組みになっている場合には正しく構造化されません。
行と列が揃っている表にのみ有効です。
3.4.5. 色の抽出・除去
帳票上の印影や背景の色がOCRに影響し、正しく読み取りを行えない場合があります。
OCRを行う前に、必要な文字の色のみ抽出、もしくは余計な色の除去を行って調整します。
色の指定はHSV色空間で範囲指定します。
3.4.5.1. HSV色空間について
| 要素 | 指定範囲 | 説明 |
|---|
| H | 色相 | 0~179 | 具体的な色を定義する要素
色が環状で表現するため、0°と179°で同じ色となる |
| S | 彩度 | 0~255 | 色相で定義された色の鮮やかさ・濃さを表す要素
彩度が255で最も鮮やかとなり、減少に合わせて色が薄くなり、0で灰色になる |
| V | 明度 | 0~255 | 色相で定義された色の明るさ・暗さを表す要素
明度が255で最も明るく(白)、明度の減少に合わせて暗くなり、0で黒になる |
3.4.5.2. 色の指定方法(GUI)
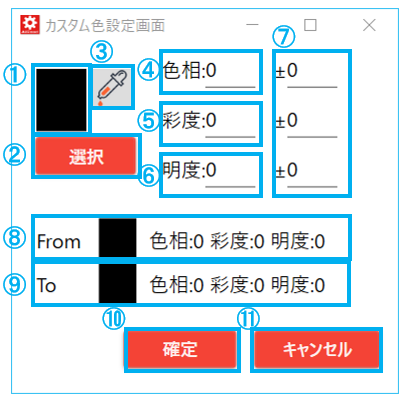
| No. | 項目名 | 説明 |
| 1 | 指定した色 | カラーパレット、もしくはスポイトで対象とした色が表示される |
| 2 | 色の選択ボタン | カラーパレットを開き、対象とする色を指定する |
| 3 | スポイトボタン | スポイト画面を開き、クリックした場所の色を抽出して対象とする |
| 4 | 色相 | 対象とした色の色相の表示、または色相を直接入力する |
| 5 | 彩度 | 対象とした色の彩度の表示、または彩度を直接入力する |
| 6 | 明度 | 対象とした色の明度の表示、または明度を直接入力する |
| 7 | ±(指定幅) | 対象とした色の色相、彩度、明度に対して、指定した数値分の幅を上下に持たせる
指定された数値分の幅は、from-to の範囲となる |
| 8 | 色の対象範囲(from) | 対象とした色から±で指定した数値分をマイナスして表示する |
| 9 | 色の対象範囲(to) | 対象とした色から±で指定した数値分をプラスして表示する |
| 10 | 確定ボタン | 指定した色の範囲をAIRead ContorlPanel に反映させる |
| 11 | キャンセルボタン | 編集内容を反映させずに、AIRead ContorlPanel へ戻る |
例)赤い色の範囲を指定する場合(GUI)

対象の色の値に対して幅を持たせることで、近い色も対象とすることができます。
3.4.5.3. 色の指定方法(テキスト)
テキストで設定を行う場合、対象としたい色の色相、彩度、明度の順で”:”(コロン)で区切り、色の指定を行います。
色相が0°、彩度、明度が200を指定する際は、下記の指定となります。
| 0 : 200 : 200 – 0 : 200 : 200 |
色相に前後の幅を持たせ、さらに明るい色も対象としたい場合は、下記のような指定を行います。
| -15 : 200 : 200 – 15 : 200 : 255 |
| 色相(-15 – 15) | 明度(200 – 255) |
| 0から±15の値 | 明度200より明るい色を取得するため、55プラスした値 |
※彩度を変更しない場合は、同じ値とします。
例)赤い色の範囲を指定する場合(テキスト)
純粋な赤色は、下記のように表現できます。
純粋な赤色の表現
実際は印刷等の条件により赤色の色合いは異なるため、範囲に幅を持たせることで色を対象とすることが可能です。
例)赤色を含むピンクからオレンジ色の範囲
※色相 -10 は 170 と同義
4. 帳票定義
読取位置、活字or手書き、項目名などを定義します。
4.1. 帳票定義フォルダの構成
帳票定義フォルダは以下の構成にする必要があります。
?AIRead_conf ---------(フォーマット定義フォルダ)
└?[フォーマットID]
├?AIRead_format.ini --------- 定義ファイル
├?AIRead_setting.ini --------- 個別設定ファイル
└(template.png) --------- テンプレート画像※
※テンプレート画像はチェックマークの読み取りをする場合に必要です
4.2. AIRead FormEditorで設定
以下のプログラムを起動することで、AIRead FormEditor(以下FormEditor)でフォーマット定義ファイルを編集できます。
<AIReadインストールフォルダ>/FormEditor/AIReadFormEditor.exe
4.2.1. グループの作成・選択
4.2.1.1. グループを作成する
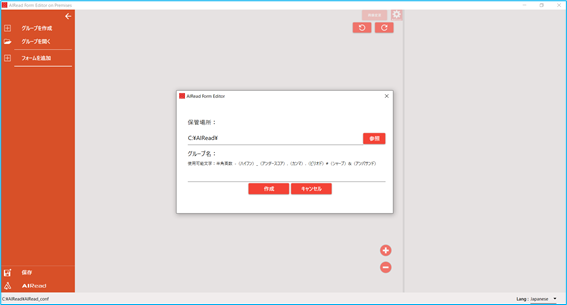
グループを作成 を選択するとダイアログが表示されます。
ダイアログ上でフォーマット定義を保存するフォルダ名を指定し、任意の名称でグループを作成します。
4.2.1.2. グループを選択する
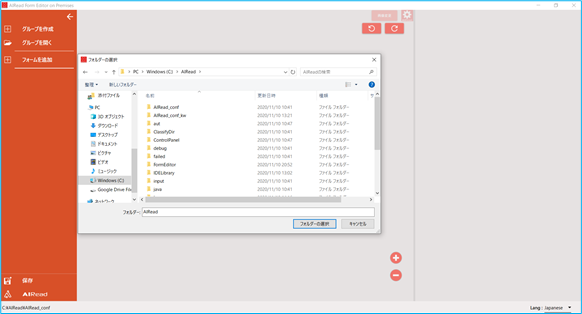
グループを開く を選択すると、フォルダ選択のダイアログが開かれます。
ダイアログから、作成済みのフォーマット定義を保存するフォルダを選択してください。
4.2.2. フォーマット定義の追加
4.2.2.1. フォーマット定義を追加する
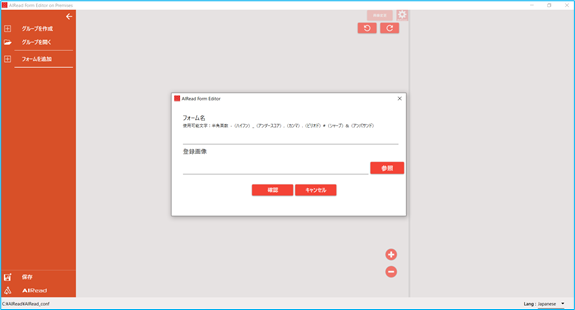
フォームを追加 を選択すると、ダイアログが表示されます。
ダイアログ上で、任意のフォーマット定義名(フォーム名)の指定と定義のテンプレート(下地)とする画像の登録を行います。
4.2.2.2. フォーマット定義を選択する
フォーマット定義名を選択すると、定義済みの設定を確認・編集できます。
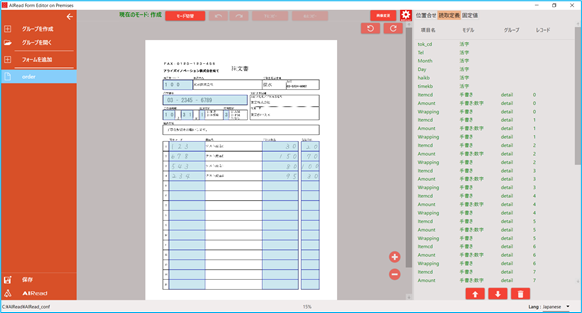
4.2.2.3. フォーマット定義をコピーする
任意のフォーマット定義名上でマウスを右クリックするとメニューが表示されます。
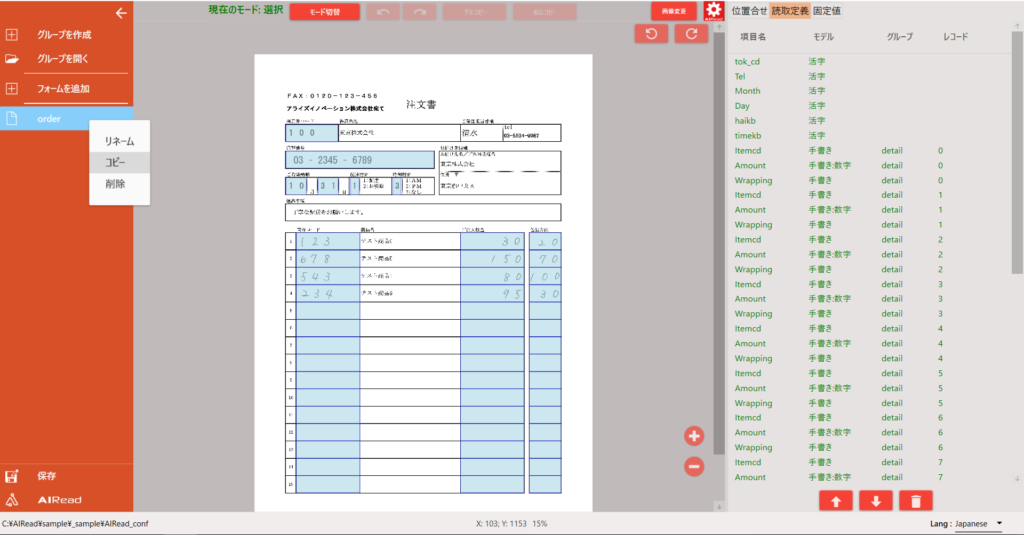
メニューから コピー を選択するとダイアログが表示されます。
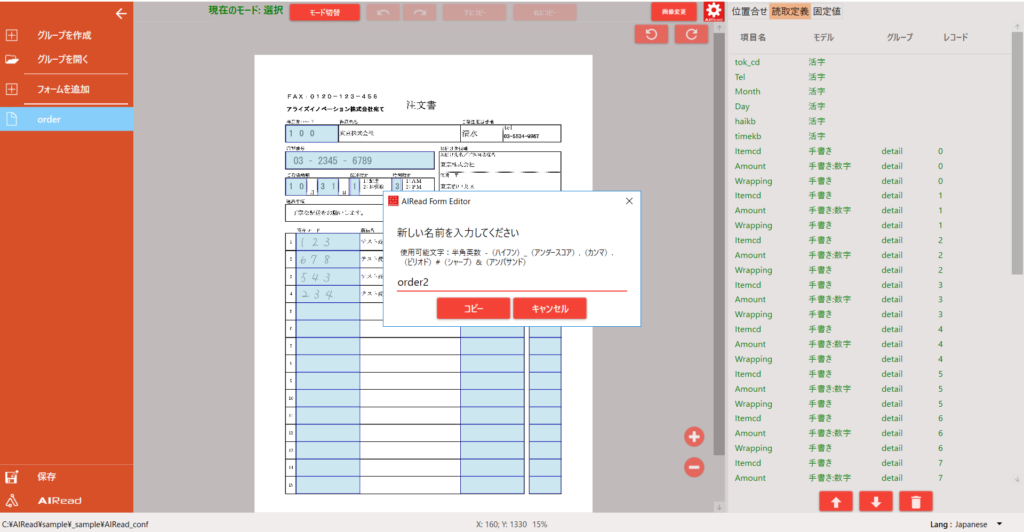
新たに任意のフォーマット定義名を入力し コピー を押下すると、フォーマット定義が複製されます。
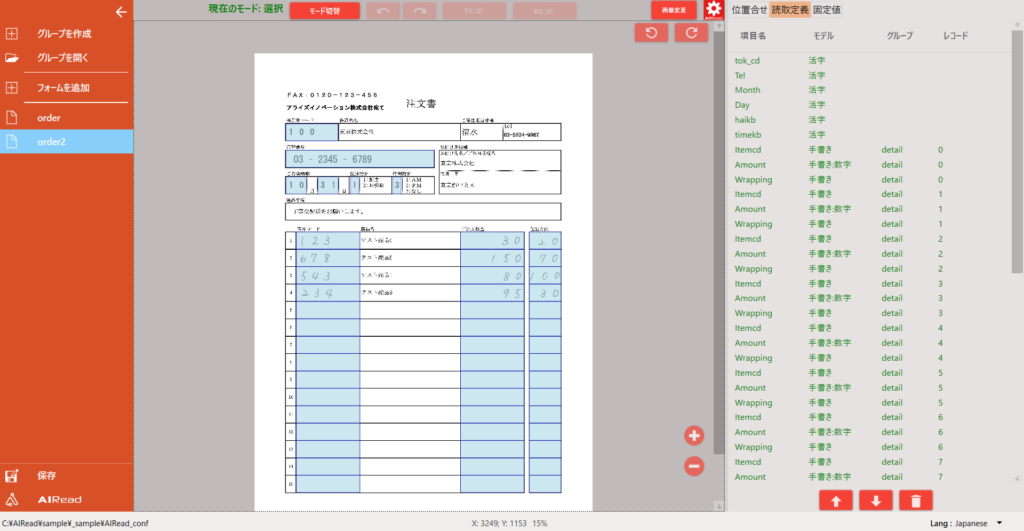
4.2.2.4. フォーマット定義を保存する
保存 を押下すると、編集済みのフォーマット定義が保存されます。
4.2.3. フォーマットの定義
4.2.3.1. 位置合せの定義
解像度等の違いにより、テンプレート画像をもとに設定したフォーマット定義と実際の画像でおきる位置ずれを補正します。
帳票内の最も大きい矩形を自動認識し、読み取り前に画像を拡大・縮小させます。
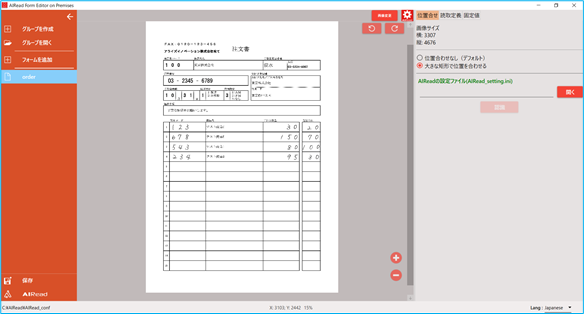
| No. | 項目名 | 説明 |
| 1 | 位置合せ定義 | 位置合せ定義画面を表示 |
| 2 | 位置合せ方法 | (1) 位置合わせなし
位置合わせを実施しない
(2) 大きな矩形で位置を合わせる
画像に含まれる大きな矩形を認識し位置合わせの基準として設定する
設定手順:
(ア) 開く からAIReadの共通設定ファイル(AIRead_setting.ini)を選択する
(イ) 認識 を押下する
(ウ) 位置合わせの基準となる矩形が検知される(数秒かかる) |
4.2.3.2. 読み取り範囲の設定
帳票上の読み取り範囲、読み取り方法、項目名を設定します。
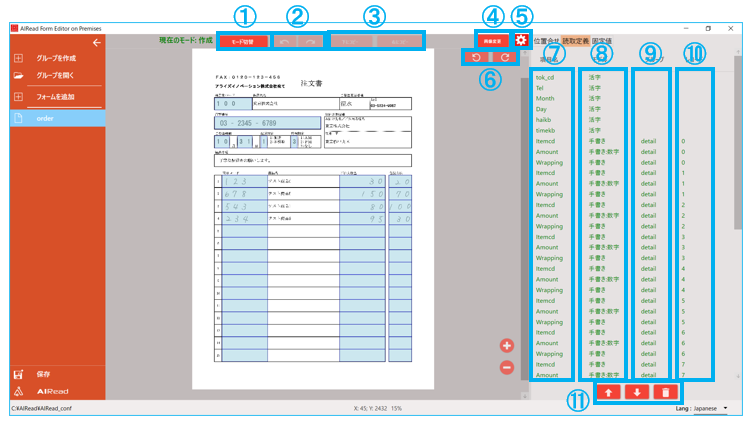
| No. | 項目名 | 説明 |
| 1 | モード切替 | 「選択モード」と「作成モード」を切り替える
・作成:読取範囲を新規で作成する
・選択:設定済みの項目を選択して修正する |
| 2 | 元に戻す・やり直し | 操作を1つ戻す(やり直す) |
| 3 | 下にコピー・右にコピー | 選択中の項目を下(右)にコピーする
項目名、グループ名、レコードIDの末尾が半角数字の場合は1加算される(オートフィル) |
| 4 | 画像変更 | テンプレート画像を変更する |
| 5 | 個別設定の呼出 | 開いているフォーマット定義専用の個別設定画面を起動する
4.2.5. 個別OCR設定を参照 |
| 6 | 左・右に90度回転 | 表示中の画像を左(右)に90度回転する |
