目次
1. 概要
AIReadは、活字文字認識で使用するモデル(AIのエンジン)へ、フォントや単語を追加学習させることで、活字文字認識の精度を高めることができます。
本ソフトウェアは、Windowsのフォント、追加登録された単語から学習データを自動作成し追加学習を行います。
2. インストール
2.1. 動作環境
| OS | Windows 10、Windows Server 2012 R2 (x64) |
| 物理メモリ | 8 GB 以上推奨 |
| 前提条件 | AIRead v2.1.4以降がインストールされていること |
2.2. フォルダ構成
?<インストールディレクトリ>
┣?excute
┃┗?tessdata
┃┗?train_text
┣ 1_text2img.bat
┣ 2_train.bat
┣ check_font.bat
┣ TesseractTrainner.jar
┣ learning.conf
┣ ControlzEx.dll
┣ GUI.exe
┣ GUI.exe.config
┣ MaterialDesignColors.dll
┣ MaterialDesignThemes.Wpf.dll
┣ MaterialDesignThemes.Wpf.xml
┗ System.Windows.Interactivity.dll
※テキストファイルの文字コードはUTF-8で保存してください
2.3. インストール手順
2.3.1. インストール
①TrainStudioSetUp.exe を実行します。
② TrainStudioSetUp.exe実行後に、インストーラ画面が表示されます。

③ インストール前に、注意事項が表示されます。
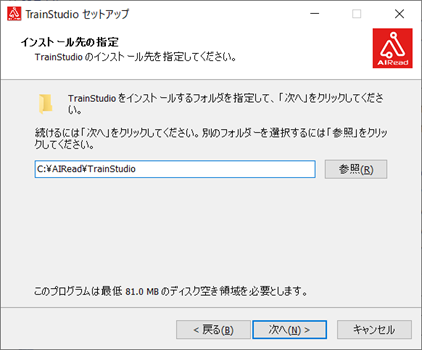
④ インストール先を指定します。
通常は <AIREAD_HOME>\TrainStudio を指定してください。
⑤ TrainStudioをスタートメニューへ追加します。
⑥ 確認画面からインストールを開始します。
⑦ インストールが完了しました。

2.3.2. アンインストール
<AIREAD_HOME>\uninstall に自動生成されるTrainStudio_unins.exeを実行します。
TrainStudioHW_unins.exeを実行することで、<AIREAD_HOME>\TrainStudioが削除されます。
3. 実行手順
3.1. TrainStudioの起動
3.2. 教師データの準備
3.2.1. 単語リストを作成する
活字学習メニューの単語リスト作成タブで行います。
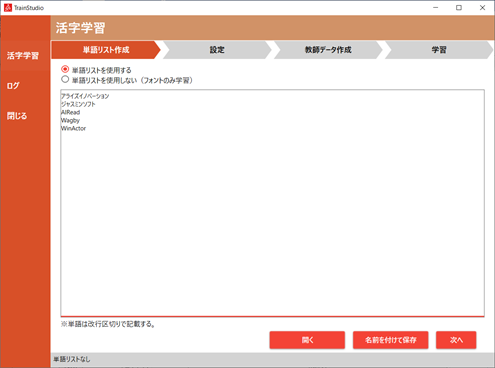
| No. | 項目名 | 説明 |
| 1 | 単語リストを使用する/しない | 単語学習をする・しない を指定します |
| 2 | 単語リスト | 単語リストの編集が出来ます 1行につき1単語を指定します |
| 3 | [開く] | 既存の単語リストファイルを読込みます |
| 4 | [名前を付けて保存] | 単語リスト欄の内容を、ファイルに保存します |
| 5 | [次へ] | 設定画面に移動します |
3.2.1.1. 単語登録を行う場合
単語リストとは、登録・学習する単語の一覧を記載したテキストです。
単語登録を行う場合、「単語リストを使用する」を選択し、登録したい単語を1行に1単語ずつ記入していきます。
記入後、「次へ」ボタンを押して設定画面に進みます。
既存の単語リストを使用する場合、「開く」をクリックして使用したい単語リストを選択してくだい。
