目次
1. 概要
AIReadは、活字文字認識で使用するモデル(AIのエンジン)へ、フォントや単語を追加学習させることで、活字文字認識の精度を高めることができます。
本ソフトウェアは、Windowsのフォント、実帳票の画像から教師データを自動作成し追加学習を行います。
1.1. 対応バージョン
TrainStudio Ver. 3.2.3 は、AIRead Version3.0.0 以降のバージョンに対応しております。
AIRead のバージョンが、v3.0.0 以前の場合は、バージョンアップ後にインストールを行ってください。
1.2. 対応モデル
追加学習に対応しているモデルは、以下の通りです。
- Japanese.traineddata:日本語モデル
- Latin.traineddata:英語モデル
- Japanese_mod.traineddata:日本語モデル(環境依存文字の(株)、(有)、〃が読みやすくなったモデル)
2. 推奨環境
2.1. OS
Windows Server 2012 R2 、 2016 、2019(64bit)
Windows 8.1以上 (64bit)
※必ず64bitです。
2.2. ハードウェア
メモリ 4 GB 以上必須、16 GB 以上推奨
HDD 50 GB 以上の空き領域
CPU 4 Core 以上
システムロケール 日本語 を指定
2.3. ライセンス
ユーザフォントの機能を使用する場合、オンプレミス版のEnterpriseライセンスが必要です。
3. インストールの手順
3.1. インストーラを起動
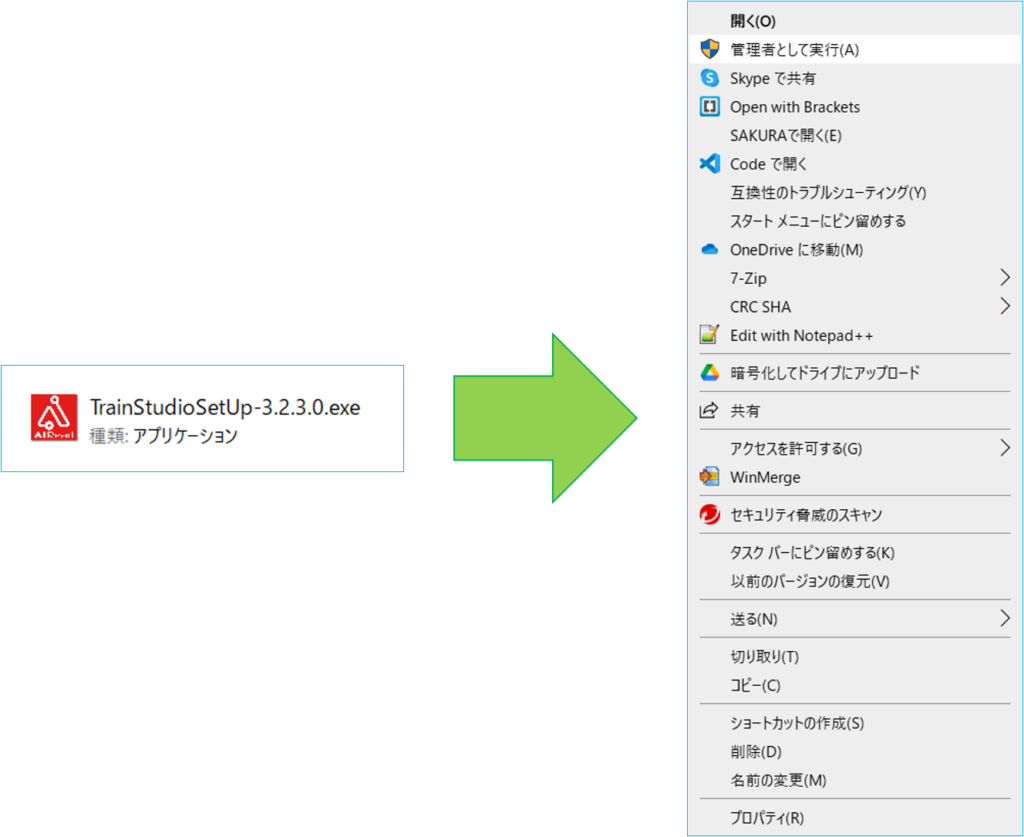
ダウンロードしたTrainStudioSetUp-3.2.3.0.exeを右クリックから管理者権限で実行します。
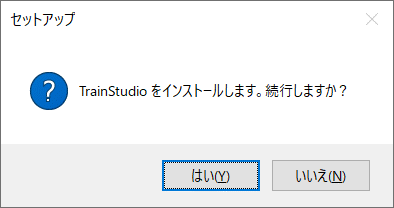
管理者権限で実行後に確認ダイアログが表示されます。
「はい」をクリックします。
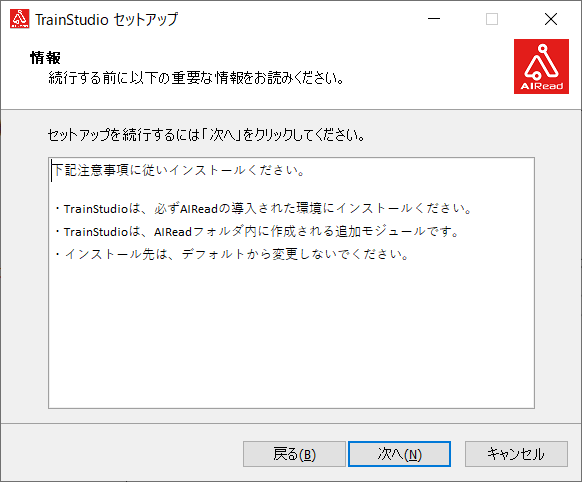
確認ダイアログから、インストールの設定画面に移動します。
「次へ」をクリックします。

3.2. インストールディレクトリの選択
インストール先を選択する際の注意事項が表示されます。
「次へ」をクリックします。
注意事項の確認後、インストールディレクトリ指定画面に移行します。
※必ずAIReadが導入されている環境のAIReadフォルダ内にインストールしてください。
3.3. タスクの選択
インストール時に、スタートメニューに作成するショートカットを選択します。
ショートカットを作成する場合は、チェックボックスで選択してください。(任意)
3.4. インストールの実行
インストーラの設定を確認後、インストールを実行します。
AIRead本体のインストール後に、「3.3. タスクの選択」で選択したショートカットが作成されます。
3.5. インストールの完了
全てのプログラムのインストールが完了すると、完了のダイアログが表示されます。

完了ボタンを押下して、ダイアログを閉じてください。
3.6. 追加モデルの配置
ユーザフォントを作成する際に、jpn.traineddata、eng.traineddata を配置する必要があります。
※jpn.traineddata、eng.traineddata はAIRead 本体に含まれておりません。
ユーザーフォント作成用モデルを解凍します。