| 7 | 項目名 | 読み取り結果ファイルに出力する項目名
設定された順番にCSVファイルに出力される |
| 8 | モデル | 「活字」、「手書き」、「チェックマーク」、「丸囲み」、「バーコード」、「画像抽出」のいずれかを表示
「手書き」の場合は指定した言語も表示される |
| 9 | グループ名 | 表など同一グループとして扱いたいときに指定するグループ名 |
| 10 | レコードID | 表などで同一行として扱いたいときに指定するレコードID |
| 11 | 移動・削除 | 選択中の項目を上下に移動・削除する |
4.2.3.3. 固定値の設定
固定値(必須出力)項目を設定します。

| No. | 項目名 | 説明 |
| 1 | 項目名 | 固定値の項目名 |
| 2 | 値 | 固定値の値 |
| 3 | グループ | 表など同一グループとして扱いたいときに指定するグループ名 |
| 4 | レコード | 表などで同一行として扱いたいときに指定するレコードID |
4.2.4. 読取定義の設定
「作成モード」で読み取り範囲を指定した場合、および読取項目をダブルクリックしたときに開きます。
4.2.4.1. 読み取り方法が OCR
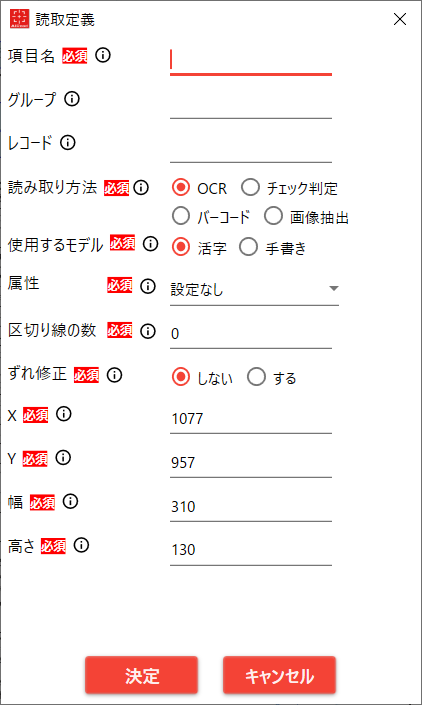
| No. | 項目名 | 説明 |
| 1 | 項目名 | 読み取り結果ファイルに出力する項目名
設定された順番にCSVファイルに出力される |
| 2 | グループ名 | 表など同一グループとして扱いたいときに指定するグループ名 |
| 3 | レコードID | 表などで同一行として扱いたいときに指定するレコードID |
| 4 | 読み取り方法 | 「OCR」を選択する |
| 5 | 使用するモデル | 「活字」または「手書き」を選択する
「活字」の場合は「属性」、「手書き」の場合は「言語」と「文字数」の指定が可能 |
| 6 | 属性 | 使用するモデルが「活字」のときに指定が可能
読み取り範囲の文字の属性を指定する
指定すると、特定の文字種のみが出力されるようにOCR結果を補正する
【属性一覧】
・設定なし:補正を行わない
・数字 :数字(0-9)のみが出力されるように補正する |
| 7 | 言語 | 使用するモデルが「手書き」のときに指定が可能
読み取り範囲で使用する手書き学習モデルを指定する
【言語一覧】
・日本語 :数字、ローマ字、記号、カタカナ、ひらがな、常用漢字を学習したモデル
・名前 :カタカナ、ひらがな、人名漢字、常用漢字の一部を学習したモデル
・住所 :数字、ローマ字、カタカナ、ひらがな、住所漢字を学習したモデル
・カタカナ:カタカナを学習したモデル
・英語 :数字、ローマ字、記号を学習したモデル
・数字 :数字を学習したモデル
・通貨 :数字、記号($、¥、マイナス、カンマ、ピリオド)を学習したモデル
・数値・電話番号:数字、記号(マイナス、カンマ、括弧、括弧閉じ)を学習したモデル
設定なしの場合は共通設定の「手書き用OCRモデル」で設定したモデルを使用する |
| 8 | 文字数 | 使用するモデルが「手書き」のときに指定が可能
読み取り範囲の文字数が「複数」か「1文字」かを指定する
言語項目で「数値・電話番号」を選択した場合は、複数文字に固定される |
| 9 | 区切り線の数 | 読み取り範囲内にある桁や文字の区切り線(点線)を除去するための本数を指定する
指定された数分の罫線除去を行う(区切り線が等間隔に並んでいる前提)
※「手書き」の場合、「文字数」が「複数」の場合のみ設定可能 |
| 10-1 | ずれ修正 | ずれ修正を「する」、「しない」を指定する |
| 10-2 | 基準 | ずれ修正の基準を「セル」か「文字列」から選択する
・セル :読み取り範囲に最も近いセル(矩形)に読み取り位置を修正する
・文字列:読み取り範囲と重なる文字列を対象に読み取り位置を修正する |
| 11 | 対象
(基準が「セル」の時) | ずれ修正の対象となるセルに合わせる修正方向を「左」、「右」、「上」、「下」で指定する
複数選択した場合は、複数方向に位置修正を行う
※仕様の詳細は、4.3.3.1ずれ修正(セルに合わせる場合)についてに記載 |
| 12 | 方法
(基準が「文字列」の時) | ずれ修正の対象となる文字列に対して行う修正の方法を「移動」か「拡張」で指定する
※仕様の詳細は、4.3.3.2ずれ修正(文字列に合わせる場合)についてに記載 |
| 13 | X | 読み取り範囲の左上のX座標(ピクセル) |
| 14 | Y | 読み取り範囲の左上のY座標(ピクセル) |
| 15 | 幅 | 読み取り範囲の幅(ピクセル) |
| 16 | 高さ | 読み取り範囲の高さ(ピクセル) |
4.2.4.2. 読み取り方法が チェック判定
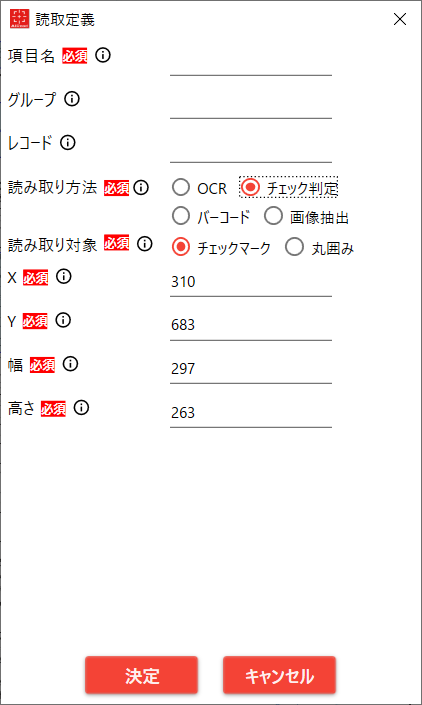
| No. | 項目名 | 説明 |
| 1 | 項目名 | 読み取り結果ファイルに出力する項目名
設定された順番にCSVファイルに出力される |
| 2 | グループ名 | 表など同一グループとして扱いたいときに指定するグループ名 |
| 3 | レコードID | 表などで同一行として扱いたいときに指定するレコードID |
| 4 | 読み取り方法 | 「チェック判定」を選択する |
| 5 | 読み取り対象 | 「チェックマーク」または「丸囲み」を選択する
【読み取り対象一覧】
・チェックマーク:レ点の有無を判定する
・丸囲み:丸囲みや塗りつぶしを判定する
テンプレートの画像と読取画像を比較し、読み取り範囲の黒色が「6. 閾値」で指定した割合以上のときにチェックがされたと判定する |
| 6 | 閾値 | テンプレート画像に対する黒領域の割合(パーセント)
※「5. 読み取り対象」が丸囲みの時のみ設定 |
| 7 | X | 読み取り範囲の左上のX座標(ピクセル) |
| 8 | Y | 読み取り範囲の左上のY座標(ピクセル) |
| 9 | 幅 | 読み取り範囲の幅(ピクセル) |
| 10 | 高さ | 読み取り範囲の高さ(ピクセル) |
4.2.4.3. 「読み取り方法」が バーコード
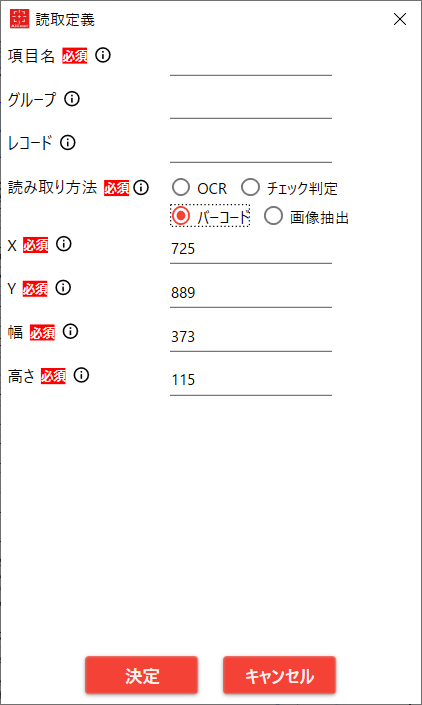
| No. | 項目 | 説明 |
|---|
| 1 | 項目名 | 読み取り結果ファイルに出力する項目名
設定された順番にCSVファイルに出力される |
| 2 | グループ名 | 表など同一グループとして扱いたいときに指定するグループ名 |
| 3 | レコードID | 表などで同一行として扱いたいときに指定するレコードID |
| 4 | 読み取り方法 | 「バーコード」を選択する
※対応しているバーコードは(NW-7) |
| 5 | X | 読み取り範囲の左上のX座標(ピクセル) |
| 6 | Y | 読み取り範囲の左上のY座標(ピクセル) |
| 7 | 幅 | 読み取り範囲の幅(ピクセル) |
| 8 | 高さ | 読み取り範囲の高さ(ピクセル) |
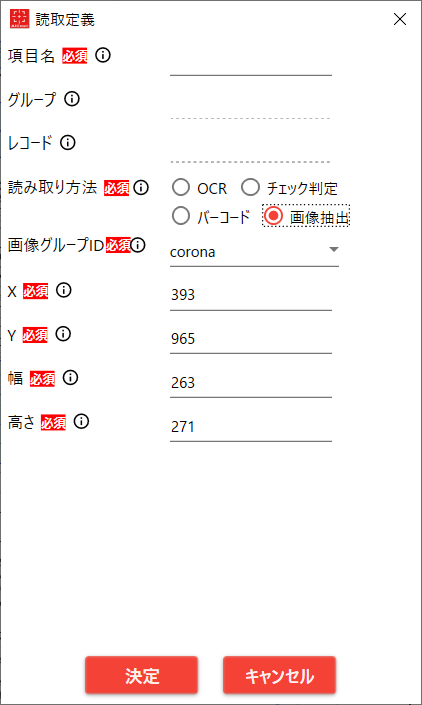
4.2.4.3. 「読み取り方法」が 画像抽出
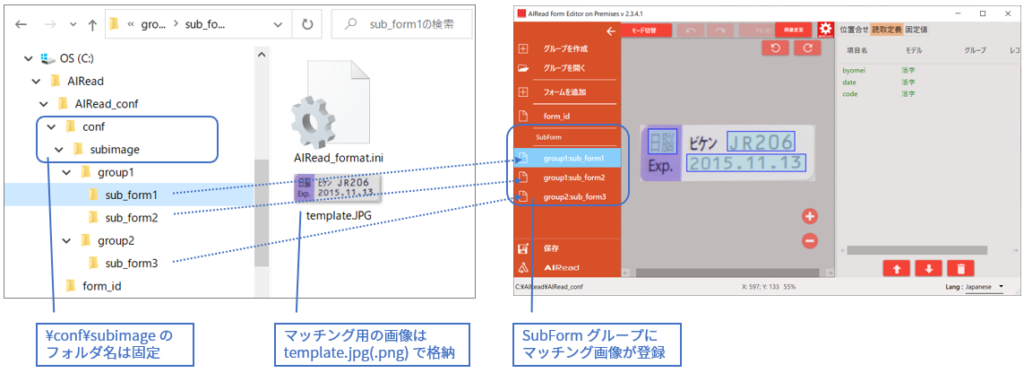
抽出したい画像の設定は、あらかじめ以下のようなフォルダ構成を作成する。
?AIRead_conf(フォーマット定義のグループフォルダ)
├ ─ ─ ?form_id(フォーマット定義名)
│ ├ ? AIRead_format.ini
│ ├ ? AIRead_setting.ini
│ └? template.png
│
└ ─ ─ ?conf(固定フォルダ)
└? subimage(固定フォルダ)
├─?group1(画像グループID)
│ ├─?sub_form1(画像ID)
│ │ ├ ? AIRead_format.ini
│ │ └? template.png
│ │
│ └─?sub_form2(画像ID)
│ │ ├ ? AIRead_format.ini
│ │ └? template.png
│ ⁝
│
├─?group2(画像グループID)
⁝ ├─?sub_form3(画像ID)
│ ├ ? AIRead_format.ini
│ └? template.png
⁝
それぞれの sub_formn フォルダに画像マッチングさせたい画像ファイルを「template.png」というファイル名で保存する。
FormEditor では以下のように登録される。抽出画像ごとに読み取り範囲を設定する。
