7. 帳票設定管理画面
帳票定義のグループごとに紐づける帳票設定の作成・編集を行う画面です。
作成した設定は、定義グループへ紐づける必要があります。設定の紐づけは、6.1. 帳票設定の指定 を参照ください。
本画面で作成・修正できる設定は、帳票定義管理画面上の定義グループ単位のデフォルト設定のみです。
個別設定を追加・修正する場合は、CloudClientから再度アップロードを行ってください。
管理者ユーザでのみ表示される画面です。一般ユーザの画面には表示されません。
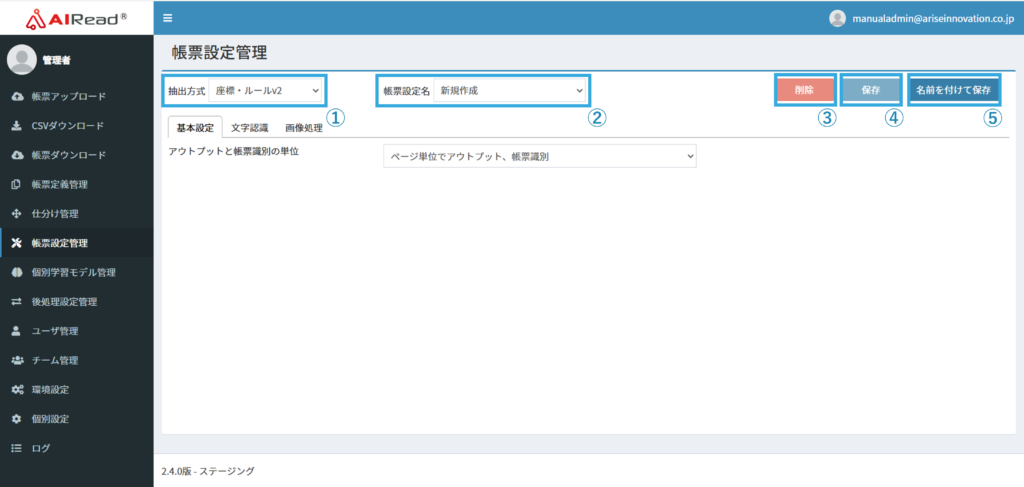
| No. | 機能名 | 説明 |
| 1 | 抽出方式 | 抽出方式を選択します。 |
| 2 | 帳票設定名 | 新規作成、または作成済みの帳票設定を選択します。 選択した帳票設定を編集できます。 |
| 3 | 削除 | 選択した帳票設定を削除します。 |
| 4 | 保存 | 選択した帳票設定のパラメータを最新の状態に保存します。 |
| 5 | 名前を付けて保存 | 変更したパラメータを名前を付けて新規保存します。 |
7.1. 抽出方式:座標・ルールv2
7.1.1 基本設定
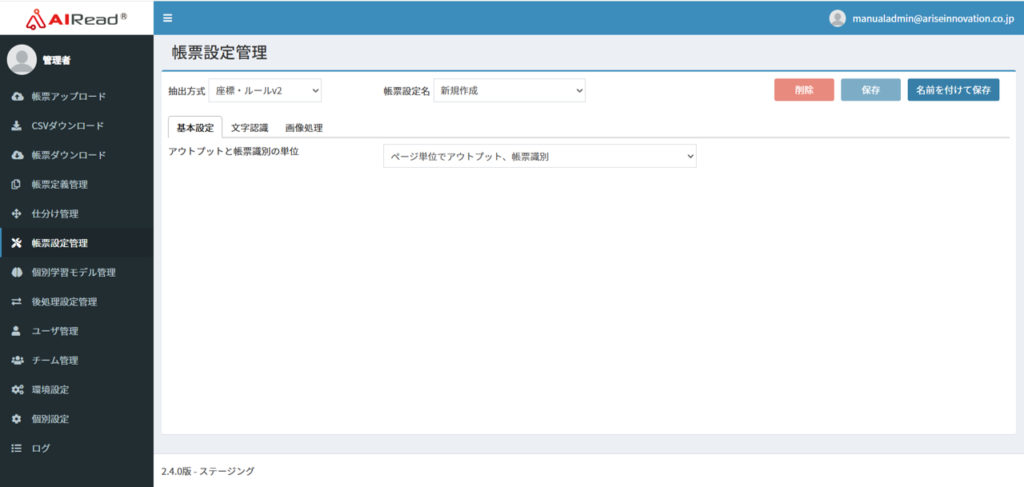
| No. | 項目名 | 説明 |
|---|---|---|
| 1 | アウトプットと帳票仕分けの単位 | 帳票を仕分け、読み取りする単位を指定する ・ページ単位でアウトプット、帳票識別:ページ単位で帳票を識別し、ページ単位で処理する ・ファイル単位でアウトプット、帳票識別は1ページ目のみ:1ページ目で帳票を識別し、1ファイルすべてのページを1つの帳票として処理する |
7.1.2. 文字認識
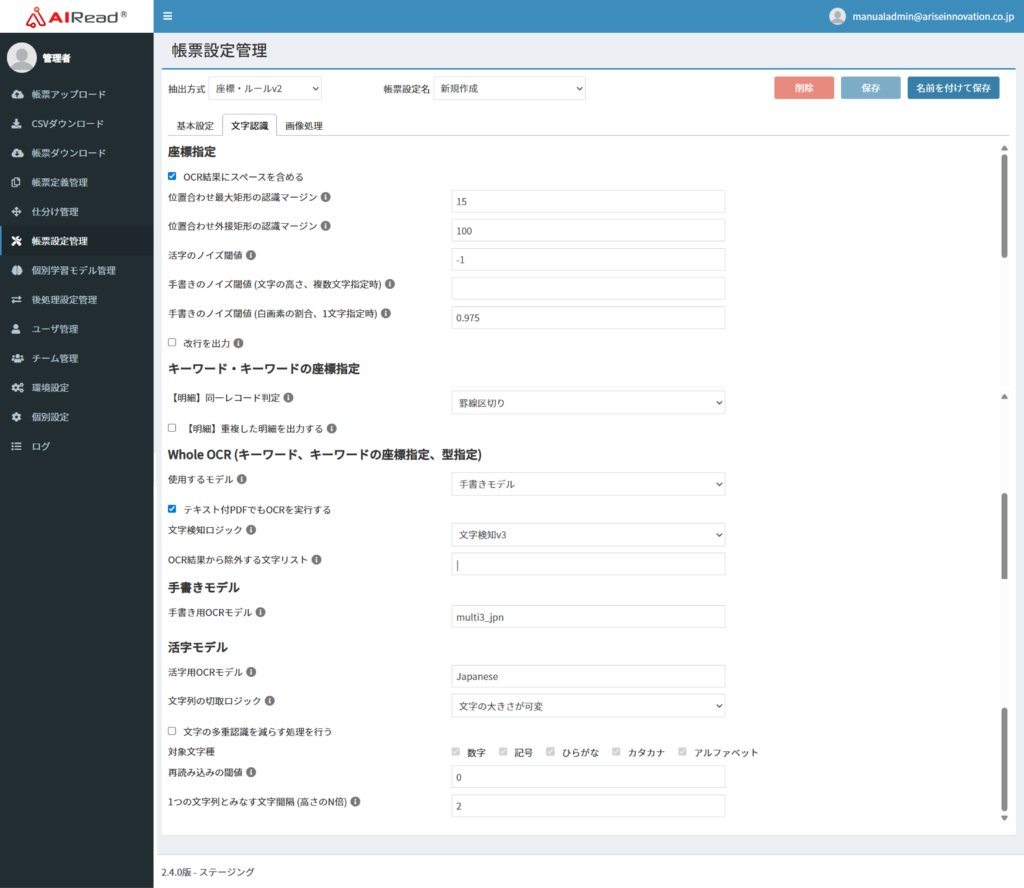
| No. | 項目名 | 書式 | 説明 |
|---|---|---|---|
| 座標指定 | |||
| 1 | OCR結果にスペースを含める | チェックボックス | チェック(有効)の時、OCR結果にスペースを含める (活字読み取り時のみ) |
| 2 | 位置合わせ最大矩形の認識マージン | 0以上 | 位置合わせ時に大きな矩形を認識しない画像端(上下左右)からの範囲を指定する 単位はピクセル (デフォルト 15) |
| 3 | 位置合わせ外接矩形の認識マージン | 0以上 | 位置合わせ時に外接矩形を認識しない画像端(上下左右)からの範囲を指定する 単位はピクセル (デフォルト 100) |
| 4 | 活字のノイズ閾値 | -1~100 | 活字の認識で、項目中の最大文字高さに対して指定された閾値以下の文字をノイズとして除去する 例) 30 を指定 → 読み取り範囲内の最大文字に対し30%以下の高さの文字をノイズとみなして除去する (デフォルト -1:本機能は動作しない) ※小さい文字や記号がノイズとして削除される可能性有り |
| 5 | 手書きノイズの閾値 (文字の高さ、複数文字指定時) | 文字列 | 手書き文字の認識で指定したモデルについて、項目中の最大文字高さに対して任意の割合以下の文字をノイズとして除去する 手書き文字の文字数を「複数」で設定した項目を対象とする [モデル名]:[閾値(%)]の形式で記載する カンマ区切りで複数指定可能 例) number:25,money:30 → 数値モデルは25%、通貨モデルは30%の高さの文字をノイズとみなして除去する ※小さい文字や記号がノイズとして削除される可能性があります |
| 6 | 手書きノイズの閾値 (白画素の割合、1文字指定時) | 0~1.0 | 手書き項目に1文字指定をしているとき、 その項目画像を読取対象外(ノイズ)と判断する白ピクセルの割合と判断する閾値を指定する 例) 0.99 を指定 → 手書き項目が1文字指定のとき、項目内の白ピクセルの割合が99%以上であれば、項目内の記載をノイズと判断して除去する (デフォルト 0.975) |
| 7 | 改行を出力 | チェックボックス | チェック(有効)の時、読み取り項目内の改行を認識して\nとして出力する |
| キーワード、キーワードの座標指定 | |||