解凍したユーザーフォント作成用モデルは<AIREAD_HOME>\tessdata以下に格納してください。
4. TrainStudio機能説明
4.1. TrainStudioの起動
以下のプログラムで、TrainStudioを起動することで、活字学習モジュールを起動することができます。
<AIREAD_HOME>/TrainStudio/TrainStudio.exe
4.2. TrainStudioの各種画面
TrainStudio起動後、左のメニューから画面を切り替えることができます。
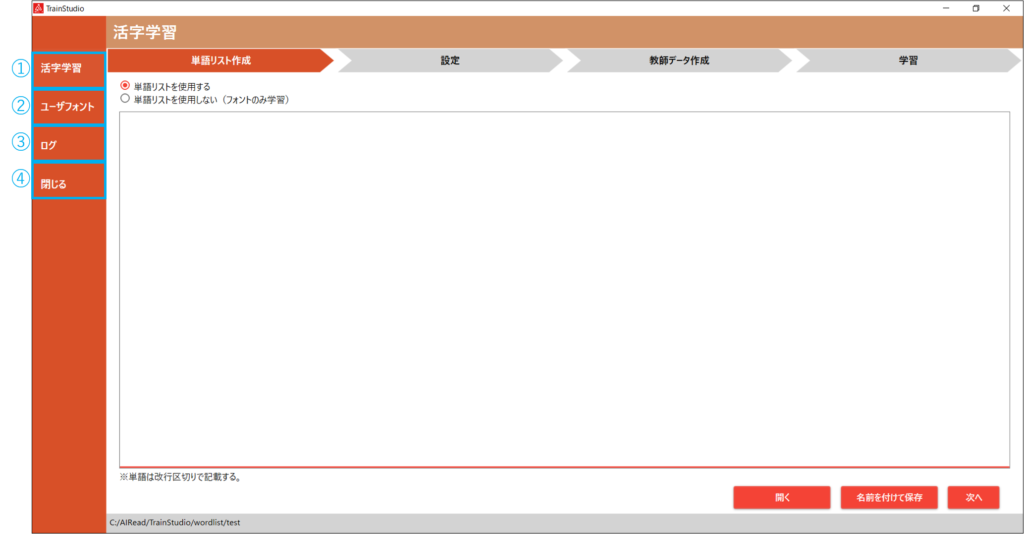
| No. | 機能名 | 説明 |
| 1 | 活字学習 | 単語リストの作成や学習時の設定、追加学習を行う画面です。 |
| 2 | ユーザフォント | 実際の帳票上で使用されている文字から画像を作成し、ユーザフォントとして設定する画面です。 実際の帳票を読み取り、文字を画像として出力を行います。 |
| 3 | ログ | 教師データや追加学習の結果をログとして確認できる画面です。 |
| 4 | 閉じる | TrainStudioを終了します。 |
5. 活字学習の機能説明
5.1. 単語リストを作成する
活字学習メニューの単語リスト作成タブで行います。
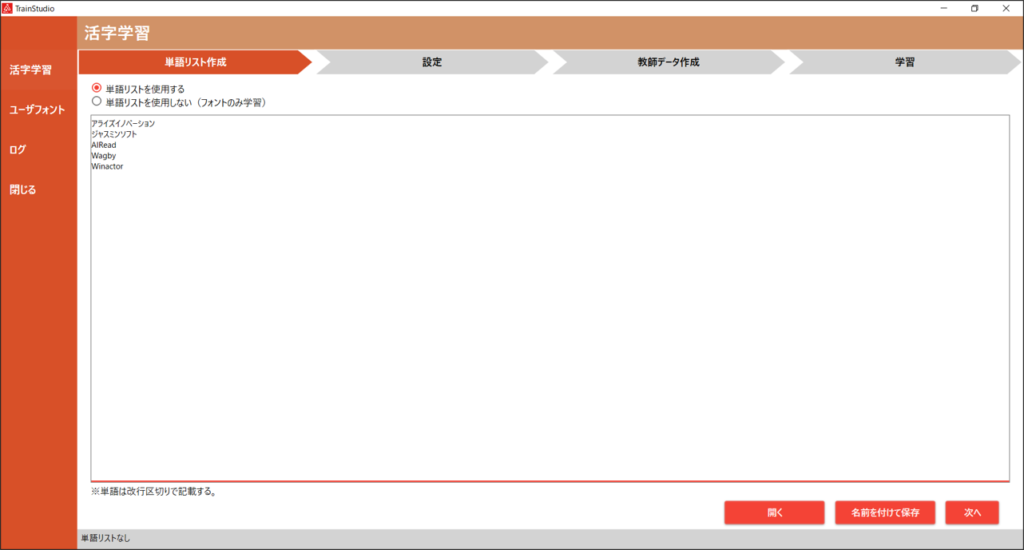
| No. | 項目名 | 説明 |
| 1 | 単語リストを使用する | 現在選択中の単語リストを使用して教師データの作成を行います。 |
| 単語リストを使用しない(フォントのみ学習) | 単語リストを使用せず、学習テキストのみで学習を行います。 ※学習テキストは、5.2. 学習時の設定 を参照 | |
| 2 | 単語リスト | 単語リストの編集が出来ます。 1行につき1単語を記載してください。 |
| 3 | 開く | 既存の単語リストファイルを読込みます。 |
| 4 | 名前を付けて保存 | 単語リスト欄の内容を、ファイルに保存します。 |
| 5 | 次へ | 設定画面に移動します。 |
5.1.1. 単語登録を行う場合
単語リストとは、登録・学習する単語の一覧を記載したテキストです。
単語登録を行う場合、「単語リストを使用する」を選択し、登録したい単語を1行に1単語ずつ記入していきます。
記入後、「次へ」ボタンを押して設定画面に進みます。
既存の単語リストを使用する場合、「開く」をクリックして使用したい単語リストを選択してください。
※単語リストは、文字コード(UTF-8)、改行コード(LF)としてください。
5.1.2. 単語登録を行わない(フォント学習のみを行う)場合
フォント学習のみを行う場合、「単語リストを使用しない(フォントのみ学習)」を選択し、「次へ」ボタンを押して設定画面へ進んでください。
5.2. 学習時の設定
設定画面で学習に必要な設定を行います。
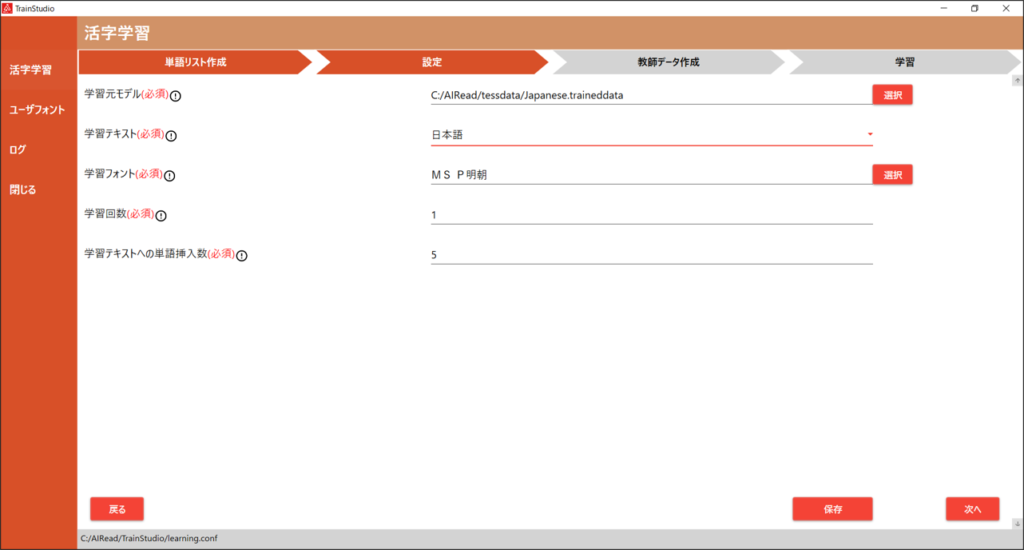
| No. | 項目名 | 説明 |
| 1 | 学習元モデル | 学習させたい活字学習モデル(拡張子”.traineddata”)のファイルを指定してください。 |
| 2 | 学習テキスト | 教師データを作成するためのテキストファイルです。 1. 学習元モデル に合わせて以下を選択してください。 Japanese.traineddata:日本語(jpn.training_text) Latin.traineddata:英語(eng.training_text) |