| No. | 項目 | 説明 |
|---|
| 1 | 項目名 | 読み取り結果ファイルに出力する項目名 |
| 2 | グループ名 | 設定不可 |
| 3 | レコードID | 設定不可 |
| 4 | 読み取り方法 | 「画像抽出」を選択する |
| 5 | 画像グループID | 抽出させたい画像のグループIDを選択する
前述のフォルダ構成の group1/group2 に相当する |
| 6 | X | 読み取り範囲の左上のX座標(ピクセル) |
| 7 | Y | 読み取り範囲の左上のY座標(ピクセル) |
| 8 | 幅 | 読み取り範囲の幅(ピクセル) |
| 9 | 高さ | 読み取り範囲の高さ(ピクセル) |
4.2.5. 個別OCR設定
フォーマット定義ごとに個別でOCR設定の定義を行います。
個別OCR設定の呼出 ボタンを押下することで、個別OCR設定用のAIRead ControlPanel 画面を呼び出します。
呼び出す際に、共通のOCR設定を引継ぐか指定します。
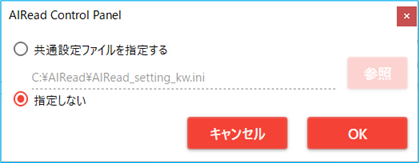
「個別設定に使う」にチェックのついたパラメータは、AIRead実行時に共通設定ファイルのパラメータを上書きして実行されます。
ただし、「入力フォルダ」や「抽出モードの指定」等一部のパラメータは置き換えできません。
設定内容については、3. 共通設定を参照して下さい。
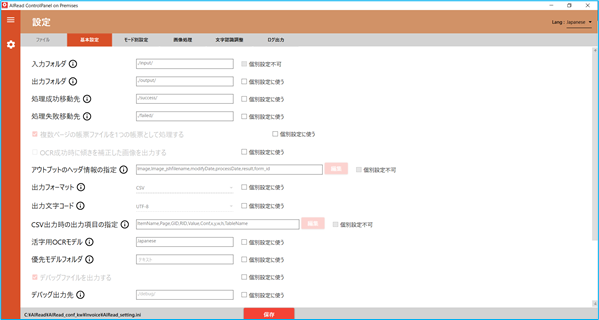
4.2.5.1. 設定方法
新規で個別設定を行う場合、すべての個別設定は無効となっており設定値が編集できません。
個別設定に使用したい設定項目の右側にある、個別設定に使うチェックボックス(□)をクリックし、設定値を編集してください。
AIRead on Cloudで有効な設定は☁マーク(□)がついた項目のみとなります。

設定の編集が完了したら、保存してください。個別設定が反映されます。
保存が完了したら、右上の×ボタンで画面を閉じてください。
4.2.6. AIReadの実行
作成したフォーマット定義でAIReadを実行します。
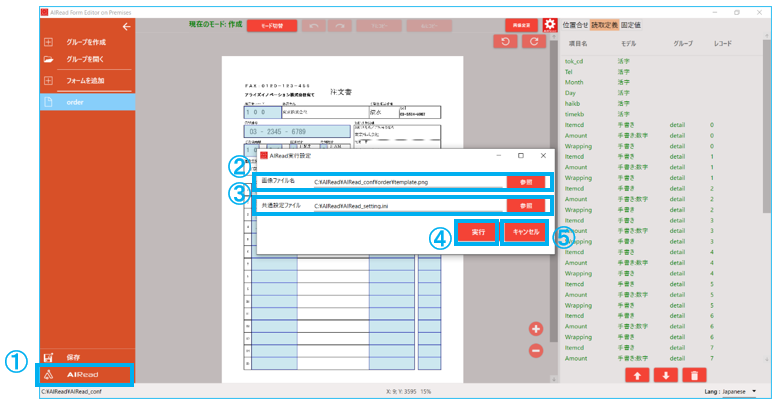
| No. | 項目名 | 説明 |
| 1 | AIRead実行 | AIRead実行設定ダイアログを開く
※AIRead OCRエンジンがインストールされていない環境では、AIRead実行ボタンは非表示となる |
| 2 | 画像ファイル名 | AIReadを実行する画像ファイルを指定する |
| 3 | 共通設定ファイル | 使用する共通設定ファイルを指定する |
| 4 | 実行 | AIReadの実行を開始する |
| 5 | キャンセル | ダイアログを閉じる |
4.2.7. AIReadの実行結果を確認
実行後にAIReadの実行結果確認画面を表示します。
表示された実行結果一覧画面より、確認・編集を行うファイルを選択し、実行結果確認画面を表示します。
4.2.7.1. 実行結果一覧画面
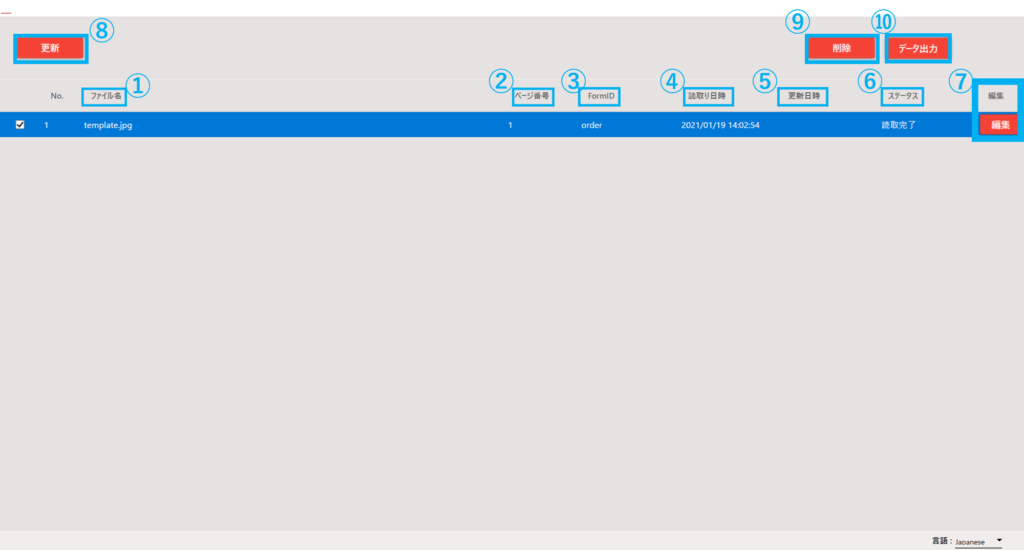
| No. | 項目名 | 説明 |
| 1 | ファイル名 | 読み取ったファイル名を表示する |
| 2 | ページ番号 | 読み取ったファイルのページ数を表示する |
| 3 | FormID | 読み取りに使用したフォーマット定義名を表示する |
| 4 | 読取り日時 | 読み取りを実行した日時を表示する |
| 5 | 更新日時 | 最終更新日時を表示する |
| 6 | ステータス | 実行結果の状態を表示する
・読取完了 :読み取りが終了
・確定済 :実行結果確認画面で確定処理を実施済み
・CSV出力済 :データ出力ボタンでCSV出力を実施済み
・読取失敗 :読み取りが失敗
※AIRead自体が起動できない、異常終了の場合は一覧に表示されない |
| 7 | 編集ボタン | 対象の実行結果の実行結果確認画面を表示する(該当行をダブルクリックでも表示可能) |
| 8 | 更新ボタン | 実行結果一覧を最新の状態へ更新する |
| 9 | 削除ボタン | チェックボックスで選択した実行結果を削除する |
| 10 | データ出力ボタン | チェックボックスで選択した実行結果をCSV出力する |
4.2.7.2. 実行結果一覧画面
「複数ページの帳票ファイルを1つの帳票として処理する」が 有効
(FILE_IDENTICATION_TYPE=1)の場合、1つの確認画面で全てのページを確認することができます。
「複数ページの帳票ファイルを1つの帳票として処理する」が 無効
(FILE_IDENTICATION_TYPE=0)の場合、それぞれのページごとの結果確認画面が作成されます。
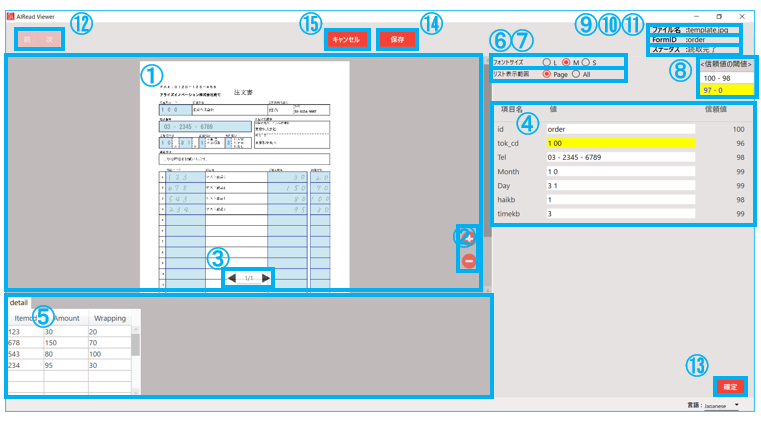
| No. | 項目名 | 説明 |
| 1 | 帳票画像 | OCRを行った画像を表示
各読み取り領域をマウスでポイントすると、「OCR結果一覧」の該当項目を強調する |
| 2 | 拡大縮小ボタン | 帳票画像の拡大縮小操作に使用 |
| 3 | ページ変更ボタン | 表示する確認画面変更に使用
複数ページの帳票ファイルを1つの帳票として処理した時のみ使用 |
| 4 | OCR結果一覧(リスト) | 項目名と読み取った値(編集可能)のリスト一覧表示
項目をマウスでクリックすると、「帳票画像」の該当位置を強調 |
| 5 | OCR結果一覧(明細) | 項目名と読み取った値(編集可能)の明細一覧表示
項目をマウスでクリックすると、「帳票画像」の該当位置を強調 |
| 6 | フォントサイズ変更ボタン | ラジオボタンの選択でOCR結果一覧のフォントサイズを変更する |
| 7 | リスト表示変更ボタン | ラジオボタンの選択で結果表示一覧を変更する
Page:現在画像表示しているページの結果のみ表示する
All :複数の出力結果をすべて表示する |
| 8 | 信頼値の閾値 | OCR結果一覧の背景色の設定の表示
背景色が白:OCR結果の信頼度が100~98%
背景色が黄:OCR結果の信頼度が97%以下 |
| 9 | ファイル名 | 読み取ったファイル名を表示する(マウスオーバーでファイル名をすべて表示) |
| 10 | FormID | 読み取りに使用したフォーマット定義名を表示する |
| 11 | ステータス | 読み取り結果の状態を表示する |
| 12 | 前・次ボタン | 実行結果一覧画面の前後の実行結果へ移動する |
| 13 | 確定・確定解除ボタン | ステータスを”確定済み”へ変更する
また、”確定済み”、”CSV出力済み”のステータスを”確定済み”へ変更する |
| 14 | 保存ボタン | 編集後の各項目の値を保存
※編集後の値はViewer内部に保持されるため、このボタンから保存先の指定は行わない |
| 15 | キャンセルボタン | 編集内容を保存せず、実行結果一覧画面へ戻る |
4.2.8. 実行結果の保存
データ出力ボタンを押下すると、保存用のダイアログが表示されます。
このダイアログ上で、任意の場所に保存することができます。
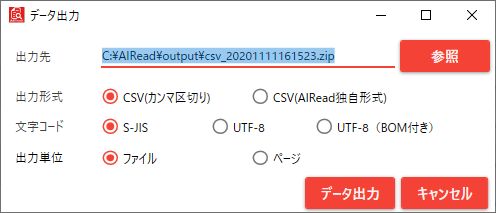
| No. | 項目名 | 説明 |
| 1 | 出力先 | 実行結果の保存先を指定する |
| 2 | 出力形式 | 実行結果の保存形式をCSV(カンマ区切り) か CSV(独自形式) かを設定する
※CSVカンマ区切りの場合、ヘッダ部と明細部のCSVファイルが出力されるため、zip圧縮で出力される |
| 3 | 文字コード | 出力する実行結果の文字コードを、S-JIS、UTF-8、UTF-8(BOM付き)から選択する |
| 4 | 出力単位 | 「複数ページの帳票ファイルを1つの帳票として処理する」が設定された帳票が含まれる場合のみ表示される
ファイル:ファイル単位で結果をまとめる(複数ページ1出力)
ページ :ページ単位で結果をまとめる(1ページ1出力) |
| 5 | データ出力ボタン | 指定された設定で実行結果を保存する |
| 6 | キャンセルボタン | 保存用ダイアログを閉じる |
4.2.9. 出力形式
FormEditorからの実行結果を出力する形式は2種類あります。
4.2.9.1. CSV(カンマ区切り)
1行目にヘッダ情報、2行目以降にデータ情報が出力される、一般的なCSV形式です。ヘッダ、明細それぞれでCSVファイルが出力されます。
CSVファイル名は、下記のルールに従って作成されます。