| 8 | 【明細】同一レコード判定 | リストボックス | 同一レコードとみなす判定ロジックを選択。 ・罫線区切り:罫線をまたいだ場合にレコードを区切る ・行区切り:横に並んでいる文字列を1行としてレコードを区切る |
| 9 | 【明細】重複した明細を出力する | チェックボックス | チェック(有効)の時、重複した明細を出力する 同一キーワードの明細が横に並んでいる場合に有効にする |
| Whole OCR(キーワード、キーワードの座標指定、型指定) | |||
| 10 | 使用するモデル | リストボックス | 全文OCRで使用するモデルを指定する ・手書きモデル ・活字モデル |
| 11 | テキスト付きPDFでもOCRを実行する | チェックボックス | チェックあり(有効):テキスト付きPDFの場合でもOCRを実行する チェックなし(無効):PDFのテキスト情報を使用して抽出する |
| 12 | 文字検知ロジック | リストボックス | 文字列検知ロジックを指定する ・文字検知v3:text_detection_v3を使用 ・文字検知v2:text_detectionモデルを使用 ・文字検知v1:tesseractを使用 |
| 13 | OCR結果から除外する文字リスト | 文字列 | 抽出処理時にキーワードおよび抽出する値から除外する文字を指定する |
| 手書きモデル | |||
| 14 | 手書き用OCRモデル | 文字列 | 指定された手書きモデルが存在しないときに使用するモデル名 "OCR_MODEL_PATH/tessdata/"以下に存在するフォルダ名 例)multi3_jpn |
| 活字モデル | |||
| 15 | 活字用OCRモデル | 文字列 | 活字OCRエンジンで利用するモデル名 OCRモデルフォルダに存在するファイルの拡張子”.traineddata”を除外したファイル名を指定する 例)Japanese.traineddata → Japanese |
| 16 | 文字列の切取ロジック | リストボックス | OCRエンジンの文字識別アルゴリズムを指定する ・文字の大きさが可変 ・文字の大きさが均一 |
| 17 | 文字の多重認識を減らす処理を行う | チェックボックス | 複数の同じ文字が連続で出力されてしまうとき、本設定をチェック(有効)にすることで回避できる(活字のみ) ※文字間が近い場合、複数文字を1文字として出力してしまう副作用が起きる可能性がある |
| 18 | 対象文字種 | チェックボックス | 「文字の多重認識を減らす処理を行う」の対象となる文字種を指定する(複数指定可能) ・ 数字 ・ 記号 ・ひらがな ・カタカナ ・アルファベット |
| 19 | 再読み込みの閾値 | 0~100 | 指定した値よりもコンポーネントのConf値が閾値より低い場合に読み直す(活字のみ) ※コンポーネント内の文字のConf値の平均値 |
| 20 | 1つの文字列とみなす文字間隔(高さのN倍) | 数値 | 1つの文字列とみなす文字の間隔を設定 値は文字の高さに対する倍率 |
7.1.3. 画像処理
| No. | 項目名 | 書式 | 説明 |
|---|---|---|---|
| 1 | 傾き補正を行う | チェックボックス | チェック(有効)の時、文字認識前に傾き補正を行う(35度まで) |
| 2 | 回転補正を行う | チェックボックス | チェック(有効)の時、文字認識前に90/180/270度の画像回転補正を行う |
| 3 | 回転補正のロジック | リストボックス | 回転補正のロジックを指定 回転補正v1:画像処理を使用した回転補正 回転補正v2:DeepLearningを使用した回転補正、v1より精度が良いが、処理時間が数秒長くなる |
| 4 | 直線除去を行う最短の長さ | 0以上の整数 | 直線とみなす長さのしきい値(ピクセル) 0の場合、文字の大きさから自動で設定する |
| 5 | 直線除去時の文字高さに対する倍率 | 0.1以上の数値 | 指定した値×文字高さの平均(ピクセル)が直線除去の対象となる 直線除去を行う最短の長さ の値が0の場合にのみ動作する |
| 6 | 点線除去を行う最短の長さ | 0以上の整数 | 点線とみなす長さの閾値(ピクセル) |
| 7 | 点線の間隔(横) | 0以上の整数 | 横の点線として検知する点の間隔の値(ピクセル) 点と点の間隔が広い場合は大きい値を設定する (デフォルト 12) |