| 3 | 学習フォント | 教師データの作成時に使用するフォントを選択します。(複数選択可能) ※詳細は、5.2.1. 学習フォントの選択 を参照 |
| 4 | 学習回数 | 学習を行う回数を指定します。 1~5回程度を目安に指定してください。 ※回数を多くしすぎると、却って精度が下がってしまう場合がありますので、目安の回数で検証してください。 |
| 5 | 学習テキストへの単語挿入数 | 単語リストに登録した単語を教師データに挿入する回数を指定します。 ※単語リスト作成の画面で「単語リストを使用しない(フォントのみ学習)」が選択されている場合、 設定は表示されません。 |
| 6 | 戻る | 単語リスト作成画面に戻ります。 |
| 7 | 保存 | 変更した設定を保存します。 |
| 8 | 次へ | 教師データ作成画面に移動します。 |
5.2.1. 学習フォントの選択
学習フォントの選択ボタンを押すと、フォント選択画面が表示されます。
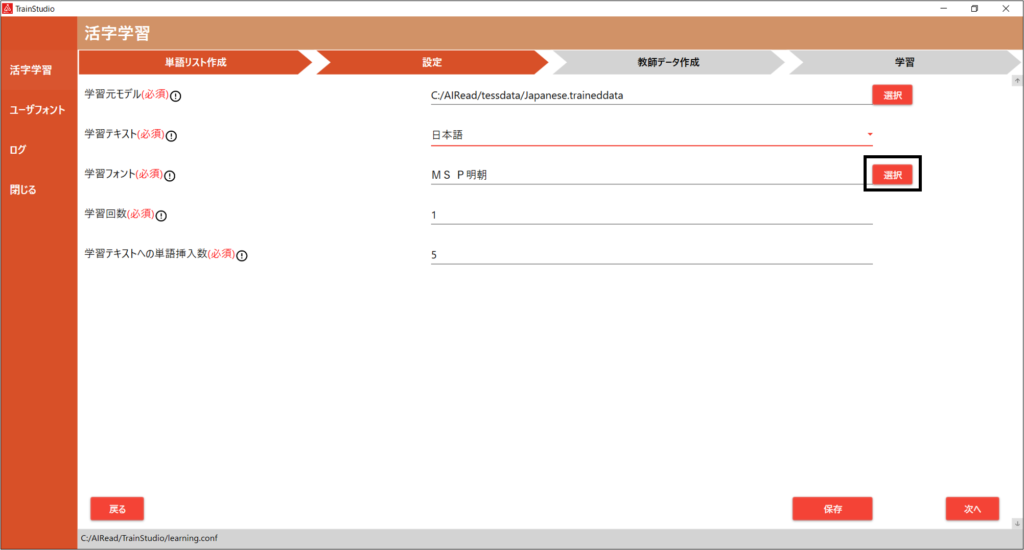
学習フォントに指定したいフォントを選択してください。(複数選択可)
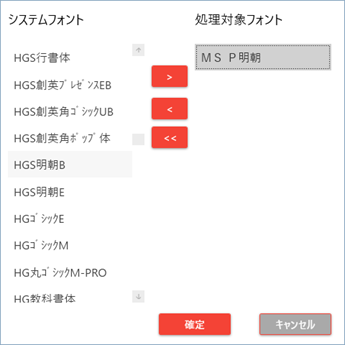
| No. | 項目名 | 説明 |
| 1 | システムフォント | 使用可能、かつ学習対象に選択していないフォント一覧が表示されます。 C:\Windows\Fonts が参照されます。 |
| 2 | 処理対象フォント | 学習フォントに選択しているフォント一覧が表示されます。 |
| 3 | > | 選択中のシステムフォントを学習フォントへ移動します。 |
| 4 | < | 選択中の学習フォントを学習対象から外します。 |
| 5 | >> | 全ての処理対象フォントを学習対象から外します。 |
| 6 | 確定 | 変更した設定を保存し、フォント選択画面を閉じます。 |
| 7 | キャンセル | 設定を保存せずに、フォント選択画面を閉じます。 |
5.3. 教師データ作成
教師データ作成画面で、選択した学習テキストと単語リストを組み合わせて教師データを作成します。
単語リスト作成の画面で「単語リストを使用する」が選択されている場合、教師データは
学習テキストに「単語リスト」の単語 × 「学習テキストへの単語挿入数」が挿入された状態で作成されます。
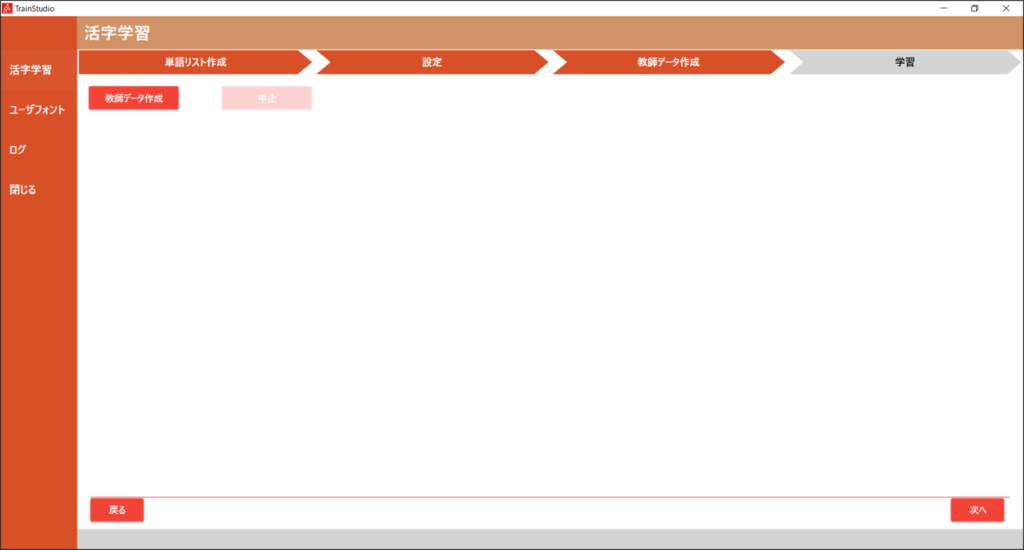
| No. | 項目名 | 説明 |
| 1 | 教師データ作成 | 単語リスト作成画面、設定画面の各種パラメータを参照して、教師データの作成を開始します。 教師データは選択した学習フォントごとに作成されます。 ユーザフォントで指定したベースフォントと選択した学習フォントが一致している場合は、教師データ作成時に ユーザフォントが使用されます。 ユーザーフォントについては、6. ユーザフォントの機能説明 を参照ください。 |
| 2 | 中止 | 教師データの作成を中断させます。 |
「教師データ作成」を押下すると、教師データの作成が行われます。
教師データ作成が成功すると、下記のダイアログが表示されます。
処理完了後、次へボタンを押して学習画面に進みます。
5.4. 学習の実行
学習画面で、教師データセットと学習後のモデルを出力するフォルダを指定し、追加学習を実行します。