・グループ名の設定がない項目(ヘッダ項目)
[入力ファイル名].csv
・グループ名の設定がある項目(明細項目)
[入力ファイル名]_[グループ名].csv
※ファイル名に使用できない文字(\/:*?”<>|)がグループ名に含まれる場合、その文字は除外されます
明細データは、FormEditorの読み取り定義で指定した設定が、下記のルールに従ってまとめられます。
ファイル:グループ
行 :レコード
列 :項目名
ヘッダ項目の出力 ( [入力ファイル名].csv)
“Image”,”Image_jshfilename”,”modifyDate”,”processDate”,”result”,”form_id”,”tok_cd”
“sample.jpg”,”C: \Result\20200325_174313_487\sample.jpg”,”2020-02-06T16:28:52″,”2020-03-25T17:43:34″,”true”,”order”,”100” |
※固定で”Image”,”Image_jshfilename”,”modifyDate”,”processDate”,”result”,”form_id”が出力されます。これらの項目には5.1 共通を参照ください。
明細項目の出力 ([入力ファイル名]_[グループ名].csv
“Itemcd”,”Amount”,”Wrapping”
“123”,”100″,”30″
“456”,”50″,”10″ |
4.2.9.2. CSV(独自形式)
5.2. CSVを参照ください。
4.3. フォーマット定義ファイル
帳票の位置を合わせるための情報、出力ファイルに記載する情報、OCRで読み取る位置の情報はフォーマット定義ファイルで設定します。
ファイルはタブ区切りで記載します。
1列目のセクションIDの値によって、2列目以降の記載方法が異なります。
| 項目名 | 書式 | 説明 |
|---|
| セクションID | 0 | 位置合わせ情報 |
| 1 | 出力情報(固定値) |
| 2 | OCR情報 |
| 3 | チェックマーク情報(画像差分で判定) |
| 4 | チェックマーク情報(✔の形で判定) |
※位置合わせ情報は省略可です。省略した場合、絶対座標で抽出します。
- ファイル名:AIRead_format.ini
- フォーマット定義ファイルイメージ:
ずれ修正なしの場合
0 3307 4676 300 1745 2645 1745 300 4295
1 0 id order
2 0 307 688 510 170 0 0 tok_cd
2 0 307 951 1450 170 0 0 Tel
2 0 307 1207 200 170 0 0 Month
2 0 620 1207 200 170 0 0 Day
2 0 938 1207 85 170 0 0 haikb
2 0 1350 1207 85 170 0 0 timekb
2 0 detail 0 407 1745 627 170 1 0 Itemcd0
2 0 detail 0 2015 1745 623 170 1:number 0 Amount0
2 0 detail 0 2687 1745 314 170 1 0 Wrapping0
2 0 detail 1 407 1915 627 170 1 0 Itemcd1
2 0 detail 1 2015 1915 623 170 1:number 0 Amount1
2 0 detail 1 2687 1915 314 170 1 0 Wrapping1
2 0 detail 2 407 2085 627 170 1 0 Itemcd2
2 0 detail 2 2015 2085 623 170 1:number 0 Amount2
2 0 detail 2 2687 2085 314 170 1 0 Wrapping2
2 0 detail 3 407 2255 627 170 1 0 Itemcd3
2 0 detail 3 2015 2255 623 170 1:number 0 Amount3
2 0 detail 3 2687 2255 314 170 1 0 Wrapping3
2 0 detail 4 407 2425 627 170 1 0 Itemcd4
2 0 detail 4 2015 2425 623 170 1:number 0 Amount4
2 0 detail 4 2687 2425 314 170 1 0 Wrapping4
2 0 detail 5 407 2595 627 170 1 0 Itemcd5
2 0 detail 5 2015 2595 623 170 1:number 0 Amount5
2 0 detail 5 2687 2595 314 170 1 0 Wrapping5 |
ずれ修正ありの場合
1 -1 id order
2 -1 307 688 510 170 0 0 tok_cd 0 1 1 1 1 0
2 -1 307 951 1450 170 0 0 Tel 0 1 1 1 1 1
2 -1 307 1207 200 170 0 0 Month
2 -1 620 1207 200 170 0 0 Day
2 -1 938 1207 85 170 0 0 haikb
2 -1 1350 1207 85 170 0 0 timekb
2 -1 detail 0 407 1745 627 170 1 1 Itemcd 1 1 1 1 1 0
2 -1 detail 0 2015 1745 623 170 1:number 0 Amount 1 1 1 1 1 0
2 -1 detail 0 2687 1745 314 170 1 1 Wrapping 1 1 1 1 1 0
2 -1 detail 1 407 1915 627 170 1 0 Itemcd 1 1 1 1 1 0
2 -1 detail 1 2015 1915 623 170 1:number 0 Amount 1 1 1 1 1 0
2 -1 detail 1 2687 1915 314 170 1 0 Wrapping 1 1 1 1 1 0
2 -1 detail 2 407 2085 627 170 1 0 Itemcd 1 1 1 1 1 0
2 -1 detail 2 2015 2085 623 170 1:number 0 Amount 1 1 1 1 1 0
2 -1 detail 2 2687 2085 314 170 1 0 Wrapping 1 1 1 1 1 0
2 -1 detail 3 407 2255 627 170 1 0 Itemcd 1 1 1 1 1 0
2 -1 detail 3 2015 2255 623 170 1:number 0 Amount 1 1 1 1 1 0
2 -1 detail 3 2687 2255 314 170 1 0 Wrapping 1 1 1 1 1 0
2 -1 detail 4 407 2425 627 170 1 0 Itemcd 1 1 1 1 1 0
2 -1 detail 4 2015 2425 623 170 1:number 0 Amount 1 1 1 1 1 0
2 -1 detail 4 2687 2425 314 170 1 0 Wrapping 1 1 1 1 1 0
2 -1 detail 5 407 2595 627 170 1 0 Itemcd 1 1 1 1 1 0
2 -1 detail 5 2015 2595 623 170 1:number 0 Amount 1 1 1 1 1 0
2 -1 detail 5 2687 2595 314 170 1 0 Wrapping 1 1 1 1 1 0 |
4.3.1. 位置合わせ情報
帳票の中で一番大きな矩形を基準に位置を合わせます。
ベースとなる3点(左上・右上・左下)の位置を定義します。
| No. | 項目名 | 書式 | 必須 | 説明 |
|---|
| 1 | セクションID | 0 | 必須 | |
| 2 | width | 整数 | 必須 | ベースとなる画像サイズの幅 |
| 3 | height | 整数 | 必須 | ベースとなる画像サイズの高さ |
| 4 | x1 | 整数 | 必須 | ベースとなる矩形の左上の点のx座標 |
| 5 | y1 | 整数 | 必須 | ベースとなる矩形の左上の点のy座標 |
| 6 | x2 | 整数 | 必須 | ベースとなる矩形の右上の点のx座標 |