※単語リストは、文字コード(UTF-8)、改行コード(LF)である必要があります
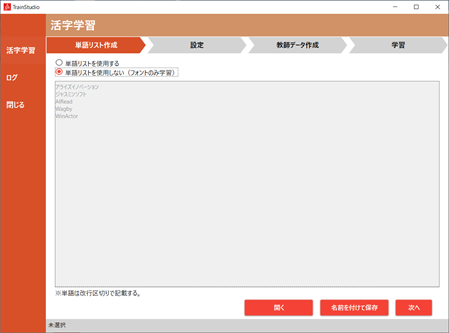
3.2.1.2. 単語登録を行わない(フォント学習のみを行う)場合
フォント学習のみを行う場合、「単語リストを使用しない(フォントのみ学習)」を選択し、「次へ」ボタンを押して設定画面へ進んでください。
3.2.2. 設定を行う
設定画面で学習に必要な設定を行います。
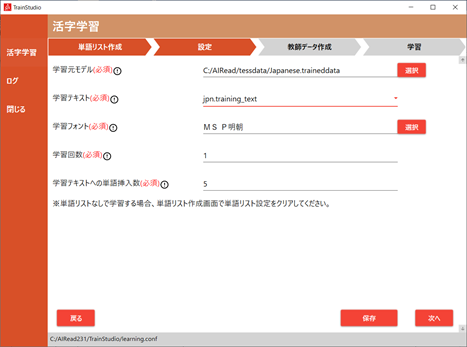
| No. | 項目名 | 説明 |
| 1 | 学習元モデル | 学習させたいモデル(拡張子”.traineddata”)のファイルを指定します |
| 2 | 学習テキスト | 教師データを作成するためのテキストファイルです 1.の学習元モデルによって以下を選択してください Japanese:日本語(jpn.training_text) Latin:英語(eng.training_text) |
| 3 | 学習フォント | 学習するフォントを選択します(複数選択可能) 詳細は、次項「学習フォント選択」に記載します |
| 4 | 学習回数 | 学習を行う回数を指定します データ量によりますが、1~5回程度を目安に指定してください |
| 5 | 学習テキストへの単語挿入数 | 単語リストに登録した単語を教師データに挿入する回数を指定します |
| 6 | [戻る] | 単語リスト作成画面に戻ります |
| 7 | [保存] | 設定値を保存します |
| 8 | [次へ] | 教師データ作成画面に移動します |
3.2.2.1. 学習フォント選択
選択ボタンを押すと、フォント選択画面が表示されます。
フォント選択画面で、使用するフォントを選択します(複数選択可)。
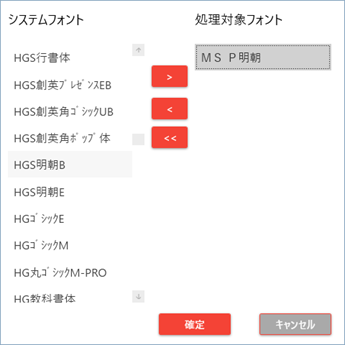
| No. | 項目名 | 説明 |
| 1 | システムフォント | 使用可能、かつ学習対象に選択していないフォント一覧 |
| 2 | 処理対象フォント | 学習対象に選択しているフォント一覧 |
| 3 | [>] | システムフォントで選択したフォントを学習対象とします |
| 4 | [<] | 処理対象フォントで選択したフォントを学習対象から外します |
| 5 | [<<] | 全ての処理対象フォントを学習対象から外します |
| 6 | [確定] | 操作結果を確定しダイアログ画面を閉じます |
| 7 | [キャンセル] | 操作結果を破棄しダイアログ画面を閉じます |
設定入力後、「保存」ボタンを押してください。
次へボタンを押して教師データ作成画面に進みます。
3.2.3. 教師データ作成
教師データ作成画面で、先に設定した、単語リストから教師データを作成します。
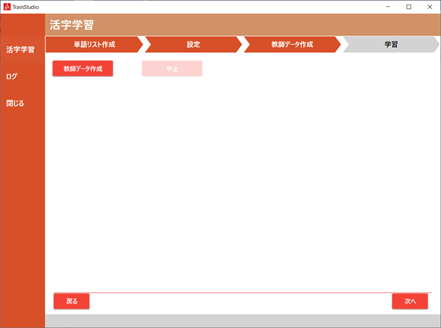
| No. | 項目名 | 説明 |
| 1 | [教師データ作成] | 単語リスト、学習テキストから、教師データの作成を開始します |
| 2 | [中止] | 教師データの作成を中断させます |
「教師データ作成」を押すと、教師データの作成が行われます。
処理完了後、次へボタンを押して学習画面に進みます。
3.2.4. 学習セットの選択
学習画面で、教師データセットと学習後のモデルを出力するフォルダを指定します。
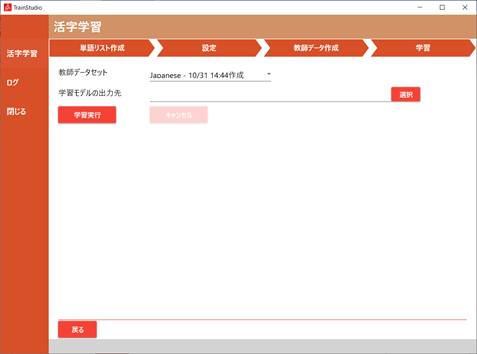
| No. | 項目名 | 説明 |
| 1 | 教師データセット | 「教師データ作成」画面で作成した教師データセットの一覧が表示されます 学習させる教師データセットを選択します |