| 8 | 点線の間隔(縦) | 0以上の整数 | 縦の点線として検知する点の間隔の値(ピクセル) 点と点の間隔が広い場合は大きい値を設定する (デフォルト 7) |
| 9 | 罫線除去で欠けてしまった文字の復元処理を行う | チェックボックス | チェック(有効)の時、罫線除去時に欠けてしまう罫線と隣接した文字を復元する ※必ず復元できるわけではない ※副作用として文字にノイズがつく場合がある |
| 10 | 二値化の閾値 | 0~255 | 文字認識前の画像の二値化(白黒化)の閾値 0の場合、画像全体のヒストグラムから自動で設定する 詳細は3.8.1. 二値化の閾値を参照 |
| 11 | 直線除去時の二値化の閾値 | 0~255 | 直線除去時の二値化パラメータの閾値 0の場合、画像全体のヒストグラムから自動で設定する |
| 12 | 短い罫線(横)除去の閾値 | -1以上 | 長い罫線に接している短い罫線(横)を検知・除去する閾値 罫線の長さ(ピクセル)を指定する -1 : 除去を行わない 0 : 除去を行わない(-1と同じ) 1以上 : この値を直線検知の閾値とする |
| 13 | 短い罫線(縦)除去の閾値 | -1以上 | 長い罫線に接している短い罫線(縦)を検知・除去する閾値 罫線の長さ(ピクセル)を指定する -1 : 除去を行わない 0 : 除去を行わない(-1と同じ) 1以上 : この値を直線検知の閾値とする |
| 14 | 短い点線も除去する | チェックボックス | チェック(有効)の時、短い罫線除去時に点線も除去対象とする ※処理時間がA4画像1枚当たり2秒ほど増加する ※文字が除去される副作用が発生する可能性がある |
| 15 | 細かいノイズ除去の閾値(幅) | 0以上 | 指定した幅(ピクセル)より細かいノイズを除去する 値が大きいほど大きなサイズのノイズを除去する (デフォルト 3) 詳細は3.8.2. 細かいノイズ除去を参照 |
| 16 | 細かいノイズ除去の閾値(高さ) | 0以上 | 指定した高さ(ピクセル)より細かいノイズを除去する 値が大きいほど大きなサイズのノイズを除去する (デフォルト 3) 詳細は3.8.2. 細かいノイズ除去を参照 |
| 17 | 細かいノイズ除去の縮小フィルタ(幅) | 1以上 | 細かいノイズ除去の収縮処理のフィルターサイズ(幅) 値が大きいとより独立したノイズのみ除去する (デフォルト 12) 詳細は3.8.2. 細かいノイズ除去を参照 |
| 18 | 細かいノイズ除去の縮小フィルタ(高さ) | 1以上 | 細かいノイズ除去の収縮処理のフィルターサイズ(高さ) 値が大きいとより独立したノイズのみ除去する (デフォルト 7) 詳細は3.8.2. 細かいノイズ除去を参照 |
| 19 | TIFFを300DPIに変換してからOCRを実行する | チェックボックス | チェック(有効)の時、TIFFを300DPIに変換してからOCRを実行する TIFFで縦横のDPIが異なる場合に指定する |
| 20 | 抽出する色 | チェックボックス、文字列 | 抽出する色を指定する(指定した色以外を除去する) 個別で指定する場合は、カスタムで直接数値を指定 詳細は3.8.5.3. 色の指定方法(テキスト)を参照 |
| 21 | 除去する色 | チェックボックス、文字列 | 除去する色を指定する 指定方法は抽出する色と同様 抽出する色と両方指定した場合は抽出を優先する 詳細は3.8.5.3. 色の指定方法(テキスト)を参照 |
| 22 | 色抽出・除去を罫線除去の前に行う | チェックボックス | チェック(有効)の時、罫線除去の前に色抽出・除去を行う |
| 23 | 罫線を延長する長さ | 0以上 | 検知した罫線を延長する 単位はピクセル (デフォルト 0) |
| 24 | 矩形の丸い角を除去する閾値 | 0~100 | 半径が指定した値未満の丸い角を除去する 単位はピクセル 0の場合は除去されない (デフォルト 30) 詳細は3.8.3. 丸い角の除去を参照 |
| 25 | 丸い角の除去範囲を拡張する長さ | 0~100 | 丸い角を除去する際に、指定した値分の除去範囲を拡大する 単位はピクセル (デフォルト 10) 詳細は3.8.3. 丸い角の除去を参照 |