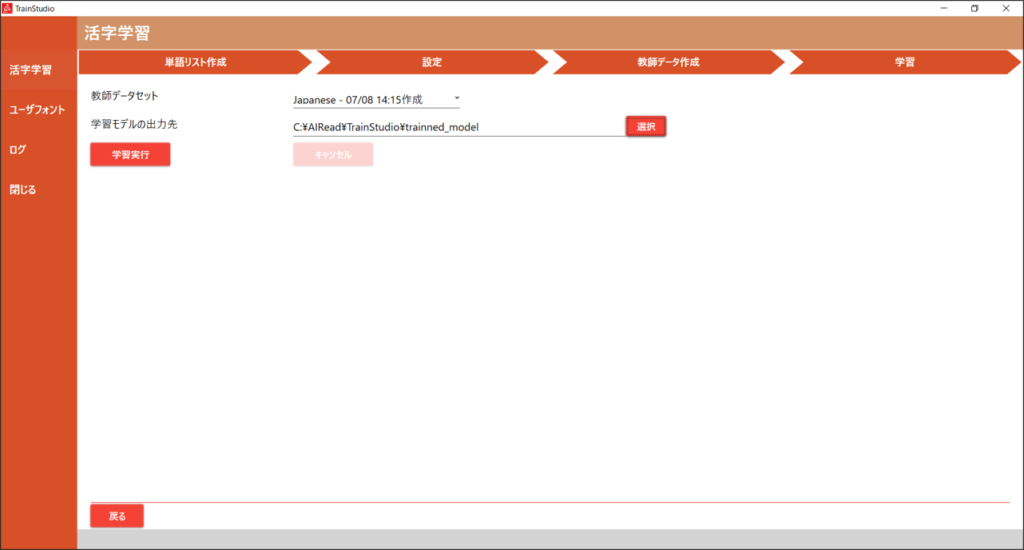
| No. | 項目名 | 説明 |
| 1 | 教師データセット | 「教師データ作成」画面で作成した教師データセットの一覧が表示されます。 追加学習実行時に使用する教師データセットを選択してください。 |
| 2 | 学習モデルの出力先 | 追加学習完了後にモデルを出力するフォルダを指定します。 ※<AIREAD_HOME>\tessdata フォルダ以外のフォルダパスを指定してください。 |
| 3 | 学習実行 | 追加学習を開始します。 |
| 4 | キャンセル | 追加学習を中断させます。 |
「学習実行」を押下すると、追加学習が開始します。
追加学習が成功すると、下記のダイアログが表示されます。
※学習中に表示されるエラーについて※
ログに下記のようなエラーが稀に表示されます。
Encoding of string failed! Failure bytes: ffffffe6 ffffff85 ffffffa8 …
Can't encode transcription: ・・・・・ in language ''
これは、使用したフォントが学習テキストの一部の文字に対応していなかった場合に表示されます。
日本語の学習回数1回につき、~20回程度の出現回数であれば学習に大きな影響はありません。
6. ユーザフォントの機能説明
実帳票をAIRead で処理することで文字画像を切り出し、これをフォント画像として使用します。
教師データを作成する際に、フォント画像を利用して教師データの作成が行われます。
実帳票から作成されたフォント画像を利用して教師データの作成を行うため、システムフォントの学習よりもより効果的な学習が行われます。
もし、フォント画像に含めていない文字種がある場合は、ベースフォント(ユーザが指定するシステムフォント)が使用されます。
ベースフォントは実帳票の文字の代わりとして学習されるため、実帳票とシステムフォントを比較して、できるだけ帳票のフォントに近いもの選択してください。
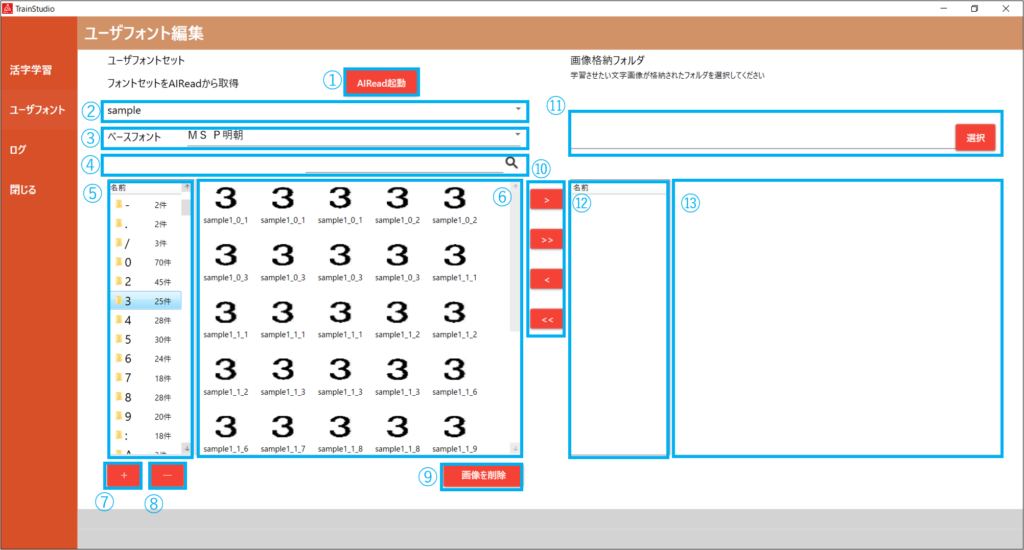
| No. | 項目名 | 説明 |
| 1 | AIRead起動 | AIReadで読み取りを実行し、ユーザフォント用の文字画像を作成します。 詳細は、6.1. AIRead起動 を参照ください。 |
| 2 | ユーザフォント | 作成済みのユーザフォントセットを選択します。 |
| 3 | ベースフォント | 選択したユーザフォントと紐づけるベースフォントを選択します。 |
| 4 | 文字種検索欄 | 選択したユーザフォントセットに含まれる文字種を検索します。 ユーザフォント文字種一覧に表示される文字種を入力した文字に絞り込んで表示します。 |
| 5 | ユーザフォント文字種一覧 | 選択したユーザフォントのフォント画像一覧が表示されます。 この一覧に含まれる文字は、教師データの作成時に学習対象となります。 |
| 6 | ユーザフォント画像一覧 | ユーザフォント文字種一覧で選択中の文字種に含まれるフォント画像が表示されます。 |
| 7 | + ボタン | ユーザフォント文字種一覧に新しい文字フォルダを追加します。 |
| 8 | - ボタン | 選択中のユーザフォント文字種をフォルダごと削除します。 |
| 9 | 画像を削除ボタン | ユーザフォント画像一覧で選択中のフォント画像を削除します。 |