| 7 | y2 | 整数 | 必須 | ベースとなる矩形の右上の点のy座標 |
| 8 | x3 | 整数 | 必須 | ベースとなる矩形の左下の点のx座標 |
| 9 | y3 | 整数 | 必須 | ベースとなる矩形の左下の点のy座標 |
※位置合わせ情報は省略可です。省略した場合、位置合わせは行われず絶対座標で抽出します。
■位置合わせイメージ
画像内の最大の矩形を検知し、左上・右上・左下の3点を基点に位置を合わせます。

4.3.2. 出力情報(固定値)
| No. | 項目名 | 書式 | 必須 | 説明 |
|---|
| 1 | セクションID | 1 | 必須 | |
| 2 | シーケンス番号 | 整数 | | (使用しない) |
| 3 | 項目名 | 文字列 | 必須 | 出力情報に記載する項目名 |
| 4 | 値 | 文字列 | 必須 | 出力する文字列 |
| 5 | グループID | 文字列 | | グループID(明細・表の名前)を指定
アウトプット時に使用 |
| 6 | レコードID | 整数 | | レコードID(明細の行番号)を指定
アウトプット時に使用 |
4.3.3. 出力情報(OCR)
| No. | 項目名 | 書式 | 必須 | 説明 |
| 1 | セクションID | 2 | 必須 | |
| 2 | シーケンス番号 | 整数 | | (使用しない) |
| 3 | グループID | 文字列 | | グループID(明細・表の名前)を指定
アウトプット時に使用 |
| 4 | レコードID | 整数 | | レコードID(明細の行番号)を指定
アウトプット時に使用 |
| 5 | x | 整数 | 必須 | 読取範囲の基準となる座標(左上の点)のx座標 |
| 6 | y | 整数 | 必須 | 読取範囲の基点となる座標(左上の点)のy座標 |
| 7 | width | 整数 | 必須 | 読取範囲の幅 |
| 8 | height | 整数 | 必須 | 読取範囲の高さ |
| 9 | type | 0, 1 | 必須 | 0 : 活字
1 : 手書き
手書きはコロン(:)区切りで項目ごとにOCRモデルを指定する
指定がない場合、ControlPanelの手書き用OCRモデルを使用する
指定例)1:number |
| 10 | length | 0以上の整数 | 必須 | typeが 0(活字)の場合
0 : 特別な処理を行わない
2以上 : 指定された数 -1本の区切り罫線を除去する
typeが 1(手書き)の場合
0 : 特別な処理を行わない
1 : 指定した範囲の文字を1文字として認識する
2以上 : 指定された数 -1本の区切り罫線を除去する |
| 11 | フィールドID | 文字列 | 必須 | 項目名 |
| 12 | ずれ修正 | 0, 1 | | 0:文字列でのずれ修正
1:セルでのずれ修正 |
| 13 | 修正対象(左) | 0, 1 | | ずれ修正が1(セル)の場合のみ有効
0:セルの左辺を基準としたずれ修正をしない
1:セルの左辺を基準としたずれ修正を行う |
| 14 | 修正対象(右) | 0, 1 | | ずれ修正が1(セル)の場合のみ有効
0:セルの上辺を基準としたずれ修正をしない
1:セルの上辺を基準としたずれ修正を行う |
| 15 | 修正対象(上) | 0, 1 | | ずれ修正が1(セル)の場合のみ有効
0:セルの上辺を基準としたずれ修正をしない
1:セルの上辺を基準としたずれ修正を行う |
| 16 | 修正対象(下) | 0, 1 | | ずれ修正が1(セル)の場合のみ有効
0:セルの底辺を基準としたずれ修正をしない
1:セルの底辺を基準としたずれ修正を行う |
| 17 | 修正方法 | 0, 1 | | ずれ修正が0(文字列)の場合のみ有効
0:文字列を基準として読取位置を移動する
1:文字列を基準として読取位置の拡張をする |
| 18 | 属性 | 文字列 | | 後処理を行う属性を指定する |
※修正対象(右)、修正対象(左)、修正対象(上)、修正対象(下) は併用可能
4.3.3.1. ずれ修正(セルに合わせる場合)について
セルに合わせるずれ修正を行う場合、下記のルールで行われます。
<合わせる対象>
読み取り範囲に対し、以下の 2つの条件を満たすセルが合わせる対象となります。
1. 読取範囲に対し、セルの面積が30%以上重なっていること
2. 条件1.を満たすセルのうち、読み取り範囲に対して重なっている面積が最大であること
<例外>
修正後のセルの高さが元の読み取り範囲の高さの1.2倍を超える場合、ずれ修正は行われません。
※本機能は軽微な位置ずれを補正するための機能であり、過度なずれ修正は行わなれません
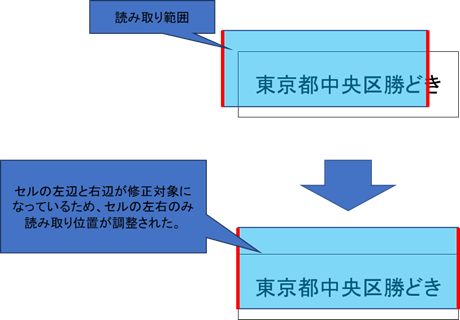
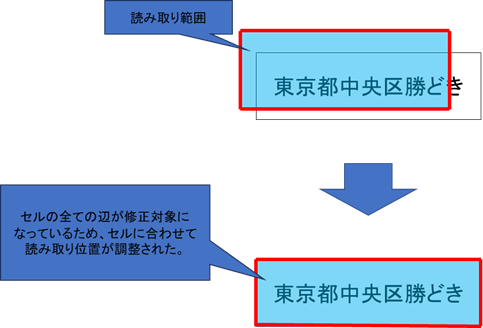
<修正対象(左右上下)について>
修正の対象の選択によって、修正結果が下記の例のように変わります。
ずれ修正の修正対象(左、右)が有効の場合
ずれ修正の修正対象(左右上下)が有効の場合
4.3.3.2. ずれ修正(文字列に合わせる場合)について
文字列に合わせるずれ修正を行う場合、下記のルールで行われます。
<合わせる対象>
読み取り範囲に対し、面積が30%以上重なっている文字列が合わせる対象となります。
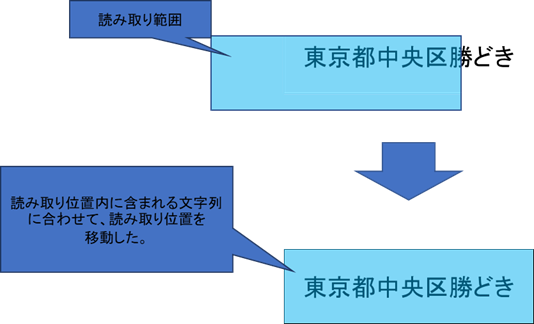
<修正方法:移動について>
修正方法に「移動」を指定した場合、読み取り範囲(矩形の形)は変更せず合わせる対象の文字列が入るように読み取り位置を移動させます。
※重なっている文字列の範囲より読み取り範囲が小さい場合は修正しません。
ずれ修正の方法が文字列を基準とした移動の場合
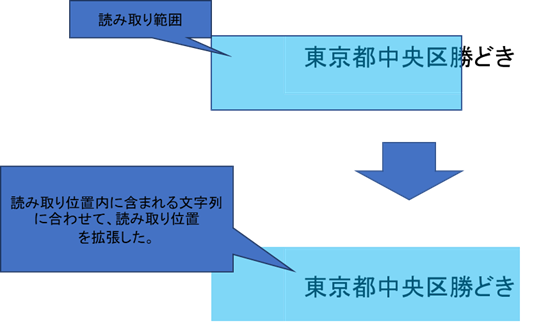
<修正方法:拡張について>
修正方法に「拡張」を選択した場合、読み取り範囲に重なる全文字列が包含できるように読み取り範囲を拡張します。
ずれ修正の方法が文字列を基準とした拡張の場合
4.3.4. 出力情報(チェックマーク)
| No. | 項目名 | 書式 | 必須 | 説明 |
| 1 | セクションID | 3 または 4 | 必須 | 3 : テンプレート画像との差分で判定
4 : レ点で判定 |
| 2 | シーケンス番号 | | | (使用しない) |
| 3 | グループID | 文字列 | | グループID(明細・表の名前)を指定
アウトプット時に使用 |
| 4 | レコードID | 整数 | | レコードID(明細の行番号)を指定
アウトプット時に使用 |
| 5 | x | 整数 | 必須 | 読取範囲の基準となる座標(左上の点)のx座標 |
| 6 | y | 整数 | 必須 | 読取範囲の基点となる座標(左上の点)のy座標 |
| 7 | width | 整数 | 必須 | 読取範囲の幅 |
| 8 | height | 整数 | 必須 | 読取範囲の高さ |
| 9 | type | 0 | 必須 | |
| 10 | length | 0~1000 | 必須 | (セクションID=3のときのみ)
テンプレート領域に対する黒領域の割合(%) |
| 11 | フィールドID | 文字列 | 必須 | 項目名 |
4.3.5. 出力情報(バーコード)
| No. | 項目名 | 書式 | 必須 | 説明 |
|---|
| 1 | セクションID | 6 | 必須 | |
| 2 | シーケンス番号 | | | (使用しない) |
| 3 | グループID | 文字列 | | グループID(明細・表の名前)を指定 |
| 4 | レコードID | 整数 | | レコードID(明細の行番号)を指定 |
| 5 | x | 整数 | 必須 | 読取範囲の基準となる座標(左上の点)のx座標 |
| 6 | y | 整数 | 必須 | 読取範囲の基点となる座標(左上の点)のy座標 |
| 7 | width | 整数 | 必須 | 読取範囲の幅 |
| 8 | height | 整数 | 必須 | 読取範囲の高さ |
| 9 | type | 文字列 | | バーコードの形式を指定
(未指定の場合 NW7) |
| 10 | length | | | (使用しない) |
| 11 | ItemName | 文字列 | 必須 | 項目名 |
4.3.6. 出力情報(画像抽出)
| No. | 項目名 | 書式 | 必須 | 説明 |
|---|
| 1 | セクションID | 5 | 必須 | |
| 2 | シーケンス番号 | | | (使用しない) |