| 2 | 学習モデルの出力先 | 学習後のモデルを出力するフォルダを指定します |
| 3 | [学習実行] | 学習を開始します |
| 4 | [キャンセル] | 学習を中断させます |
3.3. 実行
3.3.1. TrainStudioの起動
<直接起動>
<AIREAD_HOME>\TrainStudio\TrainStudio.exeをダブルクリックで起動します。
<スタートから起動>
スタートボタン→AIRead追加学習GUI(手書き)を選択し、起動します。
3.3.2. 学習実行
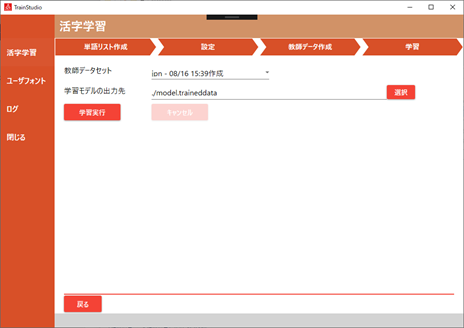
活字学習メニューの学習タブで行います。
学習実行ボタンを押すと学習がはじまります。
学習が成功すると、下記のダイアログを表示します。
※学習中に表示されるエラーについて※
ログに下記のようなエラーがまれに表示されます。
Encoding of string failed! Failure bytes: ffffffe6 ffffff85 ffffffa8 …
Can't encode transcription: ・・・・・ in language ''
これは、使用したフォントが学習テキストの一部の文字に対応していなかった場合に表示されます。日本語の学習回数1回につき、~20回程度の出現回数であれば学習に大きな影響はありません。
3.4. 学習した辞書データの反映
辞書データをAIReadに反映するには、以下の作業を行います。
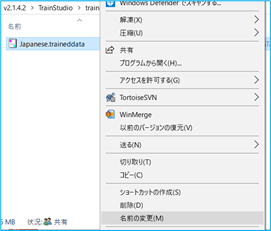
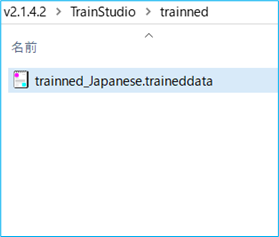
① 辞書データの名前を変更します
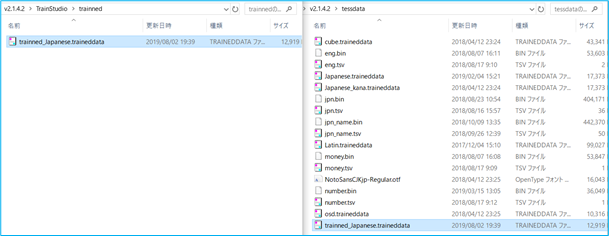
② 辞書データをAIReadの活字モデルフォルダに配置します
<AIREAD_HOME>/tessdataに学習後の辞書データを移動します。
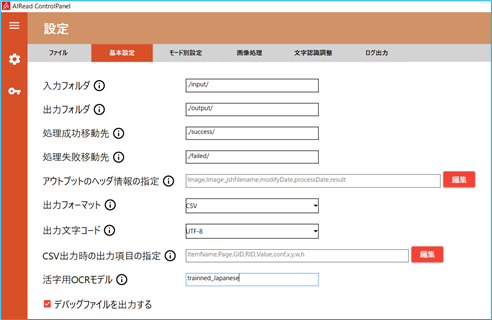
③ コントロールパネルを立ち上げ、基本設定タブの「活字用OCRモデル」に辞書データファイルの名前(拡張子.traineddataを除いたもの)を設定します
3.5. ログの確認
メニューから「ログ」を選択すると、下記の画面を表示します。
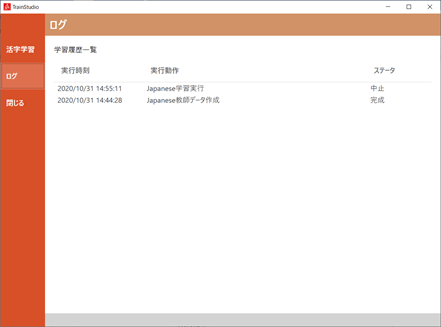
| No. | 項目名 | 説明 |
| 1 | 学習履歴一覧 | 過去の教師データ作成、および学習時のログのリストを表示します リストの項目をダブルクリックすると、ログ詳細画面を別ウインドで表示します |
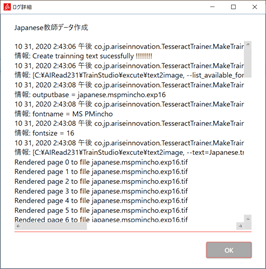
| No. | 項目名 | 説明 |
| 1 | [OK] | ログ詳細画面を閉じます |
4. コマンドラインで実行
4.1. 教師データの準備
下記のデータを準備してください。
| No. | 項目名 | 説明 |
| 1 | 辞書データ(.traineddata) | 各言語の辞書データ AIReadのtessdataフォルダにある拡張子”.traineddata”のファイル |
| 2 | 単語リスト (word list) | 登録・学習する単語の一覧を記載したテキストファイル 記載された単語を登録(学習)する教師データを作成する |
| 3 | 学習テキスト (train text) | 教師データを作成するためのテキストファイル |