| 26 | ドットの除去(背景・点線)を行う | チェックボックス | チェック(有効)の時、ドットの除去(背景、点線)を行う |
| 27 | 除去したいドットの幅 | 0以上の整数 | 削除したい背景や点線のドットのサイズの幅をピクセルで指定する (デフォルト 3) |
| 28 | 除去したいドットの高さ | 0以上の整数 | 削除したい背景や点線のドットのサイズの高さをピクセルで指定する (デフォルト 3) |
| 29 | 罫線/点線削除の前にドットを削除 | チェックボックス | チェック(有効)の時、罫線/点線削除の前にドットを削除する |
| 30 | 小さい矩形を削除 | チェックボックス | チェック(有効)の時、小さい矩形の除去を行う |
| 31 | 除去する小さい矩形の最小面積 | 0以上の整数 | 「小さい矩形を削除除去する」がチェック(有効)の時に除去する矩形の最小面積を指定する |
| 32 | 除去する小さい矩形の最大面積 | 0以上の整数 | 「小さい矩形を削除除去する」がチェック(有効)の時に除去する矩形の最大面積を指定する |
| 33 | 斜め線を除去 | チェックボックス | チェック(有効)の時、矩形内の斜めの線を除去する |
| 34 | ノイズ除去を行う | チェックボックス | チェック(有効)の時、ノイズ除去を行う |
| 35 | 罫線除去を無効化する | チェックボックス | チェック(有効)の時、罫線除去を無効化する 罫線除去が無効化されている場合、罫線もOCR対象となる |
| 36 | 白黒反転処理を実施する黒の比率(%) | 0~100 | 二値化後に白黒を反転する閾値(%) 設定した%より黒の割合が多い場合に白黒を反転 |
| 37 | シャープ補正値 | 0以上の少数 | OCR実行前に画像をシャープ化する 画像がぼやけている場合に効果がある 0の場合は処理しない 使用する場合、0.2~0.7が目安 |
| 38 | ドット背景除去を行う (旧) | チェックボックス | チェック(有効)の時、ドットの背景除去を行う ※下位互換パラメータ |
| 39 | ドットサイズ | 0以上の整数 | 「ドット背景除去を行う」が有効であるとき、ドット背景除去時に削除するドットのサイズ(ピクセル)を指定する 指定した値よりも縦横の大きさが小さいものが削除対象 |
7.2. 抽出方式:ルール指定
7.2.1 基本設定
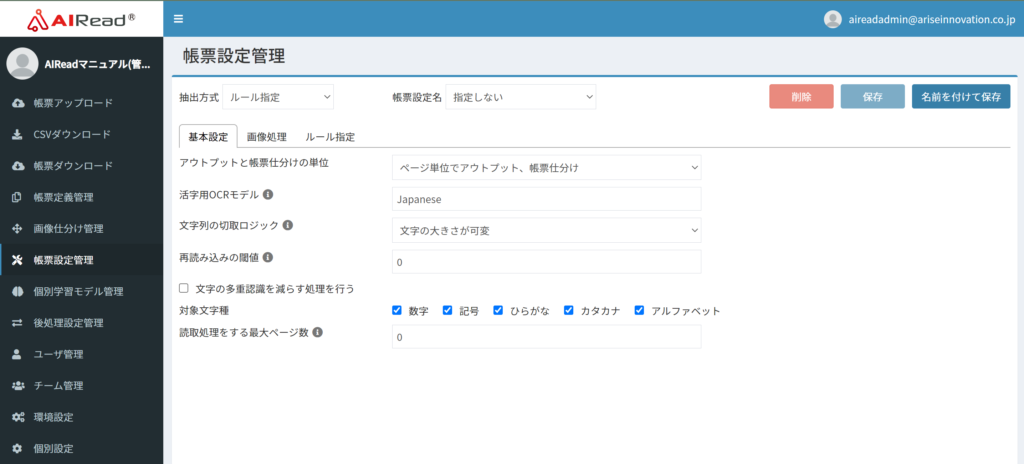
| No. | 項目名 | 説明 |
|---|---|---|
| 1 | アウトプットと帳票仕分けの単位 | 帳票を仕分け、読み取りする単位を指定します。 ページ単位でアウトプット、帳票識別:ページ単位で帳票を識別し、ページ単位で処理する ファイル単位でアウトプット、帳票識別は1ページ目のみ:1ページ目で帳票を識別し、1ファイルすべてのページを1つの帳票として処理する |
| 2 | 活字用OCRモデル | 活字の文字に対してOCRを行う時のモデル名を指定します。 デフォルトで使用可能 Japanese:ひらがな・カタカナ・漢字・アルファベット・数字・記号に対応 Latin:アルファベット・数字・記号に対応 Japanese_mod:Japaneseの対応文字種に加え、「㈱」「㈲」「〃」の環境依存文字に対応 個別学習モデルにアップロードした活字モデルを使用する場合、入力フィールドにモデル名を指定します。 |
| 3 | 文字列の切取ロジック | OCRエンジンの活字文字検知/分割アルゴリズムを指定します。 文字の大きさが可変:1行内の文字サイズが可変とみなして文字を検知 文字の大きさが均一:1行内の文字サイズが固定とみなして文字を検知 ※「抽出モードの指定」がキーワード指定(表検出付き)の場合は、文字の大きさが均一 を指定してください。 |
| 4 | 再読み込みの閾値 | 指定した値よりも読み取った文字の信頼値が低い場合に読み直しを行います。 |
| 5 | 文字の多重認識を減らす処理を行う | 複数の同じ文字が連続で出力されてしまうとき、本設定を有効にすることで回避できます。 ※本設定は活字にのみ対応です。 文字同士の距離が近い場合、複数の文字を1文字として認識してしまう副作用を起こす可能性があります。 チェックあり:機能を有効にする チェックなし:機能を無効にする |