| 3 | SubImageGroupID | 文字列 | 必須 | サブ画像のグループ名 |
| 4 | レコードID | | | (使用しない) |
| 5 | x | 整数 | 必須 | 読取範囲の基準となる座標(左上の点)のx座標 |
| 6 | y | 整数 | 必須 | 読取範囲の基点となる座標(左上の点)のy座標 |
| 7 | width | 整数 | 必須 | 読取範囲の幅 |
| 8 | height | 整数 | 必須 | 読取範囲の高さ |
| 9 | type | | | (使用しない) |
| 10 | length | | | (使用しない) |
| 11 | 項目名 | 文字列 | 必須 | 項目名 |
5. 出力
OCRの結果をOUTPUTフォルダへ出力します。
5.1. 共通
すべての形式で出力される項目です。
| No. | 項目名 | 説明 |
|---|
| 1 | Image | ファイル名(複数ページファイルの場合はページ分割後) |
| 2 | Image_jshfilename | ファイルパス(処理成功/失敗移動先) |
| 3 | modifyDate | インプットファイルの更新日時
yyyy-MM-ddThh:mm:ss |
| 4 | processDate | 処理完了日時
yyyy-MM-ddThh:mm:ss |
| 5 | result | true:処理成功
false:処理失敗 |
| 6 | original | inputファイル名 |
| 7 | original_jshfilename | inputファイルパス(デバッグフォルダ内へ移動) |
| 8 | Image_for_display | 表示用画像の絶対パス
表示用画像の生成時に自動でヘッダ項目に追加される
複数ページ画像が入力の場合、最終ページのCSVにのみ記載される(表示用画像は複数ページ画像が入力の場合、常に複数ページPDFを生成するため) |
※共通設定ファイルにて出力する項目の変更が可能です。
デフォルト:HEADER_ITEM= Image, Image_jshfilename, modifyDate, processDate, result
5.2. CSV
AIRead独自のCSV形式で出力されます。
| No. | 項目名 | 説明 |
|---|
| 1 | ItemName | 項目名 |
| 2 | Page | 該当のメタデータが出現するページの番号(0 開始) |
| 3 | GID | フォーマット定義ファイルで指定したグループID |
| 4 | RID | フォーマット定義ファイルで指定したレコードID |
| 5 | Value | 取得した値 |
| 6 | conf | 文字認識の信頼度
値が大きいほど正解している可能性が高い(MAX100)
※チェックマークの場合はテンプレート領域に対する黒領域の割合(数値) |
| 7 | x | 抽出範囲の左上の点のx座標(ピクセル) |
| 8 | y | 抽出範囲の左上の点のy座標(ピクセル) |
| 9 | w | 抽出範囲の幅(ピクセル) |
| 10 | h | 抽出範囲の高さ(ピクセル) |
| 11 | ImagePath | コンポーネント画像のパス
CREATE_HW_COMP_IMAGE=falseの場合の値はnull |
| 12 | TableName | 明細名(座標指定ではGIDと同じ値が自動的に出力されます) |
※共通設定ファイルにて出力する項目の変更が可能です。
デフォルト:CSV_COLUMN_ITEM=ItemName,Page,GID,RID, Value,conf,x,y,w,h
“ItemName”,”Page”,”GID”,”RID”,”Value”,”conf”,”x”,”y”,”w”,”h”
“Image”,”-1″,”-1″,”-1″,”sample1.jpg”,”-1″,”-1″,”-1″,”-1″,”-1″
“Image_jshfilename”,”-1″,”-1″,”-1″,”C:\AIRead\success\sample1.jpg”,”-1″,”-1″,”-1″,”-1″,”-1″
“modifyDate”,”-1″,”-1″,”-1″,”2018-08-16T18:10:27″,”-1″,”-1″,”-1″,”-1″,”-1″
“processDate”,”-1″,”-1″,”-1″,”2018-08-25T00:28:27″,”-1″,”-1″,”-1″,”-1″,”-1″
“result”,”-1″,”-1″,”-1″,”true”,”-1″,”-1″,”-1″,”-1″,”-1″
“id”,”0″,””,”-1″,”order”,”100″,”-1″,”-1″,”-1″,”-1″
“tok_cd”,”0″,””,”-1″,”100″,”97″,”307″,”688″,”510″,”170″
“Tel”,”0″,””,”-1″,”03-2345-6789″,”95″,”307″,”951″,”1450″,”170″
“Month”,”0″,””,”-1″,”10″,”97″,”307″,”1207″,”200″,”170″
“Day”,”0″,””,”-1″,”31″,”99″,”620″,”1207″,”200″,”170″
“haikb”,”0″,””,”-1″,”1″,”99″,”938″,”1207″,”85″,”170″
“timekb”,”0″,””,”-1″,”3″,”99″,”1350″,”1207″,”85″,”170″
“Itemcd0″,”0″,”detail”,”0″,”123″,”100″,”407″,”1745″,”627″,”170″
“Amount0″,”0″,”detail”,”0″,”30″,”100″,”2015″,”1745″,”623″,”170″
“Wrapping0″,”0″,”detail”,”0″,”20″,”100″,”2687″,”1745″,”314″,”170″ |
5.3. CSV4DB
一般的なカンマ区切りのCSV形式です。
1ページ1行で出力します。
- OUTPUT_FORMAT: CSV4DB
- 出力イメージ:
“id”,”tok_cd”,”Tel”,”Month”,”Day”,”haikb”,”timekb”,”Itemcd0″,”Amount0″,”Wrapping0″
“order”,”100″,”03-2345-6789″,”10″,””,””,””,”123″,”30″,”20″ |
5.4. XML
XML形式で出力します。
| No. | 項目名 | 説明 |
|---|
| 1 | field | |
| 2 | id | 項目名 |
| 3 | conf | 文字認識の信頼度
値が大きいほど正解している可能性が高い(MAX100)
※チェックマークを指定している場合はテンプレート領域に対する黒領域の割合(数値) |
| 4 | x | 抽出範囲の左上の点のx座標(ピクセル) |
| 5 | y | 抽出範囲の左上の点のy座標(ピクセル) |
| 6 | width | 抽出範囲の幅(ピクセル) |
| 7 | hight | 抽出範囲の高さ(ピクセル) |
| 8 | value | 取得した値 |
<?xml version=”1.0″ encoding=”UTF-8″ standalone=”no”?>
<order>
<Image>sample1.jpg</Image>
<Image_jshfilename>C:/AIRead/success/sample1.jpg</Image_jshfilename>
<modifyDate>2018-08-16T18:10:28</modifyDate>
<processDate>2018-10-22T20:51:21</processDate>
<result>true</result> |
<id>order</id>
<field conf=”98″ height=”170″ id=”tok_cd” width=”510″ x=”307″ y=”688″>
<value>100</value>
</field>
<field conf=”97″ height=”170″ id=”Tel” width=”1450″ x=”307″ y=”951″>
<value>03-2345-6789</value>
</field>
<field conf=”99″ height=”170″ id=”Month” width=”200″ x=”307″ y=”1207″>
<value>10</value>