| 4 | 教師データ | 単語リスト、学習テキストから画像ファイル(.tif)と文字の座標データ(.box)からなる教師データを作成する 教師データから文字の形(フォント)と並びを学習する 同じ単語でも複数回学習させることによって、その単語の認識率が向上する可能性がある |
- 追加学習するモデル(.traineddata)
- 追加学習するベースとなるモデルファイル”.traineddata”を、AIReadのtessdataフォルダから選択してください。
- 学習設定ファイルの”input_file”にファイルパスを記載してください。
- 単語リスト(word list)
- 登録・学習する単語の一覧を記載したテキストファイルを作成してください。記載された単語から教師データを作成します。
- 記載された単語をリストとして辞書へ新規/追加で登録します。
- 学習設定ファイルの”word_list”に単語リストのファイルパスを記載してください。
- 学習テキスト(train text)
- 教師データを作成するためのテキストファイルを作成してください。記載された文字から教師データを作成します。
- 学習設定ファイルの” include_text_file”に学習テキストのファイルパスを記載してください。
4.2. 実行
4.2.1. 教師データ作成
以下のコマンドを実行してください。
| > 1_text2img.bat |
- 処理内容
- 学習テキストを生成(学習テキストの指定がない場合)
- 学習テキストから教師データ(画像(.tif)と座標情報(.box))を生成
4.2.2. 学習の実行
以下のコマンドを実行してください。
| > 2_train.bat |
- 処理内容
- モデルへ単語登録
- 学習画像と座標情報をモデルへ追加学習
- “output”フォルダへ学習したモデルを出力
4.3. 学習した辞書データの反映
辞書データをAIReadに反映するには、以下の作業をおこないます。
- 辞書データをAIReadの活字モデルフォルダに配置します
<AIReadインストールフォルダ>/tessdata
- コントロールパネルを立ち上げ、基本設定タブの「活字用OCRモデル」に辞書データファイルの名前(拡張子.traineddataを除いたもの)を設定します
5. 設定
5.1. 学習設定ファイル
学習に必要な設定情報を記載します。
“項目名=値”の書式で記載します。
- ファイル名:learning.conf
- 設定内容:
| No. | 項目名 | 説明 |
| 1 | train_mode | 1:新規単語登録(既存の単語辞書を削除して新規作成) 2:追加単語登録(既存の単語辞書へ追加) |
| 2 | input_file | 追加学習の対象となるモデルのファイルパス |
| 3 | include_text_file | 学習テキスト(train text)のファイルパス 指定しない場合は自動生成 |
| 4 | list_train_font | 学習するフォント セミコロン(;)で区切ることで複数指定可 |
| 5 | list_train_size | 学習するテキストのフォントサイズ(pt) カンマで区切ることで複数指定可 12以上の数値を指定する |
| 6 | font_style | 学習するフォントのスタイル 0:Plain ※太字・斜体はサポート対象外となりました |
| 7 | word_list_load_size | -1:word listを使用しない 0:word listに含まれるすべての単語をtrain textにランダムで追加 1~:word listの先頭から指定した行数分を取り出し、教師データにランダムで挿入 |