| 6 | 対象文字種 | 「文字の多重認識を減らす処理を行う」が有効な時に、対象文字種を限定できます。 数字:数字のみを対象とする 記号:記号のみを対象とする ひらがな:ひらがなのみを対象とする カタカナ:カタカナのみを対象とする アルファベット:アルファベットのみを対象とする |
| 7 | 読取処理をする最大ページ数 | 読取処理をする最大ページ数を指定します。 例)1を指定した場合、2ページ目以降は無視する 0を指定した場合は全ページが読み取り対象となります。 ※「アウトプットと帳票仕分けの単位」が「ファイル単位でアウトプット、帳票識別は1ページ目のみ」の場合のみ有効です。 「ページ単位でアウトプット、帳票識別」の場合はすべてのページを読み取ります。 |
7.2.2. 画像処理
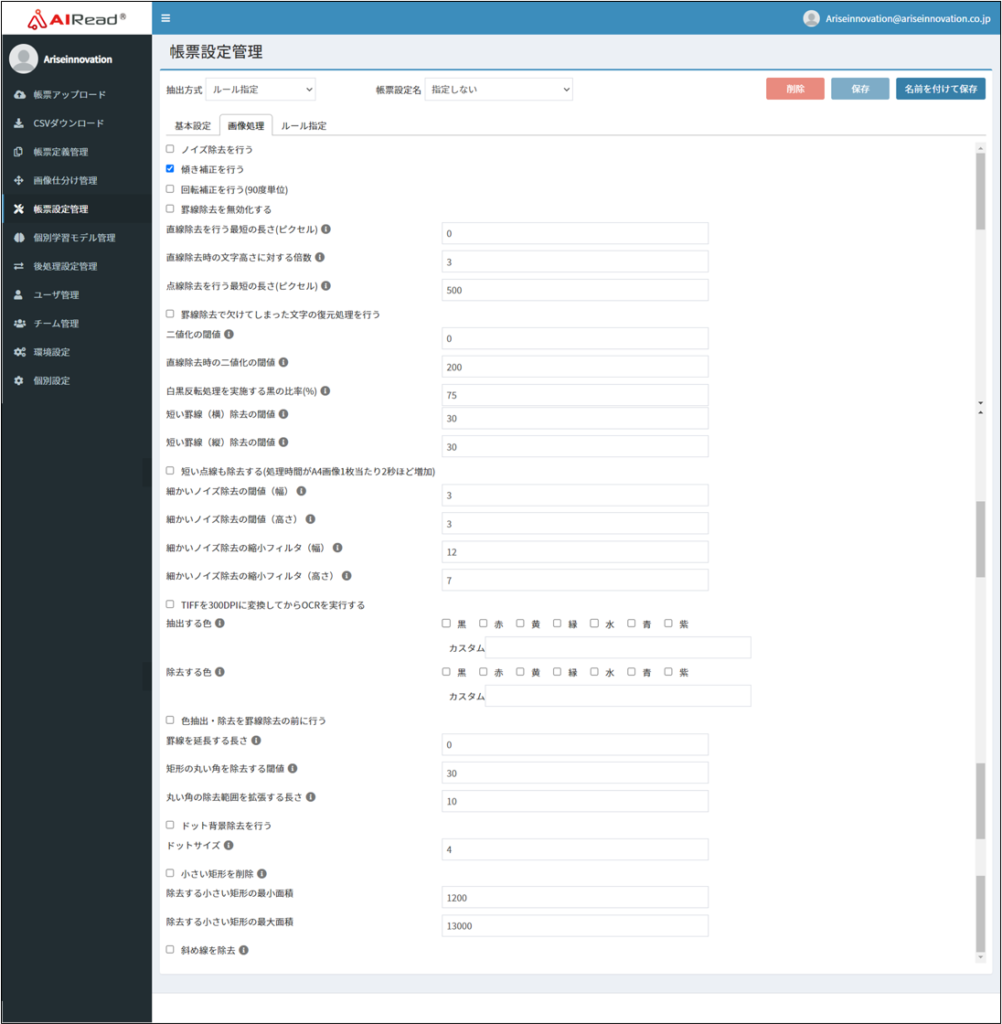
| No. | 項目名 | 説明 |
| 1 | ノイズ除去を行う | ノイズ除去処理の有無を設定します。 ※ごみ除去ではありません。 チェックあり:文字認識前にノイズ除去を行う チェックなし:ノイズ除去を行ずに処理を行う |
| 2 | 傾き補正を行う | 傾き補正を行います。最大約35度までの傾きに対応が可能です。 チェックあり:文字認識前に傾き補正を行う チェックなし:傾き補正を行わずに処理を行う |
| 3 | 回転補正を行う(90度単位) | 回転補正を行います。90度単位で補正が可能です。 チェックあり:文字認識前に90/180/270度の画像回転補正を行う チェックなし:回転補正を行わずに処理を行う |
| 4 | 罫線除去を無効化する | 罫線除去を無効化します。罫線除去が無効化されている場合、罫線もOCR対象となります。 チェックあり:文字認識前の罫線除去を無効化する(罫線除去は行わない) チェックなし:文字認識前の罫線除去を行う(罫線除去を行う) |
| 5 | 直線除去を行う最短の長さ(ピクセル) | 直線とみなす長さのしきい値をピクセルで指定します。 指定した値よりも長い直線が除去対象となります。 0の場合、画像全体の文字高さ平均から自動で設定されます。 200が指定されている場合は、200ピクセルよりも長い直線が除去対象となります。 |
| 6 | 直線除去時の文字高さに対する倍率 | 指定した値×文字高さの平均(ピクセル)が直線除去の対象となります。 直線除去を行う最短の長さ の値が0の場合にのみ動作します。 |
| 7 | 点線除去を行う最短の長さ(ピクセル) | 点線とみなす長さのしきい値をピクセルで指定します。 指定した値よりも長い点線が除去対象となります。 0の場合、画像全体の文字高さ平均から自動で設定されます。 500が指定されている場合は、200ピクセルよりも長い点線が除去対象となります。 |
| 8 | 罫線除去で欠けてしまった文字の復元処理を行う | 罫線除去時に罫線と隣接と文字が隣接している場合や罫線と文字が被っている場合に欠けてしまった文字を復元します。 チェックあり:欠けた文字の復元を行う チェックなし:欠けた文字の復元は行わない ※欠けた文字は必ず復元できるわけではありません。 副作用として文字にノイズがつく場合があります。 |
| 9 | 二値化の閾値 | 文字認識前の画像の二値化(白黒化)パラメータの閾値を設定します。 0の場合、画像全体のヒストグラムから自動で閾値の反映が行われます。 |
| 10 | 直線除去時の二値化の閾値 | 直線除去時の二値化パラメータの閾値を設定します。 0の場合、画像全体のヒストグラムから自動で閾値の反映が行われます。 |
| 11 | 白黒反転処理を実施する黒の比率(%) | 二値化後に白黒を反転する閾値の割合を設定します。 設定した%より黒の割合が多い場合に白黒を反転する処理を行います。 |
| 12 | シャープ補正値 | OCR実行前に画像をシャープ化する処理を行います。 画像がぼやけている場合などに利用するとシャープ補正の効果が得られます。 値が0の場合はシャープ補正の処理は行われません。 |
| 13 | 短い罫線(横)除去の閾値 | 長い罫線に接している短い罫線(横)を検知・除去する閾値を設定します。 「直線除去を行う最短の長さ(ピクセル)」で除去される直線に両端が隣接している罫線のみ対象となります。 |