</field>
<field conf=”100″ height=”170″ id=”Day” width=”200″ x=”620″ y=”1207″>
<value/>
</field>
<field conf=”100″ height=”170″ id=”haikb” width=”85″ x=”938″ y=”1207″>
<value/>
</field>
<field conf=”100″ height=”170″ id=”timekb” width=”85″ x=”1350″ y=”1207″>
<value/>
</field>
<detail>
<row id=”0″>
<field conf=”99″ height=”170″ id=”Itemcd0″ width=”627″ x=”407″ y=”1745″>
<value>123</value>
</field>
<field conf=”99″ height=”170″ id=”Amount0″ width=”623″ x=”2015″ y=”1745″>
<value>30</value>
</field>
<field conf=”99″ height=”170″ id=”Wrapping0″ width=”314″ x=”2687″ y=”1745″>
<value>20</value>
</field>
</row> |
5.5. XML for WAGBY
AIRead Screen Designer(Wagby)との連携が可能なXML形式で出力します。
※”Wagby”とはノンプログラミングでWeb業務アプリケーションを開発できるツールです。
- OUTPUT_FORMAT: XMLWAGBY
- 項目:
| No. | 項目名 | 説明 |
|---|
| 1 | [ItemName]_conf | 文字認識の信頼度
値が大きいほど正解している可能性が高い(MAX100)
※チェックマークの場合はテンプレート領域に対する黒領域の割合(数値) |
<?xml version=”1.0″ encoding=”UTF-8″ standalone=”no”?>
<order>
<Image>sample1.jpg</Image>
<Image_jshfilename>C:/AIRead/success/sample1.jpg</Image_jshfilename>
<modifyDate>2018-08-16T18:10:28</modifyDate>
<processDate>2018-10-22T21:00:08</processDate>
<result>true</result>
<id>order</id>
<id_conf>100</id_conf>
<tok_cd>100</tok_cd>
<tok_cd_conf>98</tok_cd_conf>
<Tel>03-2345-6789</Tel>
<Tel_conf>97</Tel_conf>
<Month>10</Month>
<Month_conf>99</Month_conf>
<Day/>
<haikb/>
<timekb/>
<detail>
<Itemcd0>123</Itemcd0>
<Itemcd0_conf>99</Itemcd0_conf>
<Amount0>30</Amount0>
<Amount0_conf>99</Amount0_conf>
<Wrapping0>20</Wrapping0>
<Wrapping0_conf>99</Wrapping0_conf>
</detail> |
6. AIRead Viewer付OCR機能
batで実行した出力結果をAIRead Viewer(以下 Viewer)で結果を確認しながら、修正を行うことができます。
6.1. Viewer付OCR 実行batファイル
実行結果をViewerで表示する際は、<AIReadインストールフォルダ>\run_kw_with_viewer.bat でOCRを実行します。
6.2. Viewer付OCR実行時の引数
Viewer付OCRの実行は、下記のコマンドで行います。
| OcrExecuter.exe –formatfile [フォーマット定義ファイル] –imagefile [画像ファイルパス] –settingfile [SettingFile] |
| No. | 引数 | 説明 |
|---|
| 1 | –formatfile [フォーマット定義ファイル] | O]CR時に抽出を行うフォーマット定義ファイルのパスを指定 |
| 2-1 | –imagefile [画像ファイルパス] | 読み取り対象の画像のファイルパスを指定 |
| 2-2 | –imagedir [画像フォルダパス] | 読み取り対象の画像が格納されたフォルダのパスを指定 |
| 3 | –settingfile [SettingFile] | 共通設定ファイルを指定 |
※–imagefile と –imagedir はどちらか一方を指定します
6.3. Viewer付OCR の実行
引数を指定し、run_kw_with_viewer.bat をダブルクリックで実行します。

6.4. Viewer上での確認
4.2.11 AIReadの実行結果を確認を参照ください。
7. 仕分け付きOCR機能
あらかじめテンプレートとなる画像とその画像に使用する帳票定義を登録しておくことで、入力画像に対して最も似ているテンプレートを自動で判定し、その帳票定義を利用したOCRの実行が可能です。
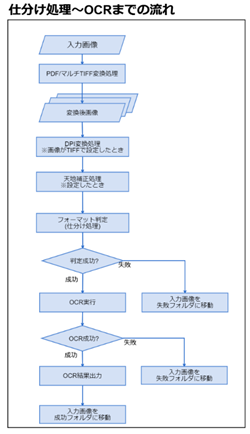
7.1. 概要
7.1.1. 処理の流れ
仕分け付きOCRの処理は下記のように進みます。
- 入力画像が複数ページであれば、ページごとに分割
- 画像がTIFFであれば、DPI変換
※「TIFFを300DPIに変換してからOCRを実行する」を設定している場合 - 画像の回転補正
※「回転補正を行う」を設定している場合 - 3.の画像でフォーマット判定
- 判定に成功したら、フォーマットの帳票定義を使ってOCRを行う
- 判定に失敗した場合、失敗フォルダに入力画像を移動する
7.1.2. フォーマット判定について
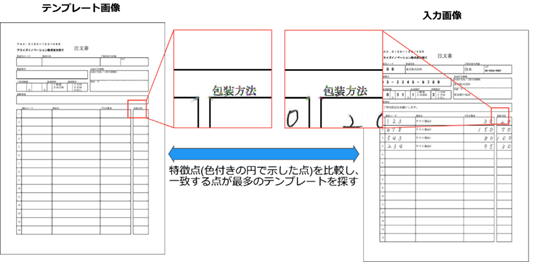
フォーマット判定は2段階に分かれております。
1段階目では画像全体から特徴的な箇所(特徴点)を抽出し、各テンプレート画像と入力画像を比較して最もマッチした画像を持つグループを判定します(大まかな仕分け)。
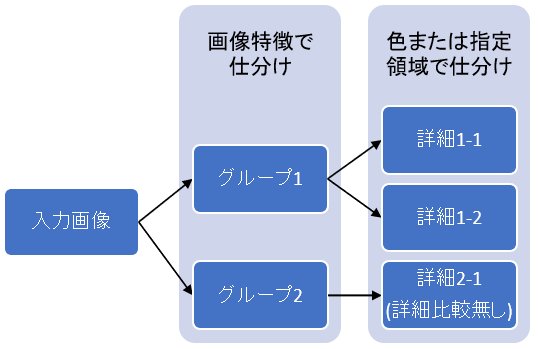
2段階目ではグループ内の画像に対して色または指定領域のみでの画像比較を行います(詳細仕分け)。
色での判定は画像の見た目はほとんど似ているが色違いの帳票を判別したい場合に使います。
指定領域での画像比較は、特定の場所に会社のロゴ等判別しやすい箇所がある場合に使います。
なお、下図のグループ2-詳細1のように、グループに属する画像が1つしかない場合は詳細な判定は行わずに判定結果が確定します。
7.2. 仕分け定義フォルダの構成
仕分けの定義は仕分け定義フォルダで行います。
仕分け定義フォルダは以下の通りに構成します。
仕分け定義フォルダの配置場所は任意ですが、フォルダの絶対パスに日本語を含まないでください。
?ClassifyDir(任意の英数をつかったフォルダ名) ——— 1. 仕分け定義フォルダ
├?option.csv (固定名) ——— 2. 仕分け定義ファイル
├?setting.ini (固定名) ——— 3. 仕分け設定ファイル
└?Templates (固定名) ——— 4. テンプレートフォルダ
└?1 ——— 5. 大まかな仕分けフォルダ
└?1 ——— 6. 詳細仕分けフォルダ
└? template.jpg (固定名) ——— 7. テンプレート画像
└?2
└? template.jpg(固定名)
└?2
└?1
└? template.jpg (固定名)
:
| No. | 名称 | 説明 |
| 1 | 仕分け定義フォルダ | 仕分け定義を格納するフォルダ
フォルダ名は任意 |
| 2 | 仕分け定義ファイル | テンプレート画像に紐づく仕分け定義を記載したファイル(csv形式) |
| 3 | 仕分け設定ファイル | 仕分けに使用する設定を記載する |
| 4 | テンプレートフォルダ | テンプレート画像を格納するフォルダ |
| 5 | 大まかな仕分けフォルダ | 大まかな仕分けのグループを表すフォルダ
数字で1,2…と順につける |