| 10 | 画像移動ボタン | >:ユーザフォント画像一覧で表示中の画像の内、選択した画像を画像一覧へ移動します。 >>:ユーザフォント画像一覧で表示中の画像全てを画像一覧へ移動します。 <:画像一覧で表示中の画像の内、選択した画像をユーザフォント画像一覧へ移動します。 <<:画像一覧で表示中の画像全てをユーザフォント画像一覧へ移動します。 ※画像はドラッグアンドドロップでも移動可能 |
| 11 | 画像格納フォルダパス | 画面上に表示したい画像格納フォルダを選択してください。 |
| 12 | 画像フォルダ一覧 | 選択した画像格納フォルダに含まれるフォルダの一覧が表示されます。 |
| 13 | 画像一覧 | 画像フォルダ一覧で選択したフォルダ内の画像が表示されます。 |
6.1. AIRead起動
AIRead起動ボタンを押下し、実帳票からフォント画像を切り出すためのOCRを実行します。
非定型での読み取りを行うため、Enterprise版のライセンス登録がされている必要があります。
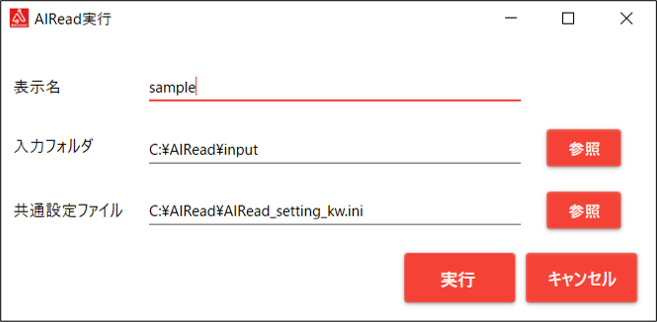
| No. | 項目名 | 説明 |
| 1 | 表示名 | 作成するユーザフォント名を任意の名称で入力してください。 |
| 2 | 入力フォルダ | フォント画像を作成したい実帳票が配置されているフォルダを選択してください。 フォルダを変更する場合は、参照ボタンから任意のフォルダを指定可能です。 |
| 3 | 共通設定ファイル | フォント画像作成のためのOCR実行時に使用される共通設定ファイルを選択してください。 ※共通設定ファイルの詳細は、 4. 共通設定 を参照ください |
| 4 | 実行ボタン | 入力フォルダ内の画像を指定した共通設定ファイルを使用して読み取ります。 その際、フォント画像の作成が行われます。 |
| 5 | キャンセルボタン | AIReadを実行せず、起動画面を閉じます。 |
6.1.1. 共通設定ファイルのパラメータ指定
フォント画像作成時に使用される共通設定ファイルの下記パラメータを手修正する必要があります。
必ず、読み取りの実行前に2種のパラメータが変更されているかご確認ください。
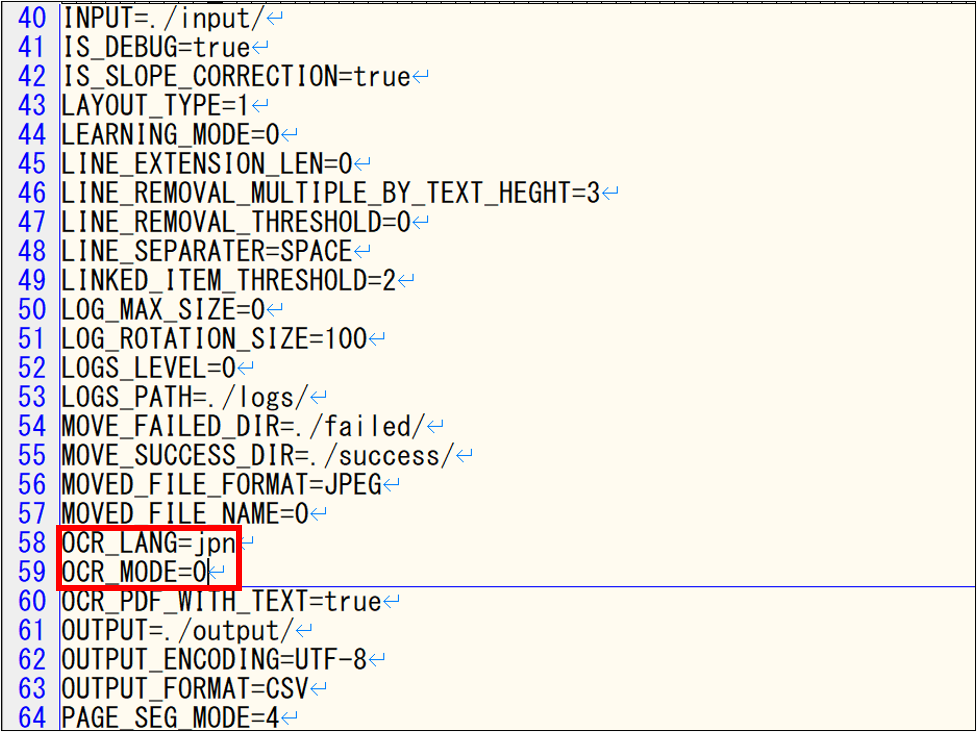
| No. | 項目名 | 設定値 | 説明 |
|---|---|---|---|
| 1 | OCR_LANG | jpn eng | 読み取り対象の帳票に合わせて選択してください。 jpn:日本語帳票を読み取る場合に選択 eng:英語帳票を読み取る場合に選択 ※日本語、英語の両方が含まれているときはjpn を選択 |
| 2 | OCR_MODE | 0 | 必ず0を入力します。 |
6.2. AIReadの実行
実行ボタンを押下すると、入力フォルダ内の画像が指定した共通設定ファイルにて読み取られます。
読み取り時に、実帳票からフォント画像の作成が行われます。
実行が完了すると、実行完了ダイアログが表示され、ユーザフォント文字種一覧に各文字種ごとのフォルダが表示されます。
フォント画像は、<AIREAD_HOME>\TrainStudio\user_letter_sets に設定した表示名で作成されます。
6.3. フォント画像のアノテーション
読み取りが完了し、作成された文字種ごとのフォルダには、AIReadが判定したフォント画像が自動で振り分けられています。
ただ、自動振り分けされたフォント画像が誤った文字種のフォルダに振り分けられていることがあります。