| 14 | 短い罫線(縦)除去の閾値 | 長い罫線に接している短い罫線(縦)を検知・除去する閾値を設定します。 「直線除去を行う最短の長さ(ピクセル)」で除去される直線に両端が隣接している罫線のみ対象となります。 |
| 15 | 短い点線も除去する(理時間がA4画像1枚当たり2秒ほど増加) | 短い罫線除去を行う時に、短い点線も除去対象とします。 チェックあり:短い点線も除去対象とする チェックなし:短い点線は除去しない ※本機能が有効な場合、処理時間がA4画像1枚当たり2秒ほど増加します。 また、文字の一部が除去される副作用が発生する可能性もあります。 |
| 16 | 細かいノイズ除去の閾値(幅) | 指定した幅(ピクセル)より細かいノイズを除去します。 値が大きいほど大きなサイズのノイズを除去します。 |
| 17 | 細かいノイズ除去の閾値(高さ) | 指定した高さ(ピクセル)より細かいノイズを除去します。 値が大きいほど大きなサイズのノイズを除去します。 |
| 18 | 細かいノイズ除去の縮小フィルタ(幅) | 細かいノイズ除去の収縮処理のフィルターサイズ(幅)を指定します。 値が大きいとより独立したノイズのみを除去するようになります。 |
| 19 | 細かいノイズ除去の縮小フィルタ(高さ) | 細かいノイズ除去の収縮処理のフィルターサイズ(高さ)を指定します。 値が大きいとより独立したノイズのみを除去するようになります。 |
| 20 | TIFFを300DPIに変換してからOCRを実行する | TIFF画像が読み取り対象の時に、300DPIに変換してからOCRを実行します。 縦横のDPIの異なるTIFF画像が対象の場合に指定します。 チェックあり:TIFF画像を300DPIで変換する チェックなし:TIFF画像の変換は行わない |
| 21 | 抽出する色 | 抽出する色を指定します。指定した色以外は除去されます。 個別でカスタム色を指定する場合は、直接数値を入力してください。 |
| 22 | 除去する色 | 除去する色を指定します。 指定方法は「抽出する色」の指定方法と同様です。 ※抽出する色と除去する色の両方を指定した場合、抽出する色が優先されます。 |
| 23 | 色抽出・除去を罫線除去の前に行う | 罫線除去の処理の前に、色抽出・除去を行います。 通常は罫線除去 → 色抽出・除去 → OCR の処理順ですが、本機能が有効になっている場合、色抽出・除去 → 罫線除去 → OCR の順で処理を行います。 チェックあり:色抽出・除去を罫線除去よりも先に行う チェックなし:従来通りの順番で処理を行う |
| 24 | 罫線を延長する長さ | 検知した罫線を内部的に延長する処理を行います。 値が0になっている場合は、延長処理が行われません。 |
| 25 | 矩形の丸い角を除去する閾値 | 半径が指定した値(ピクセル)未満の丸い角を除去する処理を行います。 値が0になっている場合は除去されません。 |
| 26 | 丸い角の除去範囲を拡張する長さ | 丸い角を除去する際に、指定した値(ピクセル)分の除去範囲を拡大します。 「矩形の丸い角を除去する閾値」の値が0、もしくは本機能の値が0になっている場合は、動作しません。 |
| 27 | ドット背景除去を行う | ドット背景除去を行います。 チェックあり:ドット背景の除去を行う チェックなし:ドット背景除去を行わずに処理する |
| 28 | ドットサイズ | 「ドット背景除去を行う」が有効であるとき、ドット背景除去時に削除するドットのサイズ(ピクセル)を指定します。 指定した値よりも縦横の大きさが小さいものが削除対象です。 |
| 29 | 小さい矩形を削除 | 小さい矩形の除去を行います。 チェックあり:小さい矩形の除去を行う チェックなし:小さい矩形の除去は行わない |
| 30 | 除去する矩形の最小面積 | 「小さい矩形を削除除去」が有効であるとき、除去する矩形の最小面積を指定します。 |
| 31 | 除去する矩形の最大面積 | 「小さい矩形を削除除去」が有効であるとき、除去する矩形の最大面積を指定します。 |
| 32 | 斜め線を除去 | チェックあり:矩形内の斜めの線を除去する チェックなし:斜め線の除去は行わない |