| 6 | 詳細仕分けフォルダ | 詳細仕分けの画像を配置するフォルダ
数字で1,2…と順につける |
| 7 | テンプレート画像 | 入力画像と比較するテンプレート画像(JPEG形式)
名前はtemplate.jpg固定で、1つの詳細仕分けフォルダに1つのテンプレート画像を配置する |
7.3. 仕分け定義ファイルの作成
仕分け定義ファイルはCSV形式で下記のように記載してください。
1,1,S,order,1,0,10,10,50,50
1,2,S,order2,1,0,10,10,50,50
2,1,E,Invoice,0,0,,,, |
・文字エンコード:UTF-8
・改行コード:LF
CSV中の各列の意味は下記の通りです。
| No. | 名称 | 説明 |
| 1 | グループ番号 | 大まかな仕分けのグループ番号
大まかな仕分けフォルダ名を指定する |
| 2 | 詳細番号 | 詳細仕分けの番号
詳細仕分けフォルダ名を指定する |
| 3 | 抽出モード | 抽出モードの設定
S : 座標指定
E : キーワード抽出
W : 表検出付全文OCR
※キーワード抽出はEnterprise版のみ使用可 |
| 4 | フォーマットID | OCR時に使用するフォーマットID |
| 5 | 色判定フラグ | 詳細仕分けに色の類似度合いを使用するかのフラグ
0 : 使用しない(デフォルト)
1 : 使用する
※同一グループ内では同一の設定にしてください |
| 6 | 領域指定フラグ | 詳細仕分けで画像の注目する領域を絞ったマッチングを行うかのフラグ
0 : 行わない(デフォルト)
1 : 行う
※同一グループ内では同一の設定にしてください
※色判定と同時に使うことはできません(両方設定されていた場合、色判定のみ行います) |
| 7 | 指定領域始点X | 領域指定の左上のX座標(左上原点、単位はピクセル) |
| 8 | 指定領域始点Y | 領域指定の左上のY座標(左上原点、単位はピクセル) |
| 9 | 指定領域横幅 | 領域指定の横幅(単位はピクセル) |
| 10 | 指定領域縦幅 | 領域指定の縦幅(単位はピクセル) |
7.4. 仕分け設定ファイル
仕分け設定ファイルは下記のように記載してください。
maxFeatures=2000
matchCtTh=50
sizeDiffTh=-1 |
・文字エンコード:UTF-8
・改行コード:LF
各項目の意味は下記の通りです。
| No. | 項目名 | 書式 | 説明 |
| 1 | maxFeatures | 1以上の整数値 | 画像の比較に使用する特徴的な点を検出する数
多くすると仕分け精度が上がる傾向にある一方、処理時間が増加する
(デフォルト:2000) |
| 2 | matchCtTh | 0以上の整数値 | 大まかな仕分け時に、入力画像とテンプレート画像が似ていると判断するのに最低限必要な特徴点のマッチ数
全てのテンプレート画像に対して特徴点のマッチ数がこの値に達しない場合、判定失敗となる
この値を上げると厳密な判定ができるが、判定失敗になる画像が増えやすくなる
(デフォルト:50) |
| 3 | sizeDiffTh | -1以上の整数値 | テンプレート画像と入力画像のピクセルでの面積を比較し、その差がこの値より大きい場合そのテンプレート画像との比較をスキップする
-1を指定した場合、このスキップ処理は行われない
(デフォルト:-1) |
7.5. フォーマット専用設定の準備(任意)
仕分け付きOCR時には、フォーマットIDごとに専用のOCR設定を使用することが可能です。
この機能により、フォーマットごとに出力先フォルダの変更や、画像処理設定の指定が可能です。
7.5.1. フォーマット専用設定の作成
フォーマット専用設定のフォーマットは、3.2. 共通設定ファイルで設定に記載の内容と同じです。
下記のように、上書きしたい設定だけ記載することが可能です。
| [AIRead] OUTPUT=./output/order/ |
ただし、下記の設定は仕分け処理の前後で変更できない設定であるため上書きすることができません。
記載があっても無視されます。
| No. | 項目名 | 書式 | 説明 |
| 2 | INPUT | 文字列 | 画像を取り込むフォルダパス |
| 7 | LOGS_PATH | 文字列 | 照合結果ログ、実行ログを出力するフォルダパス |
| 8 | LOGS_LEVEL | 0~3 | 実行ログのレベル
0:DEBUG
1:INFO
2:WARNING
3:ERROR |
| 21 | LOG_ROTATION_SIZE | 0以上の整数 | ログファイル1つの最大サイズ(MB)
0の場合、実行単位でログを出力する |
| 22 | LOG_MAX_SIZE | 0以上の整数 | ログファイルを保存する最大容量(MB)
0の場合、削除しない ※LOG_ROTATION_SIZEより大きい値を設定すること |
| 23-1 | PROFILE_CONFIG_DIR | 文字列 | 座標指定用帳票定義フォルダのパス |
| 23-2 | PROFILE_KWCONFIG_DIR | 文字列 | キーワード指定用帳票定義フォルダのパス |
※No.は3.2. 共通設定ファイルで設定の内容に合わせております。
7.5.2. フォーマット専用設定ファイルの配置
フォーマット専用の設定ファイルは、各帳票定義フォルダに配置します。
配置しない場合は共通設定ファイルの内容がそのまま使われます。
7.5.2.1. 座標指定のフォーマット専用設定ファイル
座標指定のフォーマット専用設定ファイルは、下記のように各帳票定義フォルダ中にAIRead_setting.iniのファイル名で配置します。
?AIRead_conf (座標指定/全文OCR兼用の帳票定義フォルダ)
└?FormID (任意のフォームID)
├?AIRead_format.ini (固定名)
└?AIRead_setting.ini (固定名)
7.5.2.2. 全文OCR専用設定ファイル
全文OCRの場合、下記のように個別設定ファイルのみを各帳票定義フォルダ中にAIRead_setting.iniのファイル名で配置します。
?AIRead_conf (座標指定/全文OCR兼用の帳票定義フォルダ)
└?FormID (任意のフォームID)
└?AIRead_setting.ini (固定名)
7.5.2.3. キーワード指定のフォーマット専用設定ファイル
キーワード指定の場合、各帳票定義フォルダ中にAIRead_setting.iniのファイル名で配置します。
?AIRead_conf_kw (キーワード指定用の帳票定義フォルダ)
└?FormID (任意のフォームID)
├? IDE_metadata_setting.ini (固定名)
├? IDE_setting.ini (固定名)
└?AIRead_setting.ini (固定名)
7.6. 実行方法
仕分け付きのOCRの実行は、仕分けの登録と実行の2段階で行います。
7.6.1. 仕分け登録
配置されたテンプレート画像の登録は、下記のコマンドで行います。
| “%AIREAD_JAVA%/java” -jar “%AIRead_HOME%\IDELibrary\lib\AIReadEE.jar” -R [仕分け定義フォルダ] -s [SettingFile] |
- オプション: バッチの中身は引数で書き換えることができます。
| No. | 引数 | 説明 |
|---|
| 1 | -R [仕分け定義フォルダ] | 仕分け定義が格納されたフォルダを指定 |
| 2 | -s [SettingFile] | 共通設定ファイルを指定 |
※run_register.bat はサンプル帳票の実行ファイルです。ダブルクリックで実行できます。
7.6.2. 仕分け付きOCRの実行
仕分け付きOCRの実行は、下記のコマンドで行います。
| “%AIREAD_JAVA%/java” -jar “%AIRead_HOME%\IDELibrary\lib\AIReadEE.jar” -A [仕分け定義フォルダ] -s [SettingFile] |
- オプション: バッチの中身は引数で書き換えることができます。
| No. | 引数 | 説明 |
|---|
| 1 | -A [仕分け定義フォルダ] | 仕分けに使用するフォルダを指定 |
| 2 | -s [SettingFile] | 共通設定ファイルを指定 |
※run_assort.bat はサンプル帳票の実行ファイルです。ダブルクリックで実行できます。