誤って振り分けられたフォント画像を正しい文字種のフォルダへ再振り分け(アノテーション)を行ってください。
フォント画像が誤った文字種のフォルダに振り分けられたまま学習されると、追加学習後に精度低下する原因となります。
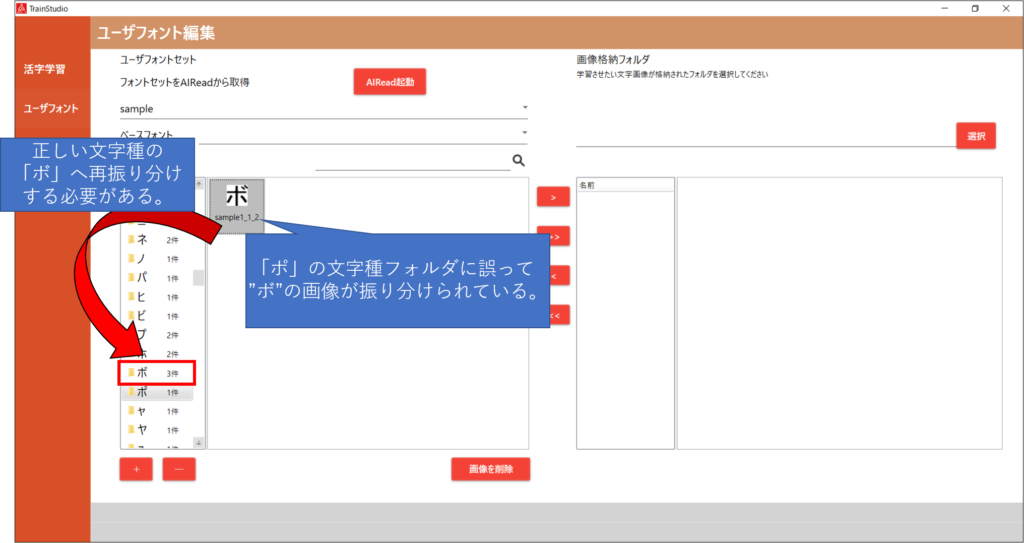
アノテーション作業を行う際は、対象のフォント画像を、正しい文字種のフォルダへドラッグアンドドロップします。
フォント画像は、複数同時に選択して移動することも可能です。
7. ログの機能説明
メニューから「ログ」を選択すると、下記の画面を表示します。
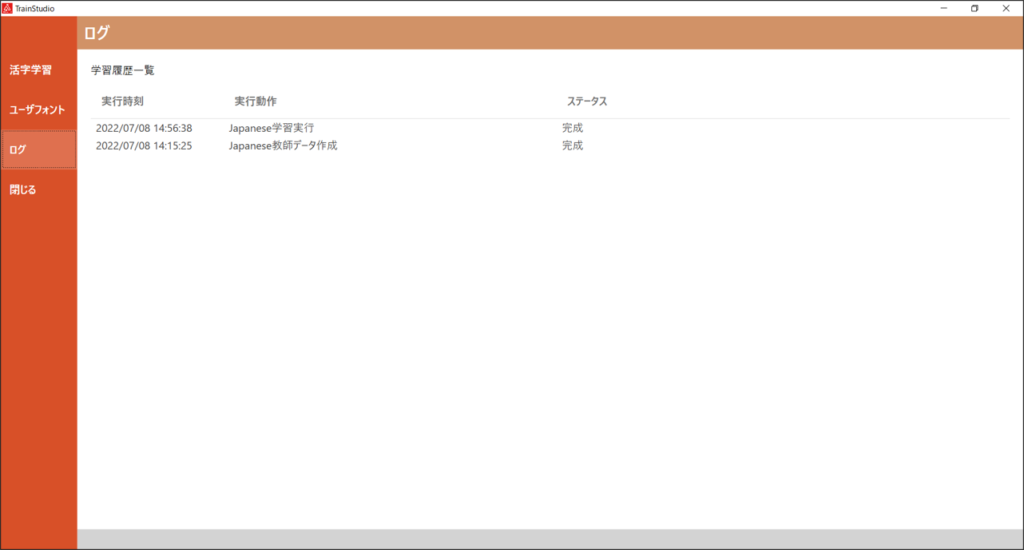
| No. | 項目名 | 説明 |
| 1 | 学習履歴一覧 | 過去の教師データ作成、および学習時のログのリストが表示されます。 リストの項目をダブルクリックすると、ログ詳細画面が表示されます。 |
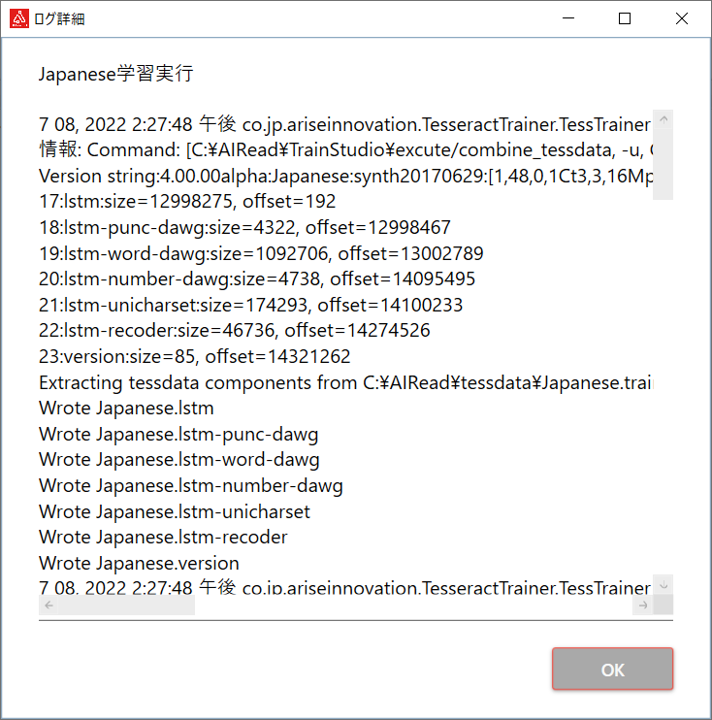
| No. | 項目名 | 説明 |
| 1 | OK | ログ詳細画面を閉じます。 |
8. 追加学習後の学習モデルの反映
追加学習の完了したモデルをAIReadで使用するには、反映作業が必要です。
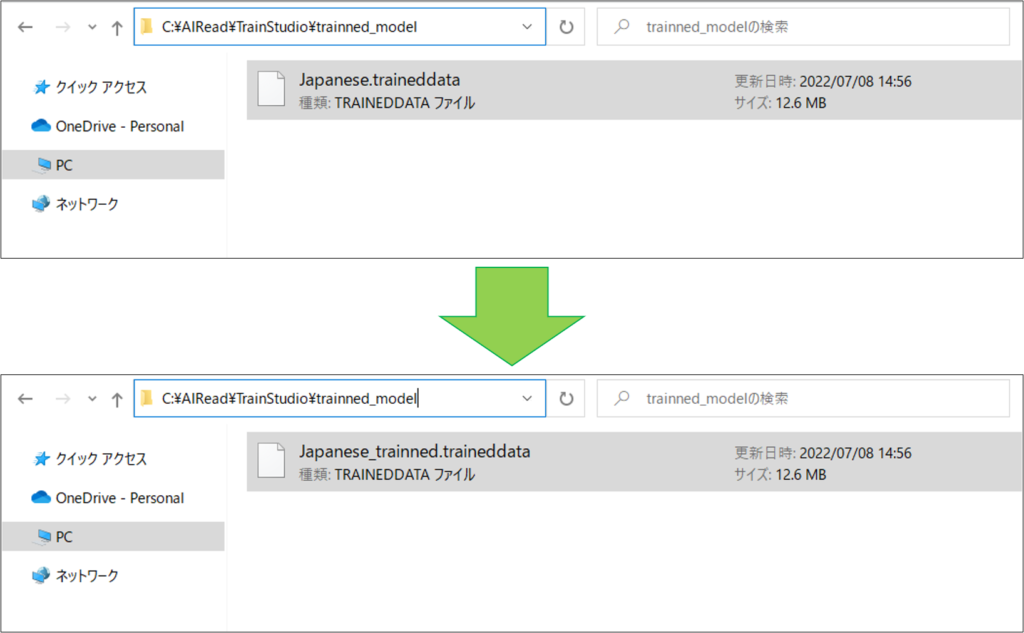
8.1. 追加学習完了後の学習モデルのリネーム
追加学習の完了した学習モデルは、学習実行時に指定した「学習モデルの出力先」に出力されています。
この学習モデルをリネームしてください。
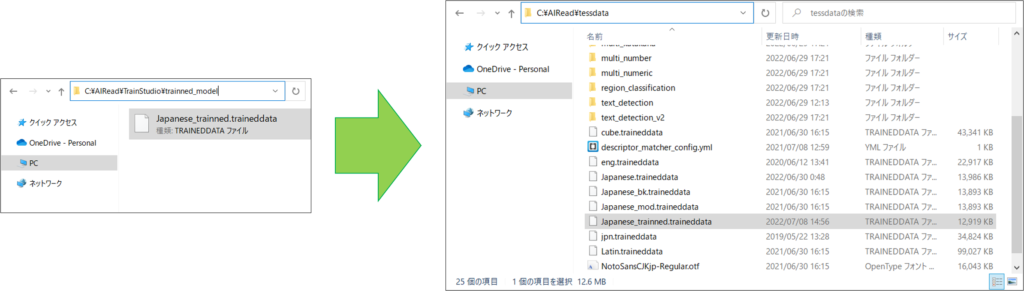
8.2. 追加学習後のモデルの配置
リネームした追加学習後の学習モデルを下記のフォルダへ配置します。
<AIREAD_HOME>/tessdata
※リネームしないまま配置すると、学習元になった追加学習前の学習モデルと競合してしまいます。
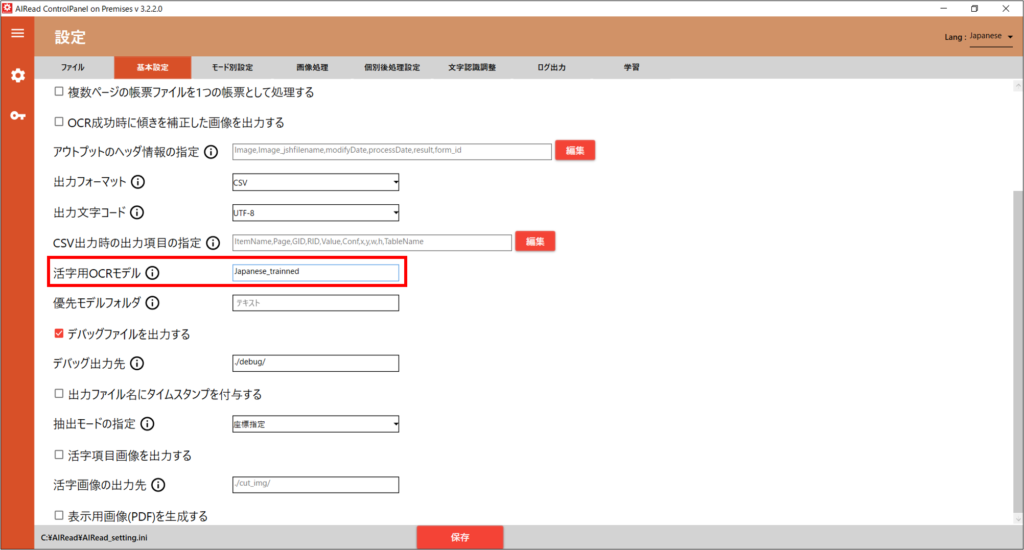
8.3. パラメータの変更
コントロールパネルを立ち上げ、基本設定タブ > 活字用OCRモデルに追加学習後の学習モデルのファイル名(拡張子.traineddataを除いたもの)を入力してください。
9. コマンドラインから実行
9.1. 各種ファイルの準備
下記のデータを準備してください。
| No. | 項目名 | 説明 |
| 1 | 学習モデル | 各言語の学習モデルです。 <AIREAD_HOME>\tessdata に配置されている拡張子”.traineddata”のファイル が対象です。 Japanese.traineddata:日本語モデル Latin.traineddata:英語モデル |
| 2 | 単語リスト | 登録・学習する単語の一覧を記載したファイルです。 作成する単語リストは、1行1単語としてください。 ※文字コードは必ずUTF-8 BOMなし |
| 3 | 学習テキスト | 教師データを作成するためのテキストファイルです。 <AIREAD_HOME>\TrainStudio\excute\train_text に配置されています。 jpn.training_text:日本語モデル学習用学習テキスト eng.training_text:英語モデル学習用学習テキスト |