7.2.3. ルール指定
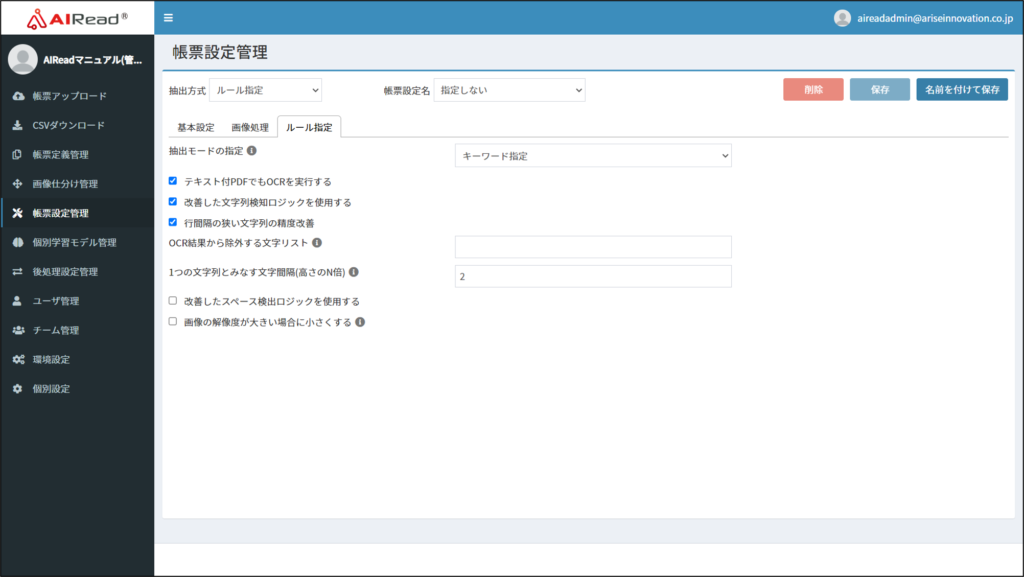
| No. | 項目名 | 説明 |
|---|---|---|
| 1 | 抽出モードの指定 | 抽出モードを選択します。 キーワード指定 キーワード指定(表検出付き) |
| 2 | テキスト付PDFでもOCRを実行する | チェックの有無でテキスト付PDFの読み取り方法を変更します。 チェックあり:テキスト付きPDFの場合でもOCRを実行する チェックなし:PDFのテキスト情報を使用して抽出する |
| 3 | 改善した文字列検知ロジックを使用する | チェックありの時、従来のOCRよりも文字列検知の改善した処理を行います。 チェックあり:改善した文字列検知を使用する チェックなし:従来の文字列検知を使用する ※処理時間がA4画像1枚当たり5秒/枚ほど増加します。 |
| 4 | 行間隔の狭い文字列の精度改善 | チェックありのとき、行間隔の狭い文字列に対して、従来よりも改善した文字列検知を行います。 チェックあり:行間隔の狭い文字列に対しての改善した文字列検知を行う チェックなし:従来の文字列検知のまま処理を行う |
| 5 | OCR結果から除外する文字リスト | OCRを行った後に、キーワードおよび抽出する値から除外する文字を指定します。 |
| 6 | 1つの文字列とみなす文字間隔(高さのN倍) | 1つの文字列とみなす文字の間隔を設定します。 値は、文字の大きさ(高さ)に対する倍率を設定します。 |
| 7 | 改善したスペース検出ロジックを使用する | チェックありの時、従来のOCRよりも改善したスペース検出を行います。 チェックあり:スペース検知の改善した検出を行う チェックなし:従来のスペース認識機能を使用する |
| 8 | 画像の解像度が大きい場合に小さくする | 画像の解像度が大きい場合(長辺が5000px以上)、画像を小さくしてからOCRを実行します。 |
7.3. 抽出方式:事前構築済みモデル
「請求書」「レシート」を選択した場合の抽出する項目や設定を指定します。
7.3.1. 項目名設定
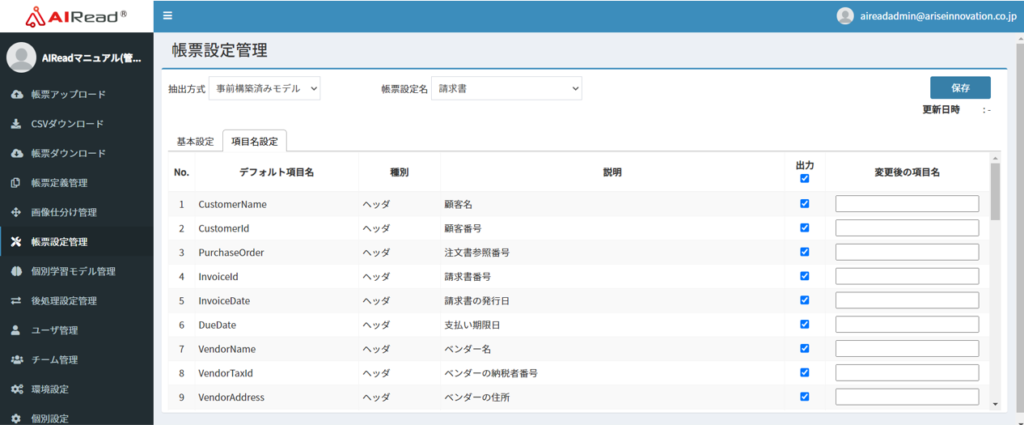
| No. | 項目名 | 説明 |
|---|---|---|
| 1 | デフォルト項目名 | デフォルトの項目名 |
| 2 | 種別 | 修正画面のタブ ヘッダ or 明細 or 税詳細 |
| 3 | 説明 | 項目の内容 |
| 4 | 出力 | チェックありの項目を帳票画像から抽出して出力(帳票に存在している場合のみ) チェックあり:出力する チェックなし:出力しない |
| 5 | 変更後の項目名 | 変更後の項目名 空の場合はデフォルトの項目名で出力 |
7.3.2. 基本設定
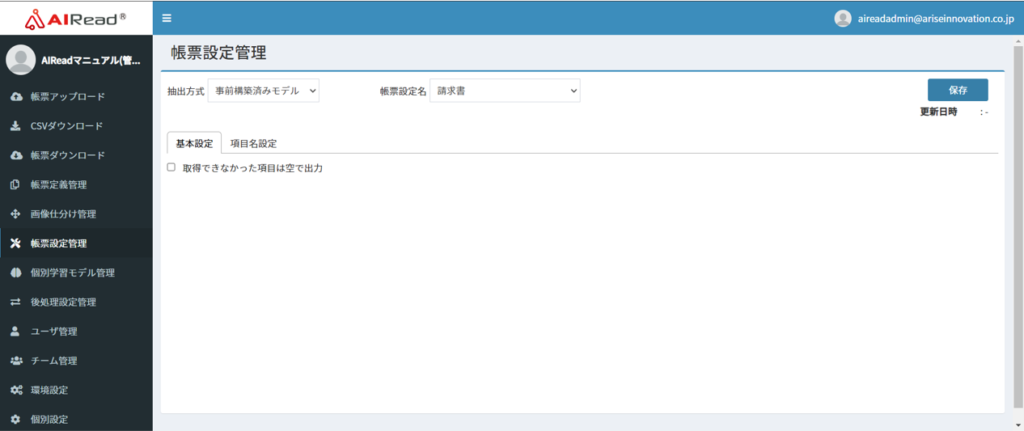
| No. | 項目名 | 説明 |
|---|---|---|
| 1 | 取得できなかった項目は空で出力 | チェックあり:取得できなかった項目を空で出力 チェックなし:取得できなかった項目は出力しない |
7.4. 抽出方式:事前構築済みモデル(Claude)
生成AI「Claudex.x」を使用する場合の抽出する項目や設定を指定します。
7.4.1. 項目名設定
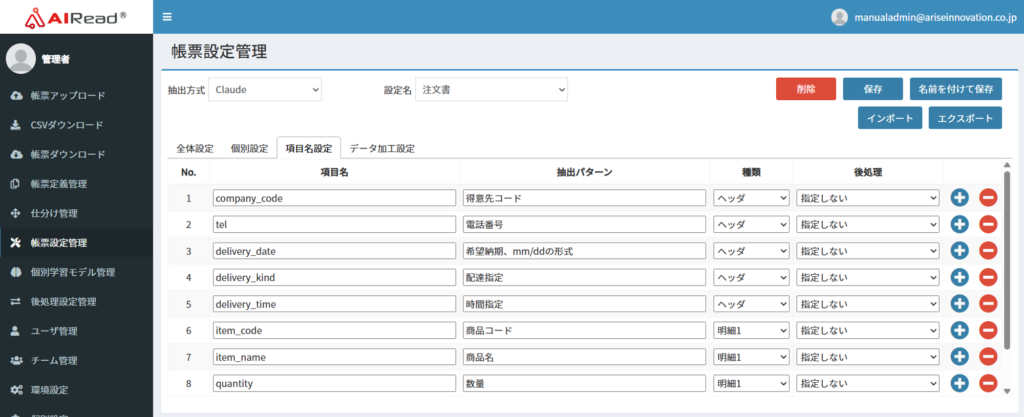
| No. | 項目名 | 説明 |
|---|---|---|
| 1 | 項目名 | 修正画面やCSVに出力する項目名を入力 |
| 2 | 抽出パターン | 抽出したい項目の名称、説明、編集例を入力 |
| 3 | 種類 | ヘッダ or 明細を指定 選択肢:ヘッダ、明細1、明細2、明細3 |
| 4 | 後処理 | 使用する後処理設定を指定 ※後処理設定はAIReadCloudClientで設定してアップロードする |
| 5 | インポート | エクスポートしたjson形式のファイルを指定してインポートする 同じ設定名の設定が存在する場合は上書きする |
| 6 | エクスポート | 表示している設定をjson形式のファイルでダウンロードする(設定名単位) |
7.4.2. 全体設定
Claudeで読み取るすべての帳票に対して適用される設定です。