| 8 | word_list | 単語リストのファイルパス 改行区切りで記載 ※文字コードはUTF-8(BOMなし) |
| 9 | word_list_load_times | word listの単語を教師データに挿入する回数 |
| 10 | add_number | 教師データに挿入する数字のセット数 1セットは4ケタの数字をランダムで作成して挿入する |
| 11 | add_symbol | 教師データに挿入する記号のセット数 hankaku_symbol、zenkaku_symbolで設定された文字を教師データにランダムで挿入する |
| 12 | hankaku_symbol | 教師データに含める半角記号 add_symbolが1以上の場合に有効 |
| 13 | zenkaku_symbol | 教師データに含める全角記号 add_symbolが1以上の場合に有効 |
| 14 | add_hankaku_katakana | 教師データに含める半角カタカナの単語数 内部で持っているカタカナの単語リストから挿入 半角カナをフォントとして学習したい場合に使用 |
| 15 | iterations | 学習回数 1回で全ての教師データを1通り学習する |
6. 学習例
6.1. フォントの学習例
単語を追加せずにフォントを学習する場合は以下の設定にします。
| No. | 項目名 | 説明 |
| 1 | train_mode | 2 |
| 2 | include_text_file | “train_text”フォルダのファイルを指定 日本語:jpn.training_text 英語:eng.training_text |
| 3 | list_train_font | 学習するフォントを指定 OSにインストールしているフォントが学習可(※1) |
| 4 | word_list_load_size | -1 |
| 5 | iterations | 5 |
※1 “check_font.bat”コマンドを実行することでフォントの一覧が確認できます。
実行後に出力されるrenderable.txtを確認してください。
6.2. 単語の学習例
認識したい単語(とフォント)を学習する場合は以下の設定にします。
| No. | 項目名 | 説明 |
| 1 | train_mode | 2(or 1) |
| 2 | include_text_file | “train_text”フォルダのファイルを指定 日本語:jpn.training_text 英語:eng.training_text (※2) |
| 3 | list_train_font | 学習するフォントを指定 |
| 4 | word_list_load_size | 0 |
| 5 | word_list | 単語リストのテキストファイルを指定 |
| 6 | word_list_load_times | 5 |
| 7 | iterations | 1 |
※2 デフォルトの学習テキストに単語を混ぜて学習することで、全体のバランスを大きく崩さず
に学習することができます。
7. 制約事項
- それぞれのモデルで学習済みの文字のみ学習可能です。学習済み文字の一覧は以下のファイルを参照してください。
<インストールフォルダ>/excute/tessdata/[言語].lstm-unicharset - 学習テキストは1行ずつ学習します。未学習の文字が含まれている行はスキップするため学習されません。
- “list_train_size”は12以上で設定してください。11以下を設定するとエラーとなり学習されません。