| 4 | 教師データ | 単語リスト、学習テキストから作成されるファイルです。 画像ファイル(.tif)と文字の座標データ(.box)からなる教師データが作成されます。 学習テキストに記載された内容に、単語リストの単語が挿入したものがベースとなります。 ※単語リストの使用有無、挿入回数は9.2. 学習設定ファイル を参照 追加学習時には、教師データから文字の形(フォント)と単語の並びを学習します。 同じ単語でも複数回学習させることによって、その単語の認識率向上が見込めます。 |
9.2. 学習設定ファイル
学習に必要なパラメータを入力します。
“項目名=値”の書式で記載してください。
- ファイル名:<AIREAD_HOME>\TrainStudio\learning.conf
- 設定内容:
| No. | 項目名 | 設定値 | 説明 |
|---|---|---|---|
| 1 | train_mode | 1,2 | 1:単語辞書を新規作成します。 2:単語辞書に対して、追加で単語登録を行います。 ※学習モデルは内部で単語辞書を保持しています。 |
| 2 | input_file | 文字列 | 追加学習の対象モデルまでのファイルパスを入力します。 記入例:C:\AIRead\tessdata\Japanese.traineddata |
| 3 | include_text_file | 文字列 | 教師データ作成時に使用する学習テキストまでのファイルパスを入力します。 記入例:C:\AIRead\TrainStudio\excute\train_text\jpn.training_text |
| 4 | list_train_font | 文字列 | 教師データ作成時に使用する学習フォントを指定します。 セミコロン(;)で区切ることで複数の学習フォントを指定可能です。 ※フォント名は、C:\Windows\Fonts を参照ください。 <AIREAD_HOME>\TrainStudio\check_font.bat を実行すると、 renderable.txtが生成されます。 renderable.txt には、使用することのできるフォント一覧が記載されます。 記入例:MS PGothic;MS PMincho |
| 5 | list_train_size | 数値 | 教師データ作成時のテキストのフォントサイズ(pt)を指定します。 カンマで区切ることで複数のサイズを指定可能です。 ※12以上の数値を指定してください。 記入例:16,20 |
| 6 | font_style | 0 | 0 で固定です。 |
| 7 | word_list_load_size | 数値 | 教師データ作成時の単語リストの設定を変更します。 -1:単語リストを使用せず、学習テキストのみを学習する 0:単語リストに含まれるすべての単語を「word_list_load_times」で指定した回数分学習テキストにランダムに 挿入します。 1~:単語リストの先頭から指定した値分の単語を学習テキストへランダムに挿入します。 |
| 8 | word_list | 文字列 | 教師データ作成時に使用する単語リストまでのファイルパスを入力します。 記入例:C:\AIRead\TrainStudio\wordlist\test |
| 9 | word_list_load_times | 数値 | 単語リストの単語を学習テキストに挿入する回数を指定します。 記入例:5 |
| 10 | add_number | 数値 | 指定した回数分、学習テキストにランダムな数字の文字列を挿入します。 挿入される数字の並びは、1セットにつき4ケタの数字で生成されます。 記入例:0 |