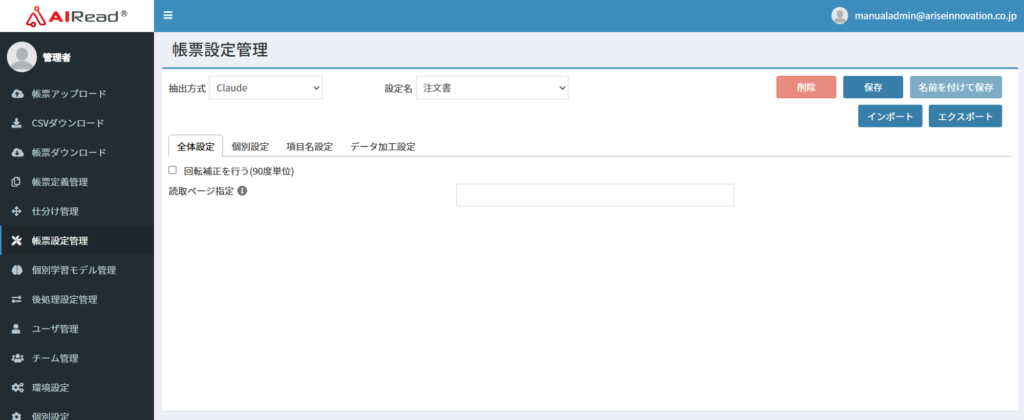
| No. | 項目名 | 説明 |
|---|---|---|
| 1 | 回転補正を行う(90度単位) | チェックあり:画像が回転している場合、正常な向きを自動で判定して補正する(処理時間が増える) チェックなし:回転補正をしない |
| 2 | 読取ページ設定 | カンマ区切りで複数指定 ハイフン区切りで範囲指定 空欄の場合はすべてのページを読み取る 例)2,4-5,7- :1,3,6ページ以外を読み取る |
7.4.3. 個別設定
設定名の単位で適用される設定です。
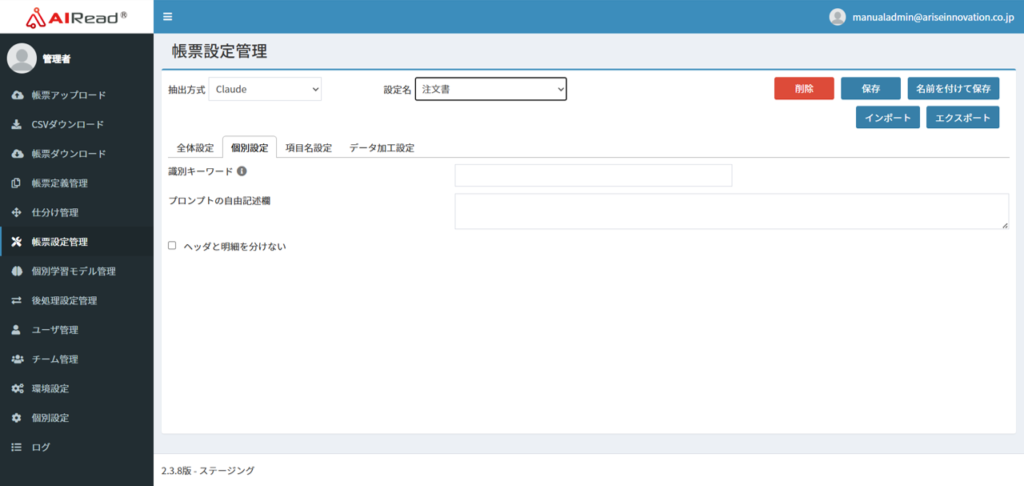
| No. | 項目名 | 説明 |
|---|---|---|
| 1 | 識別キーワード | 帳票を識別するキーワードを設定できます。 空欄の場合は設定名を識別キーワードとして利用します。 |
| 2 | プロンプトの自由記述欄 | 全体に対する指示を記述可能。 例)表が複数ある場合は統合して1つのファイルで出力してください。 |
| 3 | ヘッダと明細を分けない | チェックあり:ヘッダと明細を合わせて出力 チェックなし:ヘッダと明細を別々で出力 |
7.4.4. データ加工設定
明細項目について、条件に応じて以下の加工処理を設定できる機能です。
・項目の変換
・項目の移動/コピー
・行の削除
7.4.4.1 項目の変換
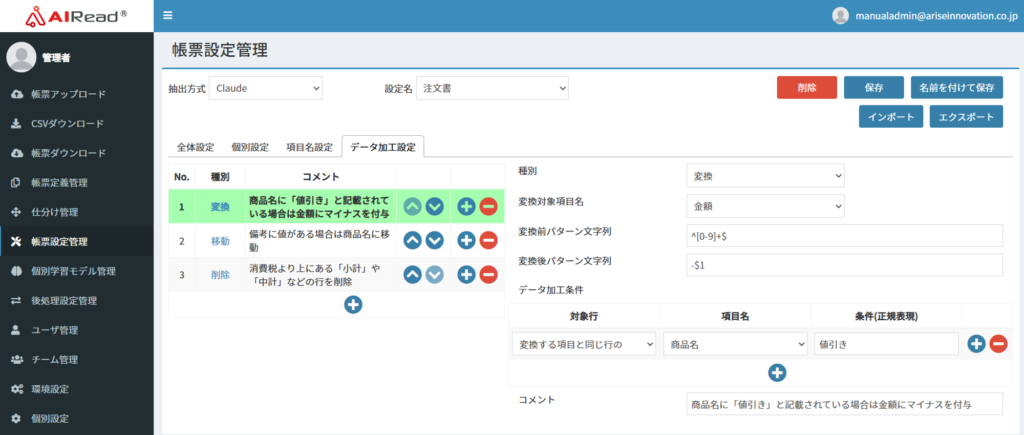
※画像は商品名に「値引き」と記載されている場合は金額にマイナスを付与する例
| No. | 項目名 | 説明 |
|---|---|---|
| 1 | 種別 | 変換 |
| 2 | 変換前パターン文字列 | 変換する文字を正規表現で記載する |
| 3 | 変換後パターン文字列 | 「変換前パターン文字列」にマッチした文字をこの文字列に変換する |
| 4 | データ加工条件 | 変換するための条件をAND条件で複数設定可能 条件に該当しない場合は変換が行われない |
| 5 | コメント | 説明を記載する |
7.4.4.2 項目の移動/コピー
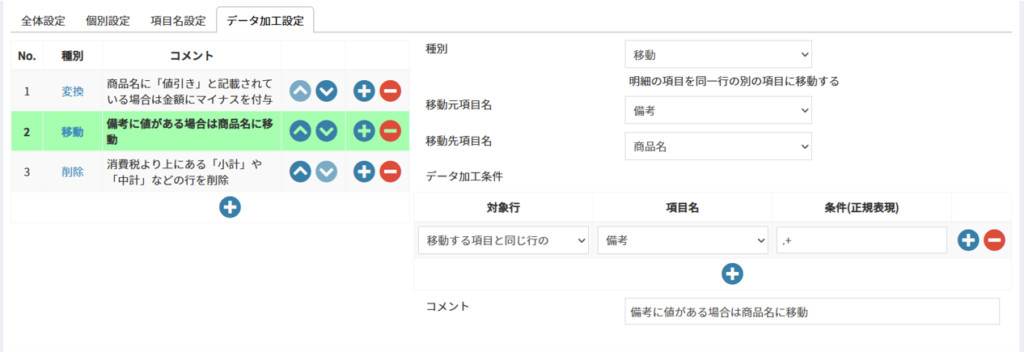
※画像は備考に値がある場合は商品名に移動する例
| No. | 項目名 | 説明 |
|---|---|---|
| 1 | 種別 | 移動/コピー |
| 2 | 移動(コピー)元項目名 | 値を移動(コピー)する元となる項目 |
| 3 | 移動(コピー)後項目名 | 値を移動(コピー)する先の項目 |
| 4 | データ加工条件 | 変換するための条件をAND条件で複数設定可能 条件に該当しない場合は変換が行われない |
| 5 | コメント | 説明を記載する |
7.4.4.3 行の削除
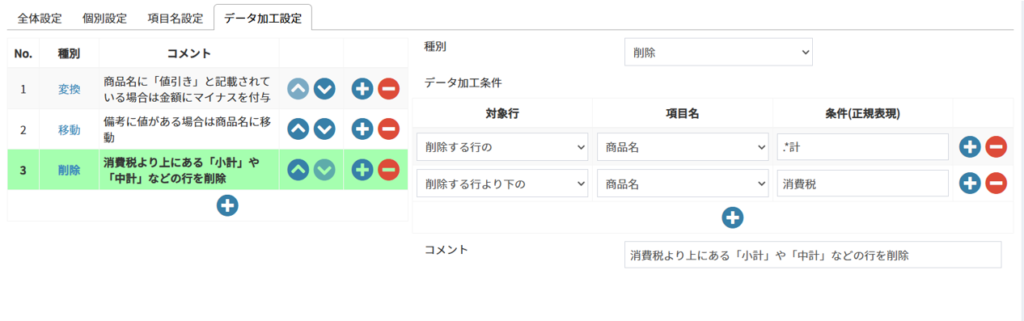
※画像は消費税より上にある「小計」や「中計」などの行を削除する例
| No. | 項目名 | 説明 |
|---|---|---|
| 1 | 種別 | 削除 |
| 2 | データ加工条件 | 変換するための条件をAND条件で複数設定可能 条件に該当しない場合は変換が行われない |
| 3 | コメント | 説明を記載する |
7.4.5. 設定例
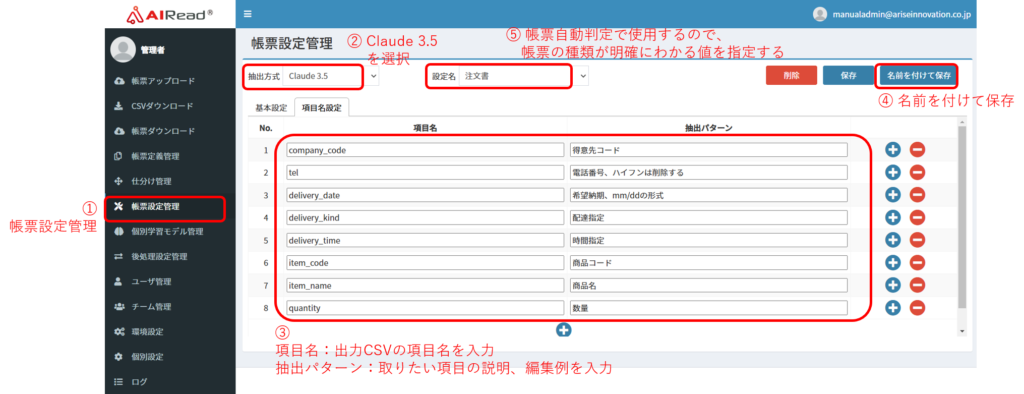
<読取結果(「ヘッダと明細を分けない」のチェックなし)>
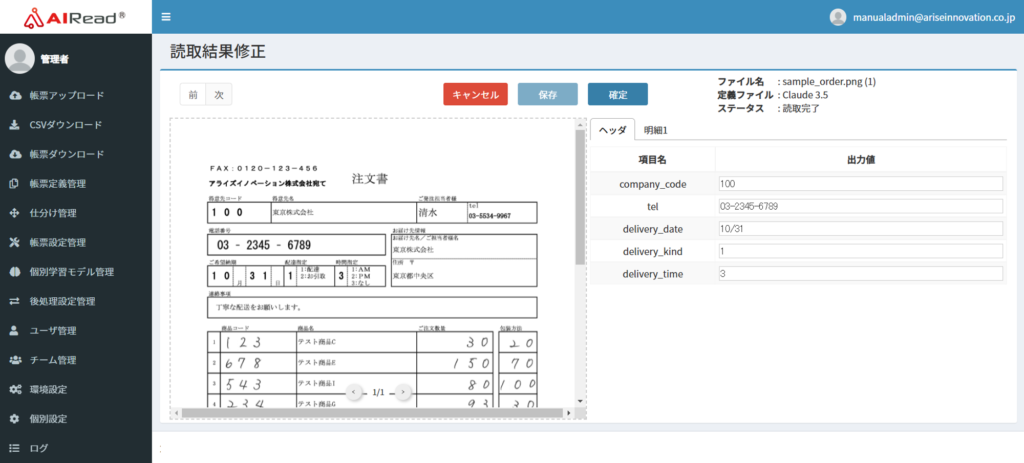
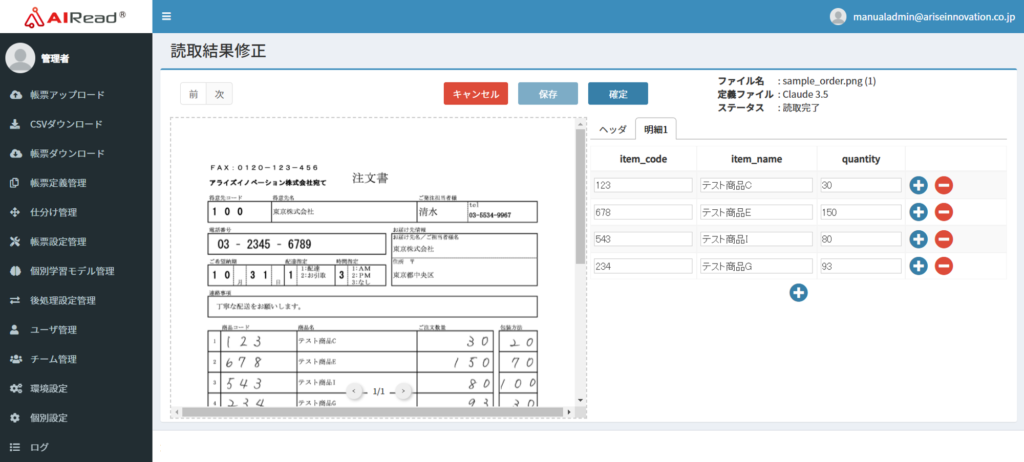
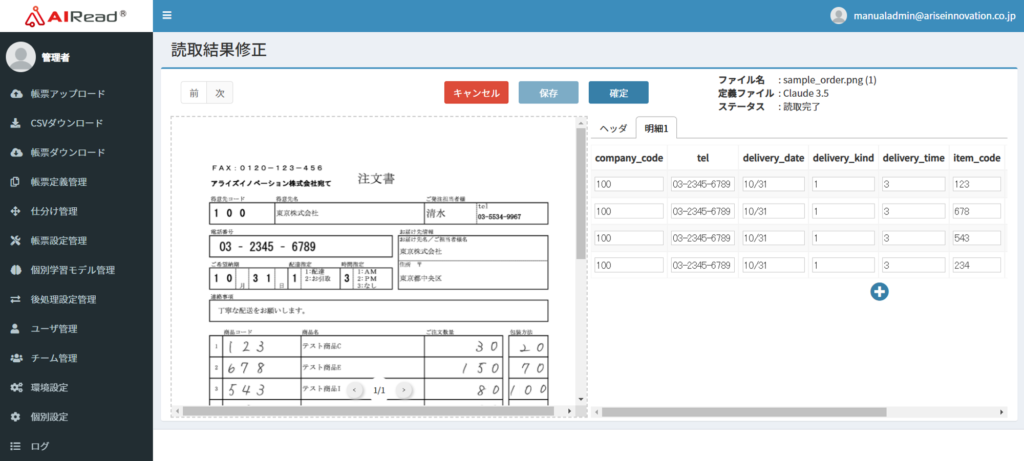
<読取結果(「ヘッダと明細を分けない」のチェックあり)>
<設定名で仕分け>
設定名に帳票を識別する文字列を入れることで、使用する設定を自動で判別して出力することができます。
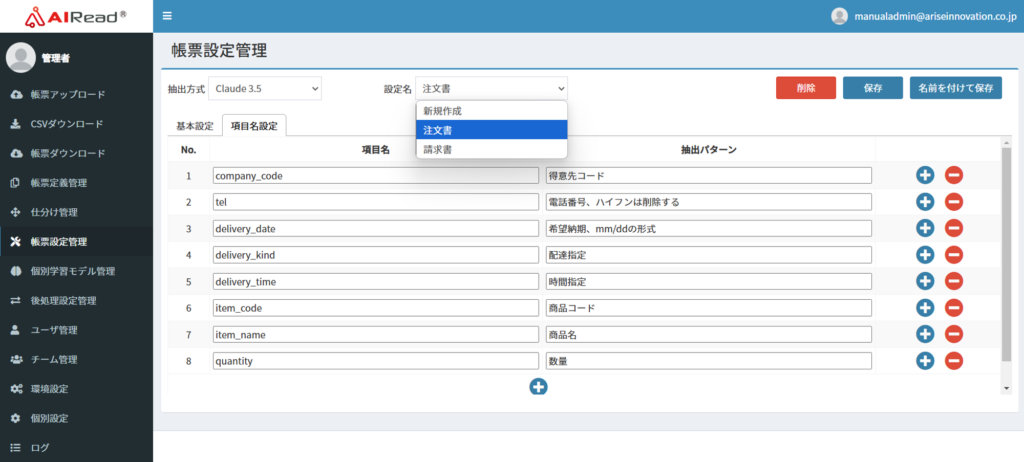
設定名を以下のように指定することで、会社単位で分けるといったことも可能です。
・○○株式会社の注文書
・××株式会社の注文書