| 11 | add_symbol | 数値 | 指定した回数分、学習テキストにランダムな記号の文字列を挿入します。 「hankaku_symbol」、「zenkaku_symbol」で設定された文字が学習テキストにランダムで挿入されます。 記入例:0 |
| 12 | hankaku_symbol | 半角記号 | 「add_symbol」が1以上の時、指定した半角記号がランダムに使用されます。 記入例:$%&'+,;< >?[]^`{}~¥ |
| 13 | zenkaku_symbol | 全角記号 | 「add_symbol」が1以上の時、指定した全角記号がランダムに使用されます。 記入例:”#$%&’+、;<=>?「\」^‘{}~¥ |
| 14 | add_hankaku_katakana | 数値 | 指定した回数分、学習テキストにランダムな半角カタカナの文字列を挿入します。 指定した回数分、内部で持っているカタカナの単語リストから挿入されます。 記入例:0 |
| 15 | iterations | 数値 | 指定した回数分、教師データを用いて学習を実行します。 学習回数 1回につき、全ての教師データを1通り学習します。 記入例:5 |
9.3. 実行
9.3.1. 教師データの作成
以下のコマンドを実行してください。
| > 1_text2img.bat |
- 処理内容
- 指定した設定を元に、単語リストと学習テキストから教師データ(画像(.tif)と座標情報(.box))を生成
9.3.2. 追加学習の実行
以下のコマンドを実行してください。
| > 2_train.bat |
- 処理内容
- 学習モデルへ単語登録
- 各種フォントの文字の形をモデルへ追加学習
- 追加学習後のモデルを出力
9.4. 追加学習後のモデルの反映
8. 追加学習後の学習モデルの反映 を参照ください。
10. 制約事項
- それぞれの学習モデルに対応した文字のみ追加学習可能です。
- 学習テキストは1行ずつ学習します。学習モデルに対応していない文字が含まれている行はスキップするため学習されません。
- 「list_train_size」は12以上で設定してください。11以下を設定するとエラーとなり学習されません。
11. TrainStudioのバックアップ
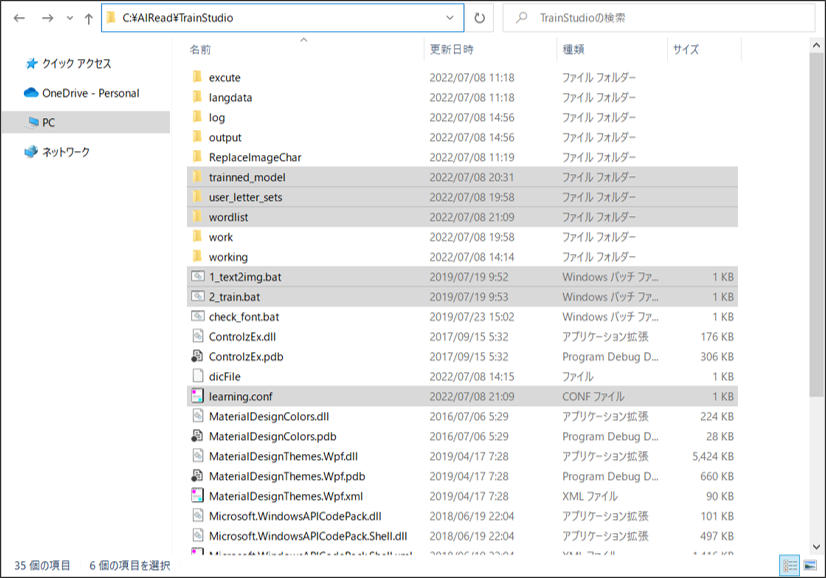
TrainStudioの環境移行・アンインストールを行う前に、単語リスト、学習設定、追加学習後のモデル等、必ずバックアップを行ってください。
下記は必ずバックアップを行います。
- user_letter_sets:ユーザーフォントが配置されているフォルダ
- wordlist:単語リスト
- learning.conf:学習設定
- trainned_model(フォルダ名任意):追加学習後のモデルが配置されているフォルダ
※学習完了後の学習モデルや、テストデータは個別にバックアップを取った上で、ユーザー様自身で移行を行ってください。
bat ファイルのコマンドを変更している場合は、batファイルのバックアップ、移行も行ってください。
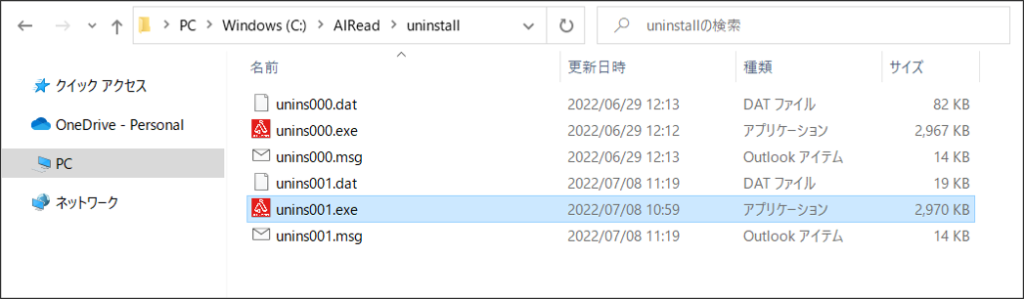
12. アンインストール
<AIREAD_HOME>\uninstall に自動生成されるunins001.exeを実行します。